評価データの問題としてのAIレッドチーミング

AIレッドチーミングは、敵対的な調査結果が再現可能な評価データ(脅威モデル、ルーブリック、裁定、漏洩制御、ルーティングの決定など)となったときに有用となります。
AIにおけるレッドチーミングとは、実際には何を指すのでしょうか?
すでにLLM評価を実施している場合、有益な答えは「モデルのジェイルブレイクを試みること」ではありません。有益な答えとは、証拠を生み出す構造化された敵対的発見です。AIレッドチーミングが重要となるのは、それがより優れた評価データ、拒否テスト、有害性の評価基準、およびリリース判断の設計に役立つ場合です。単なるバイラルプロンプトの展示会になってしまうと、その重要性は低下します。[1]
この区別が重要なのは、この分野では関連する用語が曖昧に使われているためです。従来のサイバーレッドチーミングは、企業のセキュリティ体制に対する敵対的エミュレーションです。AIレッドチーミングは、多くの場合開発者と協力して、AIシステムの欠陥や脆弱性を見つけ出すための構造化された取り組みです。評価(eval)はより限定的で、システムに入力を与え、評価ロジックを適用し、関心のあるタスクを実行できたかどうかを測定します。安全性テストやデプロイ前のTEVVは、レッドチーミング、フィールドテスト、パブリックフィードバック、および正式な評価を含む、より広範な概念です。[1]
AIレッドチーミングとサイバーレッドチーミング、および標準的な評価の違い。
| 実践 | 分析単位 | 目標 | 典型的な出力 | 避けるべき誤った推論 |
|---|---|---|---|---|
| サイバーレッドチーム | 組織、ネットワーク、製品、またはセキュリティプログラム。 | セキュリティ体制に対する敵対者を模倣する。 | 攻撃経路、エクスプロイトのナラティブ、修正リスト。 | サイバー演習は自動的にAI評価になるわけではない。 |
| AIレッドチーミング | AIモデル、アプリケーション、スキャフォールド、またはデプロイメントサーフェス。 | 欠陥、脆弱性、有害な挙動を発見する。 | 調査結果、プロンプト、トランスクリプト、重大度に関するメモ。 | バイラルなジェイルブレイクは、自動的に信頼できる測定値になるわけではありません。 |
| モデル評価 | 定義された入力、システムセットアップ、グレーダー、およびメトリクス。 | 指定されたハーネス下でターゲットとなる挙動が発生するかどうかを測定する。 | スコア、ラベル、信頼区間、エラースライス。 | 評価スコアは、そのハーネスがサポートできる範囲の主張しか裏付けられません。 |
| 安全性テストとTEVV | 証拠と保証活動のライフサイクル全体。 | テスト、現場の証拠、リスクしきい値、レビューを組み合わせる。 | リスクレジスター、受入証拠、モニタリング計画。 | レッドチームによる1回のラウンドだけで、システムが安全であると証明することはできません。 |
サイバーレッドチーム
- 分析単位
- 組織、ネットワーク、製品、またはセキュリティプログラム。
- 目標
- セキュリティ体制に対する敵対者を模倣する。
- 典型的な出力
- 攻撃経路、エクスプロイトのナラティブ、修正リスト。
- 避けるべき誤った推論
- サイバー演習は自動的にAI評価になるわけではない。
AIレッドチーミング
- 分析単位
- AIモデル、アプリケーション、スキャフォールド、またはデプロイメントサーフェス。
- 目標
- 欠陥、脆弱性、有害な挙動を発見する。
- 典型的な出力
- 調査結果、プロンプト、トランスクリプト、重大度に関するメモ。
- 避けるべき誤った推論
- バイラルなジェイルブレイクは、自動的に信頼できる測定値になるわけではありません。
モデル評価
- 分析単位
- 定義された入力、システムセットアップ、グレーダー、およびメトリクス。
- 目標
- 指定されたハーネス下でターゲットとなる挙動が発生するかどうかを測定する。
