LLM Judges Are Measurement Systems, Not Oracles

Evidence-based technical reference on when LLM judges are reliable enough for production evals and post-training, and how to calibrate, audit, and gate them.
LLM judges are usable in production, but only as measurement systems that are versioned, calibrated, and audited. The central tension is that the field’s most-cited success case, GPT-4 reaching over 80% agreement with human preferences on MT-Bench and Chatbot Arena, now sits beside newer evidence showing sharp transfer failures once the task mix, benchmark construction, metric, or judge family changes (MT-Bench and Chatbot Arena, Arena-Hard, JUDGE-BENCH, JudgeBench).
Those results are not contradictory. They describe what happens when a judge is treated as a portable truth source instead of a calibrated instrument.
Early agreement results were benchmark-local, not universal
The early positive results were real. MT-Bench and Chatbot Arena established that strong pairwise judges can approximate human preference judgments on broad chat-style comparisons. G-Eval showed that structured GPT-4 judging could outperform older automatic metrics on summarization while warning about evaluator bias toward LLM-generated text (G-Eval). Prometheus 2 later showed that open evaluator models can improve substantially as dedicated judge models with user-defined criteria (Prometheus 2).
That combination matters. It means the field did not prove that “an LLM judge works” in the abstract. It proved narrower claims: a judge can track a particular human preference distribution, on a particular benchmark family, under a particular prompting and aggregation scheme.
AlpacaEval makes the same point from the other direction. Its length-controlled win rate increased correlation with Chatbot Arena and reduced length gameability, but its maintainers still caution against using automatic evaluators alone for release decisions. A judge can be useful for iterative development while still being weak as a final gate.
Harder meta-evaluations broke the portability story
Arena-Hard made the portability problem concrete. It was designed from crowd-sourced live data to improve separability among strong instruction-tuned models, and the authors reported strong agreement to Chatbot Arena at low cost. In the same study, MT-Bench could still preserve rough ranking order while failing much harder on separability. That is exactly the metric mismatch that breaks release-gate reasoning: a benchmark can rank candidates and still fail to separate near-frontier systems well enough for shipping decisions.
JUDGE-BENCH broadened the problem across 20 NLP evaluation tasks and 11 judge models. The highest-valid-response models averaged modest chance-corrected agreement, with very large variance by dataset. GPT-4o could look strong on one slice and near-zero or negative on another. The same paper found that judges aligned better with non-expert annotations than expert annotations, and better with human-generated language than machine-generated text.
JudgeBench pushed even harder by moving away from stylistic or crowd-preference alignment and toward objective correctness in knowledge, reasoning, math, and coding. Its abstract reports that many strong judges, including GPT-4o, perform only slightly better than random guessing on harder response pairs. IF-RewardBench extends the critique into instruction-following evaluation by arguing that pairwise-only meta-evaluation is misaligned with listwise ranking workflows used in optimization (IF-RewardBench).
Benchmark snapshots show transfer limits
| Benchmark | Evaluation regime | Reliability implication |
|---|---|---|
| MT-Bench / Chatbot Arena | Pairwise chat preference judgments | Strong benchmark-local agreement does not imply universal transfer. |
| Arena-Hard | Harder separability from live arena data | Benchmark construction changes what agreement means. |
| JUDGE-BENCH | 20 NLP tasks and 11 judge models | Chance-corrected and rank metrics vary substantially by task. |
| JudgeBench | Objective correctness across reasoning domains | Correctness-heavy tasks expose weak transfer from preference-style judging. |
MT-Bench / Chatbot Arena
- Evaluation regime
- Pairwise chat preference judgments
- Reliability implication
- Strong benchmark-local agreement does not imply universal transfer.
Arena-Hard
- Evaluation regime
- Harder separability from live arena data
- Reliability implication
- Benchmark construction changes what agreement means.
JUDGE-BENCH
- Evaluation regime
- 20 NLP tasks and 11 judge models
- Reliability implication
- Chance-corrected and rank metrics vary substantially by task.
JudgeBench
- Evaluation regime
- Objective correctness across reasoning domains
- Reliability implication
- Correctness-heavy tasks expose weak transfer from preference-style judging.
OpenTrain synthesis from cited benchmark and meta-evaluation sources.
Chance-corrected reliability metrics
Percent agreement is a weak release argument by itself. If label balance is skewed, a judge can agree often while adding little information. For categorical evaluation, chance-corrected agreement belongs beside headline agreement.
