.svg?fit=max&auto=format&n=vy0mukkT7J4oGoAc&q=85&s=309fd13aafaa2459ab88bae66ee69fdb)
.svg?fit=max&auto=format&n=vy0mukkT7J4oGoAc&q=85&s=d463f8e401c13f13ee15256db8c610dd)
1
履歴書をアップロード
最初のステップでは、プラットフォームがプロフィールを自動入力できるように履歴書をアップロードします。2種類の履歴書がサポートされています。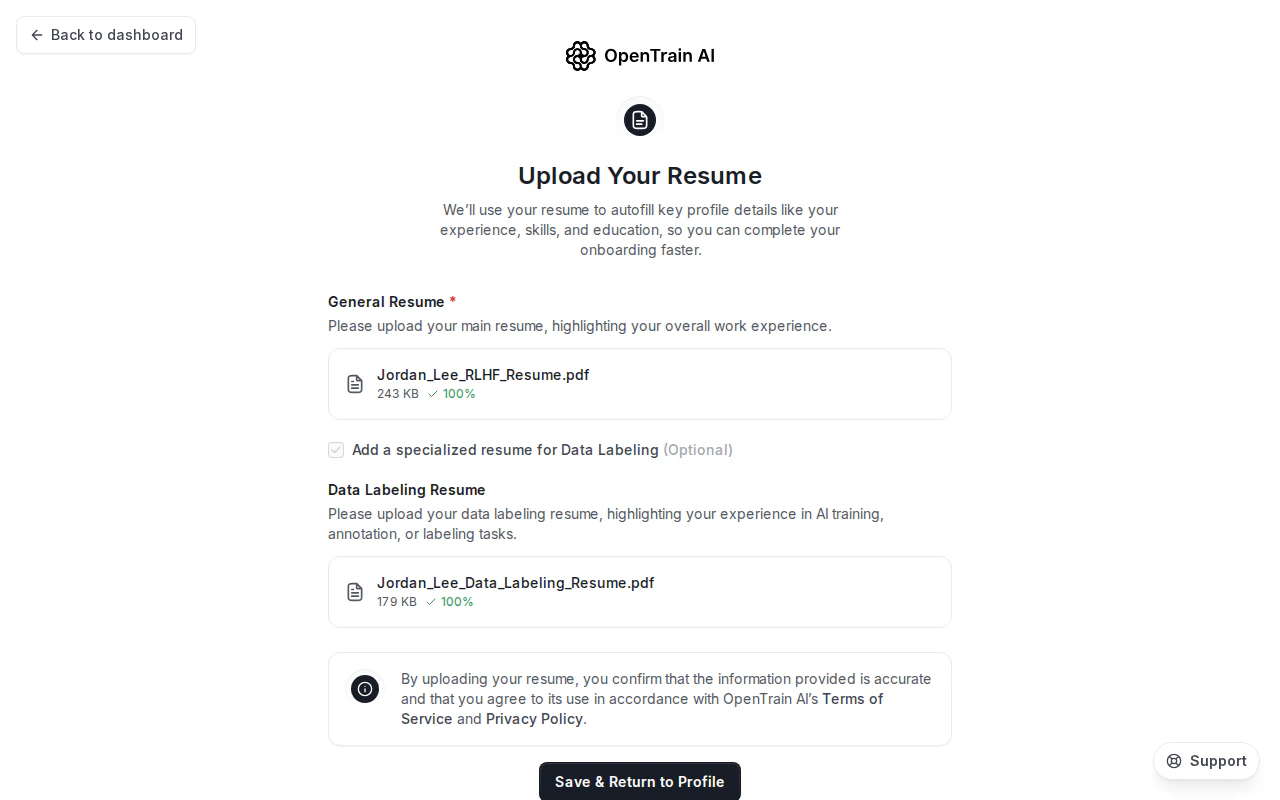
- 一般履歴書(必須) — 全体的な職務経歴と経歴
- データラベリング履歴書(オプション) — アノテーション、RLHF、またはラベリング固有の経験に焦点を当てた個別の履歴書
「履歴書のアップロード」ステップでは、一般的な履歴書と(オプションで)個別のデータラベリング履歴書が表示されます。各アップロードカードには、解析されたファイル名、サイズ、および処理完了後に100%検証バッジが表示されます。
後で2つ目の履歴書をアップロードした場合、プラットフォームは元の履歴書と照合して一貫性を確認します。大きな不一致があると、プロフィールのステータスに影響する場合があります。
2
基本情報を追加する