- 典型的な出力
- スコア、ラベル、信頼区間、エラースライス。
- 避けるべき誤った推論
- 評価スコアは、そのハーネスがサポートできる範囲の主張しか裏付けられません。
安全性テストとTEVV
- 分析単位
- 証拠と保証活動のライフサイクル全体。
- 目標
- テスト、現場の証拠、リスクしきい値、レビューを組み合わせる。
- 典型的な出力
- リスクレジスター、受入証拠、モニタリング計画。
- 避けるべき誤った推論
- レッドチームによる1回のラウンドだけで、システムが安全であると証明することはできません。
NISTおよびモデル評価ガイダンスから統合された定義。
そのため、デモ用のジェイルブレイクはガバナンスの単位としては脆弱です。NISTは、ジェイルブレイクやプロンプトエンジニアリングのテストでは、妥当性や信頼性を体系的に評価できない可能性があると警告しています。Microsoftは、レッドチーミングを体系的な測定の代替手段としてではなく、危害を露呈させ、リスクの表面を理解するための手法として位置づけています。AISIも評価者の立場から同様の指摘をしており、探索的テストは懸念の兆候を示すことはできるものの、より強力な主張には、より優れた引き出し(エリシテーション)、グレーディング、そして結果とリスクしきい値とのマッピングが必要であるとしています。[2]
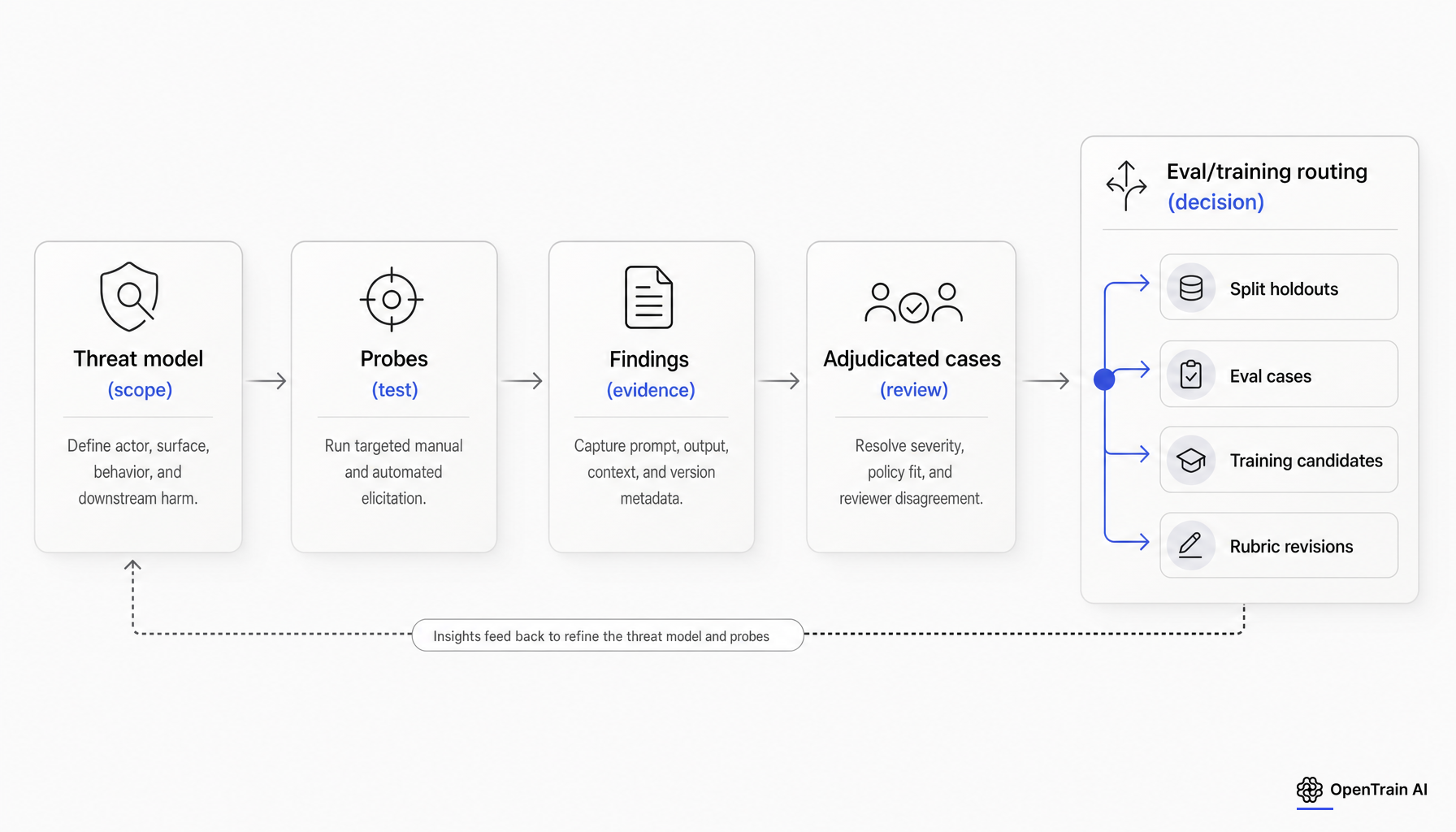
実用的な目標はシンプルです。発見した内容を、再現、ラベル付け、監査、ルーティングが可能なケースへと変換することです。
脅威モデルを優先し、ジェイルブレイクのギャラリーは最後に
レッドチームのプログラムが「モデルを壊してみて」という依頼から始まると、多くの場合、派手な事例は得られても測定結果は脆弱なものになります。順序を逆にしましょう。まずは、その証拠が何を裏付けるべきかという主張(能力の引き出し、セーフガードの堅牢性、あるいは共通設定下でのシステム間比較)を明確にします。その上で、その主張を意味のあるものにするためのハーネス、ツール、予算を定義してください。
OpenAIのサードパーティ評価ガイダンスはこの点について明確です。スコアは、その設定が何を裏付ける主張なのか、システムがどのように引き出されたのか、どのような妥当性チェックが行われたのかがレポートに記載されている場合にのみ解釈可能です。[3]
AIレッドチーミングの脅威モデルでは、アクター、ターゲットとなる動作、攻撃対象領域、そして下流への被害を特定する必要があります。AISIは、評価は明確なリスクモデルに準拠し、被害に至る関連経路を網羅すべきだと主張しています。Microsoftは、アクター、戦術、脆弱性、下流への影響を追跡する内部オントロジーについて説明しています。生の調査結果は、共通の構造なしでは推論するには複雑すぎるためです。[4]
ほとんどのチームにとって、「攻撃対象領域」はプロンプトボックスだけで完結すべきではありません。デプロイされたシステムに検索、ツール、長いコンテキスト、マルチモーダル入力、コネクタ、あるいはエージェントの足場(scaffolding)がある場合、それらの領域もスコープに含まれます。ハーネスはシステムができることを変えてしまいます。OpenAIは、周囲の足場がパフォーマンスを大きく変える可能性があることを強調しており、特にエージェントシステムでは顕著です。Microsoftも同様に、ベースモデルとアプリケーション層の両方をテストすることを推奨しており、可能な限り本番環境のUIを通じて行うのが理想的です。[3][5]
ここで「プロンプトのみの劇場」が始まります。簡素化されたチャットエンドポイントに対してユーザーテキストをテストし、その結果をデプロイされた製品に関する証拠として扱うことです。これでは、間接的なプロンプトインジェクション、安全でないツール使用、ステートフルな複数ターンのエスカレーション、検索依存の障害、環境固有の動作を見逃す可能性があります。問題は、プロンプトのみのテストが無意味だということではありません。問題は、それらがシステム全体を測定しているかのように扱うことです。
サンプリング、重大度、および裁定
サンプリングとは、レッドチーミングが評価設計へと変わるプロセスです。Googleは、製品ポリシー、ユースケース、障害モード、語彙の多様性、意味の多様性にわたり、多様かつ代表的な入力を推奨しています。Microsoftは、まずはオープンエンドなテストで有害性を発見し、その後、進化する有害性リストに基づいてガイド付きのラウンドへ移行することを推奨しています。実際には、サンプルは公開されている脱獄リストに即興のプロンプトをいくつか加えただけのものであるべきではありません。有害性カテゴリ、ユーザーの意図、インターフェース、言語、そして妥当な引き出し戦略にわたる計画的なスライスであるべきです。[6]
プログラムをスケールさせるには、重大度にも構造が必要です。NISTはリスクを「発生可能性」と「結果」の組み合わせとして定義しています。レッドチームのラベリングにおいて、これは出発点であり、完成された評価基準ではありません。ほとんどのチームには、有害性の種類、実行可能性、再現性、現実味、そして通常のセーフガードを適用してもその挙動が持続するかどうかといった次元も必要です。この評価基準はNISTのリスクフレームワークと評価の実践に基づいた編集上の統合であり、引用された規格そのものではありません。[2]
裁定は、チームが静かに失敗しやすい領域です。Googleは、人間が不穏なコンテンツを異なる方法でアノテーションする可能性があることを指摘し、評価者向けに明確なガイドラインやテンプレートを推奨しています。OpenAIは、明確な評価基準、スコアレベルの例、合格・不合格の閾値、そして複数のレビューアを使用する場合の合意形成を推奨しています。重大度が高い場合やポリシーの解釈が曖昧な場合は、人間同士の意見の相違を単なるアノテーターのノイズとしてではなく、測定システムに関するシグナルとして扱うべきです。[6][7]
有用な運用ルールとして、重大度が高い、ポリシーの解釈が曖昧、または専門的なドメインに関する発見事項については、単一レビューによるラベリングから専門家による裁定へとエスカレーションすることが挙げられます。モデルがポリシーに違反したかどうかについてレビューア間で意見が分かれる場合、そのケースは通常、ポストトレーニングを推進する前に、評価基準の改訂を促すものであるべきです。この推奨事項は統合的なものですが、評価基準の明確さ、キャリブレーション、および人間によるレビューに関する引用ガイダンスに従っています。
人間と自動化の作業を意図的に分ける
自動化は、作業が広範な場合、更新が必要な場合、および微弱なシグナルの検出において最も役立ちます。Anthropicのモデルによる評価手法の研究では、モデルが多くの関連する評価項目を迅速に生成するのに役立ち、その設定においてクラウドワーカー間でラベルに対する高い合意が得られることが示されました。AISIは、自動化された能力評価は懸念される能力領域の大部分をカバーできるほどスケーラブルであると主張しています。Googleも、既存のデータセットが不十分な場合は、シードとなる例から始めて合成的に拡張することを推奨しています。[8][4][6]
同じ情報源は、その限界も定義しています。AISIは、自動テストは現実世界の利用状況を反映するものではなく、それ単体で強力な結論を導くべきではないと述べています。Googleは、定義が曖昧な構成要素に対しては分類器の精度が低くなる可能性があると警告しています。OpenAIは、評価にはスコア以上の意味があると述べ、自動スコアリングを人間の判断と照らし合わせて調整することを推奨しています。[4][6][7]