連絡先と所在地情報を入力します:
- 氏名
- 国 — 所在地に基づく求人マッチングと支払い対象の判定に使用されます
- 市区町村
- 電話番号
- LinkedIn URL — プラットフォームがURLを自動的に正規化します
3
ラベリング経験を追加する
これは求人マッチングで最も重要なセクションです。このステップは2ページあります。1ページ目で、全体的なAIトレーニング経験レベルを選択します — Entry Level(1年未満)、Intermediate(1~3年)、またはExpert(3年以上)。2ページ目では、短いプロフィール概要(150文字以上)を記入し、1件以上のラベリング経験エントリを追加します。各エントリについて、ウィザードは次の情報を取得します: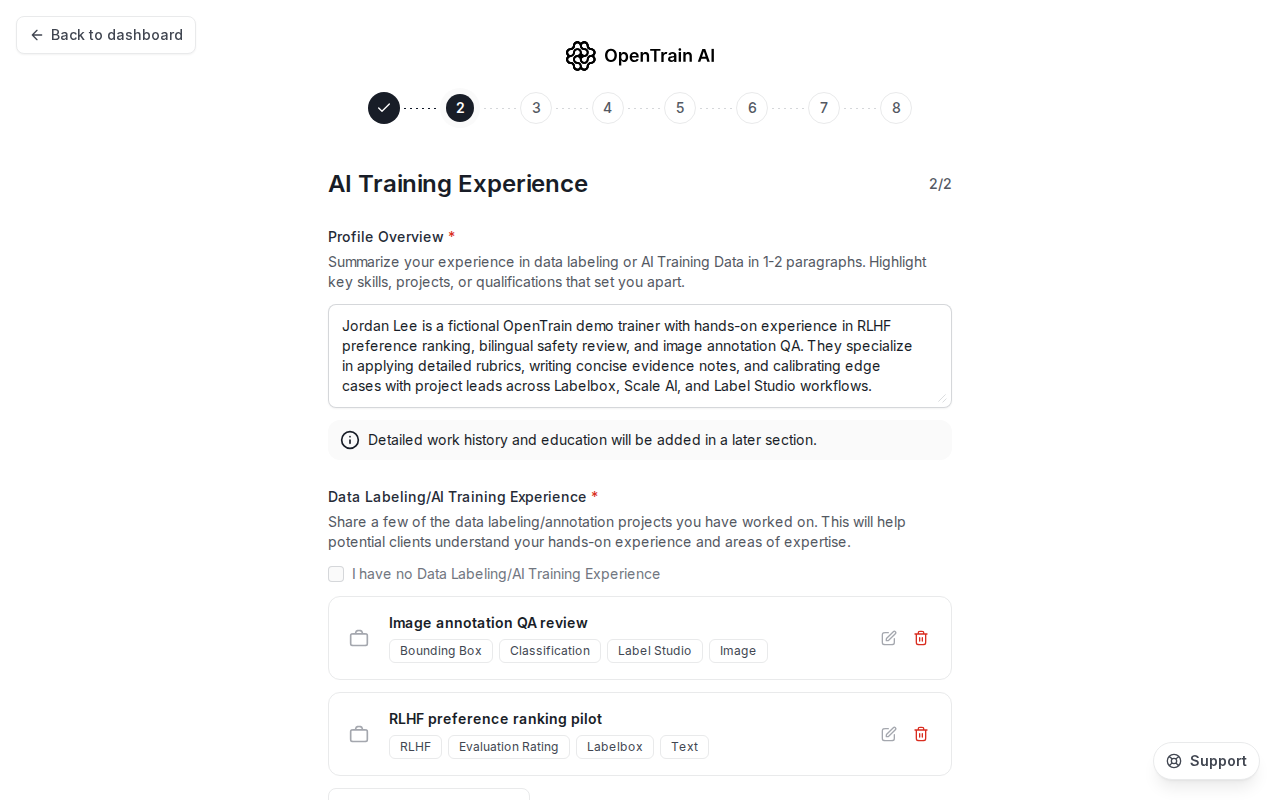
- 使用したプラットフォームまたはツール(例: Scale AI、Labelbox、CVAT、Appen、Remotasks、または社内ツール)
- 作業したデータタイプ — 画像、動画、テキスト、音声、ドキュメント、コード、3Dセンサー、医療、地理空間
- 実施したラベルタイプ — バウンディングボックス、ポリゴン、セグメンテーション、分類、NER、RLHF、ファインチューニング、SFT、レッドチーミング、文字起こし、評価/レーティングなど