自動化されたプローブは、3つの点で強力です。第一に、少人数のチームが作成できるよりも多くの語彙的および意味的なバリエーションを生成することで、カバレッジを向上させます。第二に、一度ケースが再利用可能な評価項目になれば、回帰テストを安価に実施できます。第三に、繰り返しサンプリングを行うことでシステムを大規模に攻撃できるため、試行回数が増えるほど成功率が上がる一部の脱獄(ジェイルブレイク)クラスにおいて重要となります。Anthropicのmany-shotに関する研究は、長いコンテキストが新たな失敗モードを生み出す一例です。[9]
現在のツールは、この役割分担を反映しています。Microsoft PyRITは、マルチモーダルシステムを調査し、構成可能なレッドチームのビルディングブロックを再利用するためのモデル非依存のフレームワークです。AISI Inspectは、マルチターン対話、エージェントの足場、モデルによる採点、および詳細なログをサポートしています。レッドチームの調査結果は、単なるメモではなく、分析可能な評価アーティファクトにする必要があるため、これらのツールは有用です。[10][11]
「ポリシーに違反したか?」だけでなく「ここで実際に何が重要か?」が問われる場合、人間は依然として不可欠です。Microsoftは、医学、サイバーセキュリティ、CBRN、異文化間の害、および心理社会的な害には、専門家による判断が必要であると明言しています。AISIも同様に、専門家によるレッドチーミングは自動テストよりも自然でオープンエンドなものであると説明しています。[12][4]
LLMの判定者にも同様の懐疑的な視点が必要です。OpenAIは、判定モデルが回答の順序や回答の長さによってバイアスを受ける可能性があるため、ペア比較や合格・不合格形式、明確なルーブリック、および人間によるラベルとの照合を推奨しています。LLMの判定者は測定機器のように扱い、調整を行い、ドリフトを確認し、定期的に監査してください。専門的な害や曖昧なポリシーの境界線について、彼らに最終的な権限を与えないでください。[7]
自動化が役立つ場所と、人間が依然として重要な場所。
| 手法 | 最適な用途 | 主な利点 | 主な死角 | 人間によるレビューが必要か? |
|---|---|---|---|---|
| 自動化されたプローブ | 既知の戦術を用いた広範かつ反復的な試行。 | カバレッジと更新頻度のスケーリング。 | 現実的な製品コンテキストやドメイン固有の有害性を見逃す可能性がある。 | はい、深刻なケースや曖昧なケースには有効です。 |
| モデル生成バリアント | シードとなる例を文言や意味の観点から拡張する。 | 語彙的および意味的に近いものを素早く発見する。 | 単純なバリエーションに過学習する可能性がある。 | はい、ラベルのキャリブレーションや新規性の確認には有効です。 |
| 分類器 | 大量の出力を事前スクリーニングする。 | 低コストなトリアージとモニタリング。 | 曖昧な構成に対する精度の低さ。 | はい、ポリシーや重大度の判断には有効です。 |
| LLM ジャッジ | 明確な評価基準を用いた合格・不合格またはペアワイズスコアリング。 | 調整済みであれば、高速で再利用可能なスコアリングが可能。 | 順序、長さ、スタイル、ドメインのバイアス。 | はい、定期的な人間による監査を行います。 |
| スクリプト化された回帰テストスイート | モデルやポリシーの変更後に既知のケースを再実行します。 | 安定したリプレイと差分比較。 | 過去の失敗モードを測定します。 | はい、回帰のリスクが高い場合に行います。 |
| 人間のドメインエキスパート | 医学、セキュリティ、CBRN、文化的、法的、または心理社会的危害。 | 文脈と結果の判断。 | 評価基準がない場合の処理能力の制限と意見の不一致。 | それらがレビューの経路となります。 |
自動化されたプローブ
- 最適な用途
- 既知の戦術を用いた広範かつ反復的な試行。
- 主な利点
- カバレッジと更新頻度のスケーリング。
- 主な死角
- 現実的な製品コンテキストやドメイン固有の有害性を見逃す可能性がある。
- 人間によるレビューが必要か?
- はい、深刻なケースや曖昧なケースには有効です。
モデル生成バリアント
- 最適な用途
- シードとなる例を文言や意味の観点から拡張する。
- 主な利点
- 語彙的および意味的に近いものを素早く発見する。
- 主な死角
- 単純なバリエーションに過学習する可能性がある。
- 人間によるレビューが必要か?
- はい、ラベルのキャリブレーションや新規性の確認には有効です。
分類器
- 最適な用途
- 大量の出力を事前スクリーニングする。
- 主な利点
- 低コストなトリアージとモニタリング。
- 主な死角
- 曖昧な構成に対する精度の低さ。
- 人間によるレビューが必要か?
- はい、ポリシーや重大度の判断には有効です。
LLM ジャッジ
- 最適な用途
- 明確な評価基準を用いた合格・不合格またはペアワイズスコアリング。
- 主な利点
- 調整済みであれば、高速で再利用可能なスコアリングが可能。
- 主な死角
- 順序、長さ、スタイル、ドメインのバイアス。
- 人間によるレビューが必要か?
- はい、定期的な人間による監査を行います。
スクリプト化された回帰テストスイート
- 最適な用途
- モデルやポリシーの変更後に既知のケースを再実行します。
- 主な利点
- 安定したリプレイと差分比較。
- 主な死角
- 過去の失敗モードを測定します。
- 人間によるレビューが必要か?
- はい、回帰のリスクが高い場合に行います。
人間のドメインエキスパート
- 最適な用途
- 医学、セキュリティ、CBRN、文化的、法的、または心理社会的危害。
- 主な利点
- 文脈と結果の判断。
- 主な死角
- 評価基準がない場合の処理能力の制限と意見の不一致。
- 人間によるレビューが必要か?
- それらがレビューの経路となります。
AISIの階層化、Googleの敵対的テスト、OpenAIの評価手法、Anthropicのモデルによる評価、およびMicrosoftのレッドチーミングの教訓に基づいています。
優れた運用の切り分けはシンプルです。自動化によって攻撃候補の生成、シードセットの拡張、明らかなケースの事前ラベル付け、重複のクラスタリング、回帰テストの再実行を行います。人間は、有害性のリスト定義、不確実または深刻なケースのレビュー、判定品質の監査、そしてシステム障害が製品やモデルにとって何を意味するのかの解釈を行います。この分担は、上記のソースに基づいた統合的なアプローチです。
調査結果を逸話ではなくデータオブジェクトとして扱う
レッドチームの出力を再利用可能な評価データにする必要がある場合、プロンプトと最終回答以上の情報を記録してください。Microsoftは、少なくとも発生日、一意の識別子、入力プロンプト、出力の詳細を記録することを推奨しています。Googleは、出力を障害モードと有害性に分類してアノテーションすることを推奨しています。Inspectのログモデルは、より成熟した表現で何を保持できるかを示しています。それは、入力、サンプルメタデータ、スコア、エラー、メッセージ、および複数の粒度レベルでのイベントトレースです。[5][6][11]
実務チームにとって、最小限の有用なスキーマは通常これよりも大きくなります。プロンプトと応答に加え、モデルバージョン、システムプロンプトのバージョンまたはハッシュ、ツール構成、検索コンテキストまたは参照、攻撃手法、ポリシーカテゴリ、拒否ステータス、レビュアーのラベル、重大度ラベル、根拠、判定ステータス、ケースクラスター、ルーティングステータスを保持してください。この正確なフィールドリストは統合的なものですが、構造化されたキャプチャ、メタデータ、スコアリングに関する現在のガイダンスを実用的に拡張したものです。
重複の処理は、ほとんどのチームが予想する以上に重要です。Googleは、敵対的データセットを生成する際、重複やノイズの多いマルチラベルの例を避けることを推奨しています。重複排除を行わないと、「主要な障害モード」はしばしば少数のバイラルな攻撃テンプレートに集約されてしまい、それが緩和策とトレーニングデータの両方にバイアスをかけてしまいます。標準的なケースとパラフレーズのクラスターという概念を維持し、生のカウント数と一意の攻撃ファミリーのカウント数の両方を報告してください。標準対クラスターという推奨事項は統合的なものですが、一意性と慎重な構成の必要性はGoogleのガイダンスから直接得られたものです。[6]
評価およびポストトレーニングループのための再利用可能なレッドチームケーススキーマ。
| フィールド | 重要性 | トレーニングに安全か? | ホールドアウトに安全か? | 備考 |
|---|---|---|---|---|