- 期間と日付
AIトレーニングエクスペリエンスのステップ、ページ 2 には「プロフィール概要」とラベリング経験のエントリのリストが表示されます。各エントリは、プラットフォーム、データタイプ、および作業したラベルタイプを要約しています。
4
スキルを設定する
スキルセクションでは、マッチングエンジンが使用する3つの側面を記録します: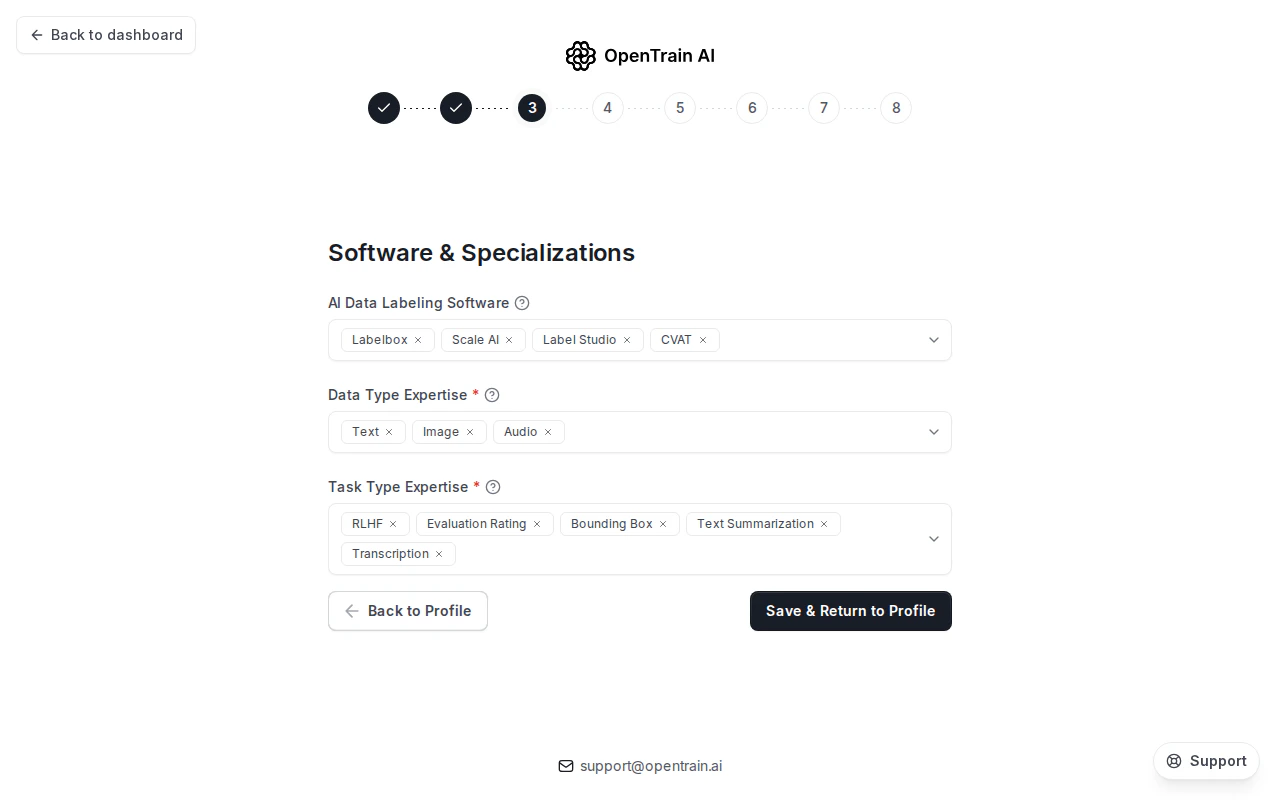
- AIデータラベリングソフトウェア — 実務経験のあるラベリングまたはアノテーションプラットフォームをすべて選択します(Scale AI、Labelbox、Label Studio、Encord、Roboflow、AWS SageMaker、CVAT など)
- データタイプの専門性 — アノテーションに対応できるデータの種類
- タスクタイプの専門性 — 実行できるアノテーションおよびトレーニングタスクの種類
ソフトウェアと専門分野のステップには、複数選択のチップ列が3つ表示されます。各 × アイコンをクリックすると、その選択が削除されます。
5
職務経歴を追加する
一般的な職務経歴(役割、会社、日付、説明)を追加します。履歴書パーサーは、アップロードされた履歴書からこれらを自動入力しますが、手動でエントリを追加、編集、削除することもできます。このセクションはラベリング経験とは別で、あなたの経歴に含まれるAIトレーニング以外の役割を扱います。
6
学歴を追加
学歴(学校、学位、専攻分野、卒業年)を追加します。履歴書パーサーでもこれらは自動入力されます。
7
料金と稼働可能時間を設定する
時給と週あたりの稼働可能時間を設定します。稼働可能時間の選択肢は次のとおりです。
- 週20時間未満
- 週20時間以上
- まだわかりません
- Entry Level — AIトレーニング経験が1年未満
- Intermediate — 1〜3年
- Expert — データラベリングまたはアノテーション経験が3年以上
8
公開プロフィールを設定する
ウィザードの最後のパーソナライズ手順では、3つのフィールドを入力します。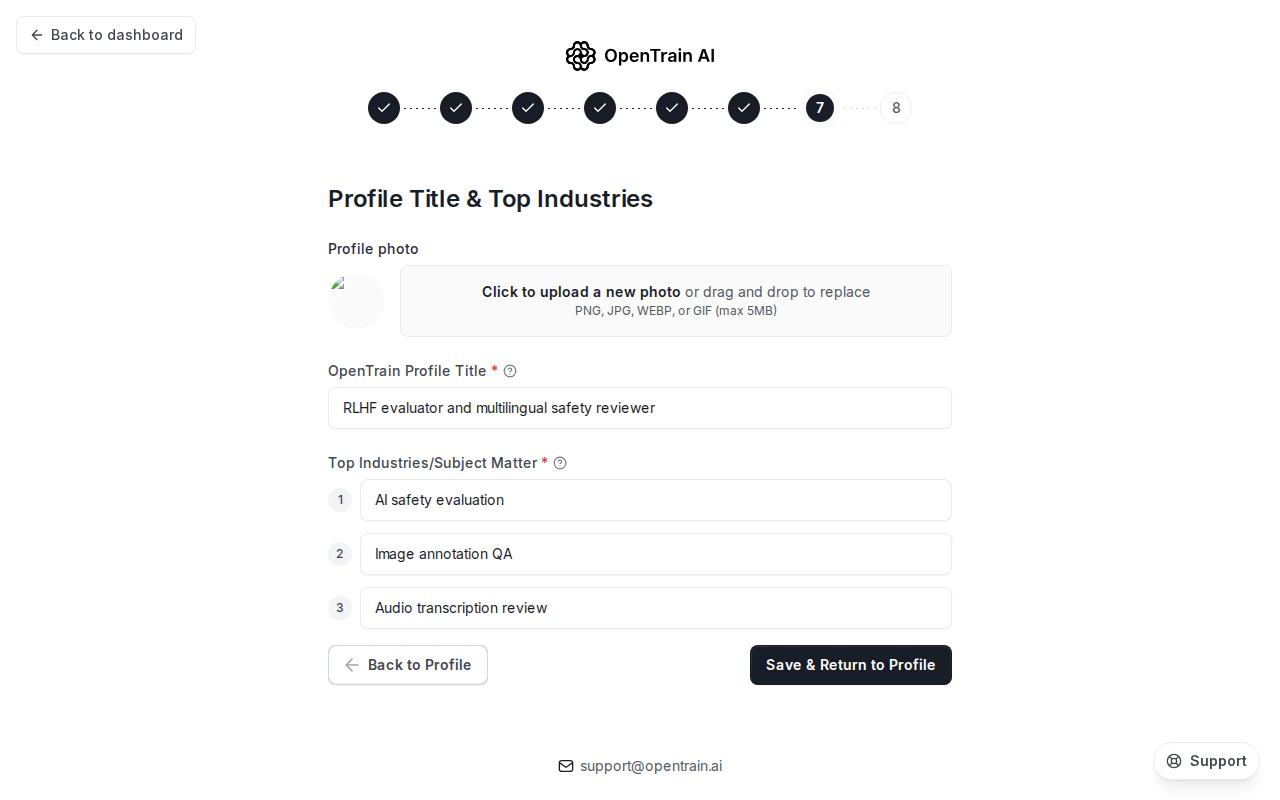
- プロフィール写真 — プロフィールカードと提案に表示する写真をアップロードします(PNG、JPG、WEBP、またはGIF、最大5 MB)
- プロフィールタイトル — 公開プロフィールに表示される短い見出しです。例: “RLHF evaluator and multilingual safety reviewer”
- 主な業界/専門分野 — あなたの専門性を最もよく表す分野を最大3つまで順位付けします(例: AI安全性評価、画像アノテーションQA、音声文字起こしレビュー)