| ケースID | レビュー、再実行、および修正の追跡可能性を維持します。 | はい | はい | 安定したIDは、言い換えによるクラスタリング後も維持されるべきです。 |
| プロンプト/入力 | 引き出し(elicitation)アーティファクトを定義します。 | 場合による | はい | 正確なホールドアウトプロンプトは、後で学習データとして使用されるべきではありません。 |
| モデルの出力 | 観察された挙動を記録します。 | 時々 | はい | 拒否、部分的な完了、ツール出力を含めます。 |
| モデルバージョン | 変化するシステム間での誤った比較を防ぎます。 | はい | はい | モデル、チェックポイント、および関連するリリースチャネルを記録してください。 |
| システムプロンプトのハッシュ | 機密情報を公開することなく、指示と動作を関連付けます。 | はい | はい | プロンプトが機密性の高い場合は、ハッシュまたは管理された参照を使用してください。 |
| ツール/検索コンテキスト | デプロイされたハーネスが利用可能にしたものを表示します。 | 時々 | はい | RAG、ツール使用、ロングコンテキスト、エージェントテストに不可欠です。 |
| 攻撃手法 | カバレッジと重複排除をサポートします。 | はい | はい | 例として、直接的なジェイルブレイク、間接的なインジェクション、ロールプレイ、マルチターンでのエスカレーションなどが挙げられます。 |
| ポリシーカテゴリ | 評価基準と調査結果を関連付けます。 | はい | はい | 判定によって曖昧さが明らかになった場合は、カテゴリを修正してください。 |
| 拒否ステータス | 安全上のコンプライアンスと過度な拒否を分離します。 | はい | はい | すべての拒否を成功としてまとめないでください。 |
| レビュアーラベル | 人間または調整済みの判定者による決定を定義します。 | はい | はい | レビュアーのタイプとキャリブレーション状態を追跡します。 |
| 重大度 | 修正とリリースゲートの優先順位を決定します。 | はい | はい | 重大度の次元は統合的なものであり、普遍的な基準ではありません。 |
| 根拠 | 事後の監査を可能にします。 | はい | はい | 不透明なクラスラベルよりも、簡潔な根拠の方が優れています。 |
| 裁定ステータス | 単一レビューのラベルと解決済みのケースを分離します。 | はい | はい | 重大度の高いケースや異議のあるケースにはエスカレーションが必要です。 |
| クラスターID | 重複するプロンプトがレポートを占有することを防ぎます。 | はい | はい | 生のカウントと固有の攻撃ファミリーのカウントを個別に報告します。 |
| ルーティングステータス | トレーニングと測定の間のリークを防ぎます。 | はい(トレーニングにルーティングされた場合) | はい、ホールドアウトとしてブロックされている場合 | 考えられる状態には、トレーニング候補、評価ケース、ブロックされたホールドアウト、ルーブリックの修正、またはリリース時の証拠が含まれます。 |
ケースID
- 重要性
- レビュー、再実行、および修正の追跡可能性を維持します。
- トレーニングに安全か?
- はい
- ホールドアウトに安全か?
- はい
- 備考
- 安定したIDは、言い換えによるクラスタリング後も維持されるべきです。
プロンプト/入力
- 重要性
- 引き出し(elicitation)アーティファクトを定義します。
- トレーニングに安全か?
- 場合による
- ホールドアウトに安全か?
- はい
- 備考
- 正確なホールドアウトプロンプトは、後で学習データとして使用されるべきではありません。
モデルの出力
- 重要性
- 観察された挙動を記録します。
- トレーニングに安全か?
- 時々
- ホールドアウトに安全か?
- はい
- 備考
- 拒否、部分的な完了、ツール出力を含めます。
モデルバージョン
- 重要性
- 変化するシステム間での誤った比較を防ぎます。
- トレーニングに安全か?
- はい
- ホールドアウトに安全か?
- はい
- 備考
- モデル、チェックポイント、および関連するリリースチャネルを記録してください。
システムプロンプトのハッシュ
- 重要性
- 機密情報を公開することなく、指示と動作を関連付けます。
- トレーニングに安全か?
- はい
- ホールドアウトに安全か?
- はい
- 備考
- プロンプトが機密性の高い場合は、ハッシュまたは管理された参照を使用してください。
ツール/検索コンテキスト
- 重要性
- デプロイされたハーネスが利用可能にしたものを表示します。
- トレーニングに安全か?
- 時々
- ホールドアウトに安全か?