ウィザード手順7 — プロフィールタイトルと主な業界。プロフィール写真のアップロード領域が上部にあり、その下にプロフィールタイトルフィールドと、順位付けされた3つの業界スロットがあります。
9
確認して送信
最後のステップでは、入力した内容の概要が表示されます。送信する前に各セクションを確認し、修正が必要な箇所があれば戻って修正してください。プロフィールを送信すると、マッチングプールに追加され、求人への応募を開始できます。
プロフィールの公開設定
プロフィールの公開設定と利用可能状況の設定は、オンボーディングウィザードではなく、設定 → プロフィールにあります。AIトレーナーダッシュボードからいつでも更新できます。- 公開範囲 — プロフィールを誰が見ることができるかを制御します:公開、OpenTrainユーザーのみ、または非公開
- 利用可能状況 — 新しい仕事に対応可能かどうかを雇用主に示します(週20時間未満、週20時間以上、またはまだ不明)
- 検索エンジンの公開 — 有効にすると、Googleなどの検索エンジンが公開プロフィールページをインデックスできるようになります
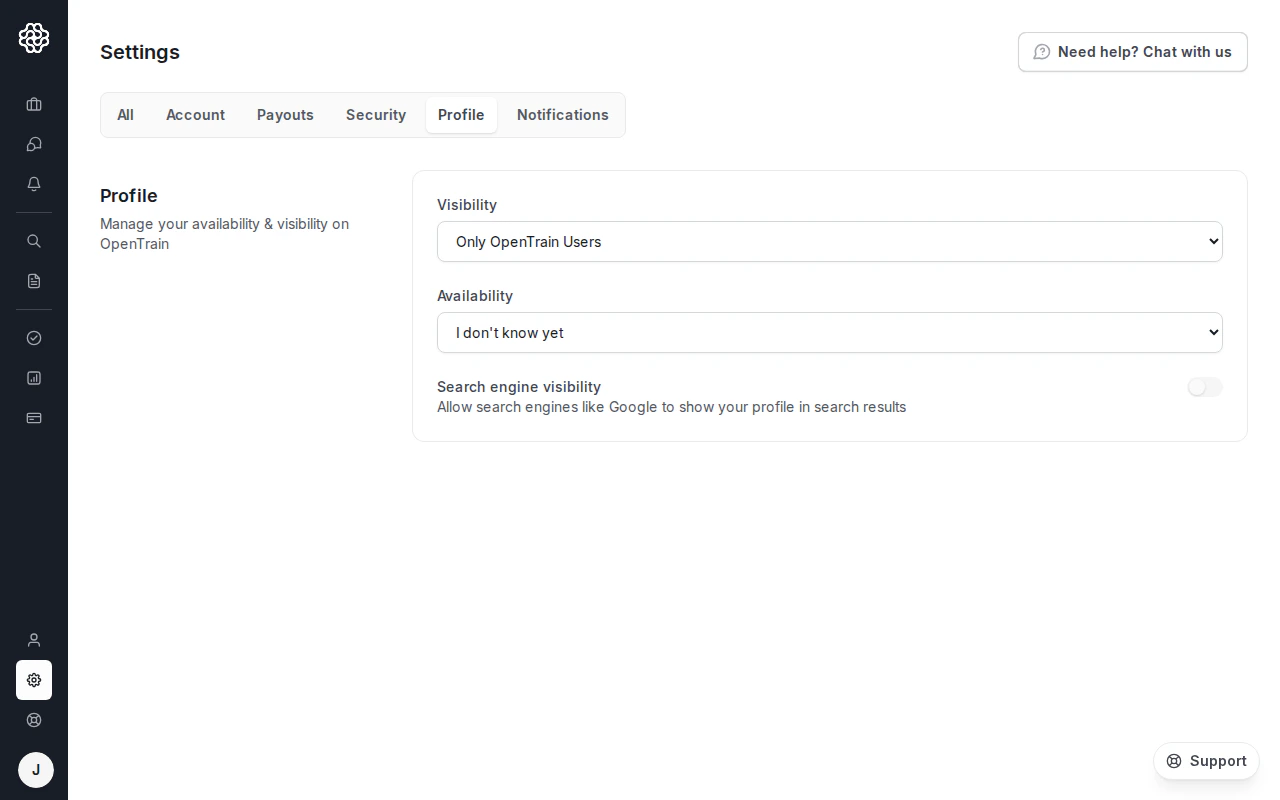
設定の「プロフィール」タブ — 公開範囲ドロップダウン、利用可能状況、検索エンジンのインデックス設定トグル。