- はい
- 備考
- RAG、ツール使用、ロングコンテキスト、エージェントテストに不可欠です。
攻撃手法
- 重要性
- カバレッジと重複排除をサポートします。
- トレーニングに安全か?
- はい
- ホールドアウトに安全か?
- はい
- 備考
- 例として、直接的なジェイルブレイク、間接的なインジェクション、ロールプレイ、マルチターンでのエスカレーションなどが挙げられます。
ポリシーカテゴリ
- 重要性
- 評価基準と調査結果を関連付けます。
- トレーニングに安全か?
- はい
- ホールドアウトに安全か?
- はい
- 備考
- 判定によって曖昧さが明らかになった場合は、カテゴリを修正してください。
拒否ステータス
- 重要性
- 安全上のコンプライアンスと過度な拒否を分離します。
- トレーニングに安全か?
- はい
- ホールドアウトに安全か?
- はい
- 備考
- すべての拒否を成功としてまとめないでください。
レビュアーラベル
- 重要性
- 人間または調整済みの判定者による決定を定義します。
- トレーニングに安全か?
- はい
- ホールドアウトに安全か?
- はい
- 備考
- レビュアーのタイプとキャリブレーション状態を追跡します。
重大度
- 重要性
- 修正とリリースゲートの優先順位を決定します。
- トレーニングに安全か?
- はい
- ホールドアウトに安全か?
- はい
- 備考
- 重大度の次元は統合的なものであり、普遍的な基準ではありません。
根拠
- 重要性
- 事後の監査を可能にします。
- トレーニングに安全か?
- はい
- ホールドアウトに安全か?
- はい
- 備考
- 不透明なクラスラベルよりも、簡潔な根拠の方が優れています。
裁定ステータス
- 重要性
- 単一レビューのラベルと解決済みのケースを分離します。
- トレーニングに安全か?
- はい
- ホールドアウトに安全か?
- はい
- 備考
- 重大度の高いケースや異議のあるケースにはエスカレーションが必要です。
クラスターID
- 重要性
- 重複するプロンプトがレポートを占有することを防ぎます。
- トレーニングに安全か?
- はい
- ホールドアウトに安全か?
- はい
- 備考
- 生のカウントと固有の攻撃ファミリーのカウントを個別に報告します。
ルーティングステータス
- 重要性
- トレーニングと測定の間のリークを防ぎます。
- トレーニングに安全か?
- はい(トレーニングにルーティングされた場合)
- ホールドアウトに安全か?
- はい、ホールドアウトとしてブロックされている場合
- 備考
- 考えられる状態には、トレーニング候補、評価ケース、ブロックされたホールドアウト、ルーブリックの修正、またはリリース時の証拠が含まれます。
フィールドリストはツールドキュメントと運用ガイダンスを組み合わせたもので、トレーニング/ホールドアウトのルーティングは編集上の統合によるものです。
トレーニングを行う前に、各調査結果の扱いを決定する
これは運用の核心となる問いであり、最初のポストトレーニング会議の前にその回答を文書化しておくべきです。
レッドチームのケースは、少なくとも5つの異なるものになり得ます。トレーニング例、再利用可能な評価ケース、ブロックされたホールドアウト、ポリシーやルーブリックの修正、またはリリースゲートの証拠です。現在の主要な情報源は、これらを1つの標準的なワークフローにパッケージ化していないものの、個別のレーンが必要であることを裏付けています。OpenAIは、評価データを強化学習によるファインチューニングに漏洩させないよう警告し、定期的に更新される本番環境由来の評価について説明し、汚染や報酬ハッキングといった妥当性のリスクを強調しています。AISIも同様に、モデルのライフサイクル全体を通じた事前定義されたしきい値と反復的なテストの重要性を主張しています。[13][14][3][4]
ラベルが安定しており、失敗が現実的な使用例を代表するものであり、ポリシーの境界が明確で、かつ将来の測定用に予約されていない場合、そのケースは妥当なトレーニング候補となります。Anthropicの初期のレッドチーミング作業では、レッドチームのデータを安全性向上手法に使用することで、研究対象となった攻撃コーパスに対する脆弱性が低減することが判明しました。そのため、チームはすべてをトレーニングに使いたいという誘惑に駆られます。しかし、漏洩管理が重要なのはまさにこのためです。もし同じケースが後に進捗の証拠として使用されると、測定結果が損なわれてしまうからです。[15]
ホールドアウトとして必要な場合、公開ベンチマークや将来的にベンチマークとなる可能性が高いものに類似している場合、ラベルに異論がある場合、またはエクスプロイトが特定のケースに特化しすぎていてトレーニングしてもモデルにパッチを記憶させるだけになる場合は、そのケースをトレーニングから除外してください。AnthropicのBrowseCompの汚染に関する注記は、公開された漏洩がいかに結果を誇張させるかを示しており、OpenAIのSWE-bench Verified分析もベンチマーク規模で同様の失敗パターンを示しています。どちらのケースでも教訓は同じです。同じ成果物をトレーニング資料と誠実な測定証拠の両方にすることはできないということです。[16][17]
実用的なルーティングルール:あるケースで新しい失敗モードが明らかになった場合、まずはそれをホールドアウトバケットにブロックしてください。ホールドアウトを更新し、新しいケースで修正を証明した後にのみ、その失敗パターンのバリアントをトレーニングに移行することを検討してください。このルールは統合的なものですが、プロバイダーや評価ソースからの現在のリークガイダンスを尊重しています。
安全性を保証するふりをしない、小規模チームの運用モデル
小規模なAIチームにとって、目標は「すべてをカバーする」ことではありません。モデルが変更された後でも信頼できるエビデンスを生み出すループを作成することが目標です。
まずは、デプロイに関連する具体的な脅威モデルを1つ、製品の狭い範囲を1つ、そして手動での発見ラウンドを1回行うことから始めましょう。可能であれば多様なテスターを起用してください。少なくとも、ドメインの害を理解している担当者と、システムインターフェースについて敵対的に考えられる担当者を1名ずつ含めてください。Microsoftは多様なテスターと、害や機能に対する明確な割り当てを推奨しています。Googleはシード例から始めて慎重に拡大することを推奨しています。OpenAIは、早期に評価を構築し、すべてをログに記録し、人間のラベルで自動化を調整することを推奨しています。[5][6][7]
次に、確信度の高い最初の発見結果を、ホールドアウトされた敵対的評価セットとして固定します。それらの正確なケースでファインチューニングを行わないでください。たとえグレーダーが人間による監査を伴う合格・不合格の判定であっても、それらを中心に単純な回帰実行を構築します。それが機能したら、トレーニング候補用の2つ目のレーンを追加し、分割を明確に保ちます。OpenAIの評価ガイダンスでは、ホールドアウトデータ、非重複、およびポストトレーニングループ用の個別のトレーニングセットの重要性が繰り返し強調されています。[13][7]
その後、自動化が努力に見合うものとなります。モデルが生成した拡張、分類器、またはLLMジャッジを使用してカバレッジを拡大し、レビューコストを削減しますが、それは正しいラベルの意味が確立されている領域でのみ行ってください。AISIの階層型アプローチは有用なテンプレートです。まずは軽量な自動テストで懸念事項を迅速に見つけ、シグナルが重要な場合にのみ、特注の引き出し(elicitation)や専門家によるレビューにエスカレーションしてください。[4]
これらによってシステムが安全であると証明されるわけではありません。それは誤った約束です。優れたレッドチームループは、リプレイ可能なケース、防御可能なラベル、トレーニングに使用していないホールドアウト、そして緩和策がモデルを変更したのか、単にデモプロンプトにパッチを当てただけなのかを判断するのに十分な構造を提供します。
OpenTrainは、チームがその作業のためにレッドチーム担当者、ドメインレビュー担当者、評価スペシャリストを採用するのを支援します。評価者のキャリブレーションにはLLMのジャッジ信頼性リファレンスを、自動化の境界についてはRLAIF対RLHFガイドを、測定ターゲットの設計にはPRM対ORMリファレンスを、レビューループの計画にはRLHFスコープ設定ガイドを使用してください。レビューループの人員配置がボトルネックとなっている場合は、求人を投稿してください。
ソース
- NIST用語集: レッドチーム; NIST用語集: 人工知能レッドチーミング; NIST AI RMF 生成AIプロファイル
- NIST AI RMF 生成AIプロファイル
- OpenAI: 信頼できる第三者評価の基盤
- AISI: フロンティアAIシステム評価からの初期の教訓
- Microsoft Learn: LLMのレッドチーミング計画
- Google: 生成AIの敵対的テスト
- OpenAI: 評価のベストプラクティス
- Anthropic: モデルが作成した評価を用いた言語モデルの挙動の発見
- Anthropic: Many-shot jailbreaking(多数ショットによるジェイルブレイク)
- PyRIT: 生成AIシステムにおけるセキュリティリスク特定とレッドチーミングのためのフレームワーク
- Inspect AI ドキュメント
- Microsoft Research: 100種類の生成AI製品のレッドチーミングから得られた教訓; Microsoft セキュリティブログの要約
- OpenAI クックブック: 評価駆動型のシステム設計
- OpenAI: 本番環境での評価
- Anthropic: 有害性を低減するための言語モデルのレッドチーミング
- Anthropic: Eval awareness and BrowseComp
- OpenAI: Why we no longer evaluate on SWE-bench Verified