Bias and judge-family effects create structured error
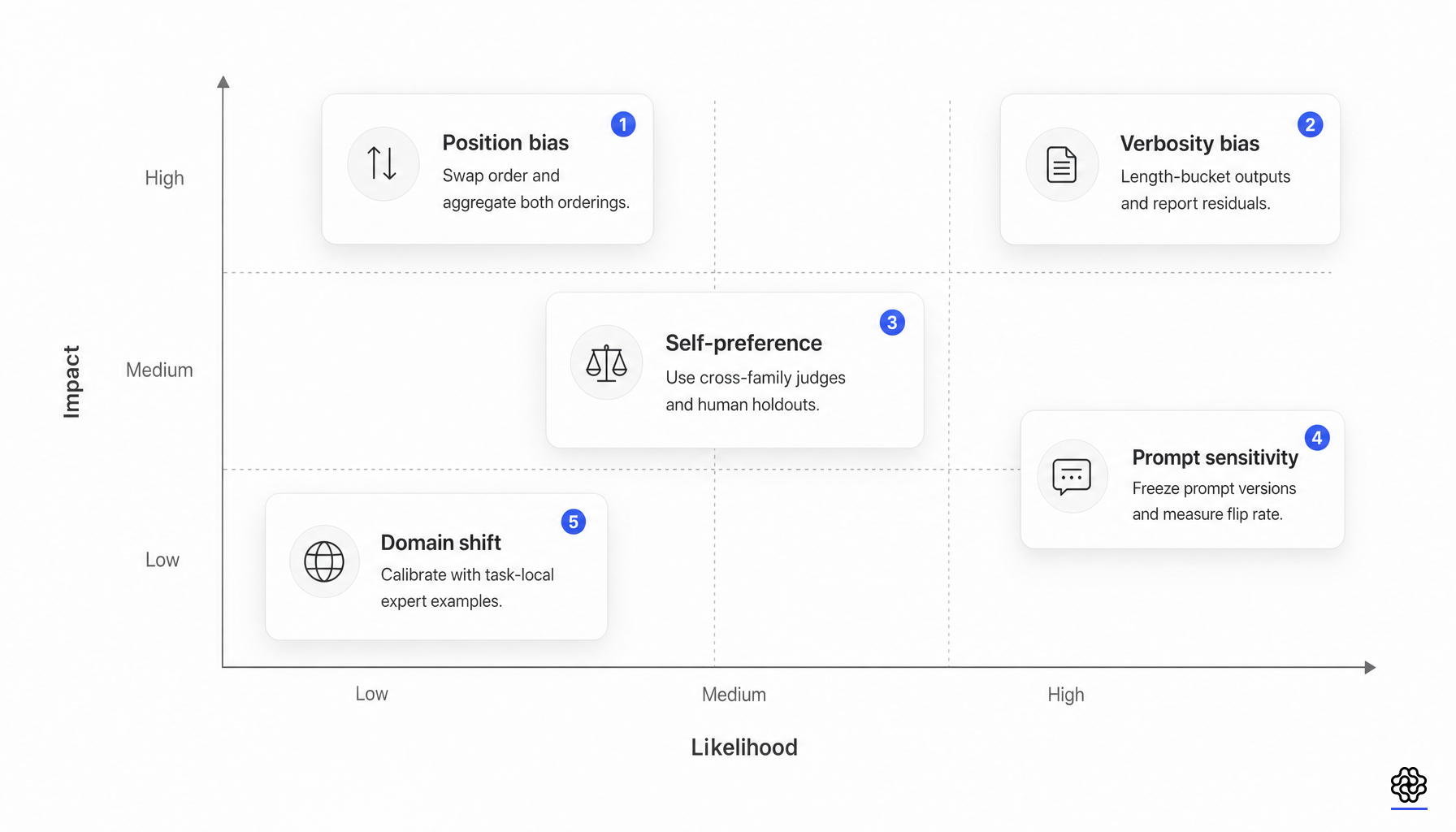
The field’s most important reliability update is that bias is no longer a side note. It is a measurable source of structured error.
Position-bias work has moved beyond anecdote. A systematic study across MTBench and DevBench introduced repetition stability, position consistency, and preference fairness, analyzed more than 100,000 evaluation instances, and found that position bias is not random chance (position bias study). Judge identity, task category, and answer quality gap all matter.
Self-preference is equally important because it couples evaluation to model family. One line of work showed that LLM evaluators can recognize and favor their own generations; a later study tied GPT-4 self-preference to familiarity and lower perplexity rather than simple vanity (self-recognition, self-preference). This matters whenever the judge, policy, and data generator come from the same family or share similar post-training style.
Reference design changes the failure mode again. “No Free Labels” found that a judge’s ability to answer a question is connected to its ability to grade responses to that question, and that a weaker judge with stronger human references can beat a stronger judge with synthetic references (No Free Labels). Ensemble findings point in the same direction: diverse judge panels can reduce single-family bias and cost less than a single large judge in some settings (Replacing Judges with Juries).
In post-training, reward quality is only as good as judge calibration
Once the judge moves from evaluation into training, measurement error becomes optimization error. RewardBench made the original case for direct reward-model evaluation through prompt, chosen, and rejected triples. RewardBench 2 updated that story with a harder benchmark built from mostly unseen human prompts, six domains, 1,865 prompts, completions from 20 models or humans, a best-of-4 scoring setup, and a ties subset intended to test calibration among equivalently valid answers (RewardBench 2, dataset card).
RewardBench 2 is useful because it resists a simplistic story about benchmark score transfer into training. The paper shows strong correlation with best-of-N sampling performance, but it also says RLHF PPO correlation is affected by context-specific factors. Accuracy-based reward benchmark scores are a prerequisite for strong RLHF training, but they are not sufficient.
Better judge signals can help when used carefully. Crowd comparative reasoning augments pairwise judging with additional crowd responses and shows gains across preference benchmarks, including downstream rejection-sampling improvements (Crowd Comparative Reasoning). The lesson is not that extra judge-time compute solves reliability. It is that richer judgment protocols can improve the measurement signal used for selection and filtering.
Official product documentation now reflects the same reality. OpenAI’s grader docs treat graders as first-class objects for evals and reinforcement fine-tuning, recommend testing graders against high-quality model and human examples, and define grader hacking as the case where a model scores highly on grader evals but poorly on expert human evaluations (OpenAI graders, reinforcement fine-tuning cookbook). The failure mode is straightforward: the team wires a judge into the loop before validating whether the score remains aligned once the policy starts optimizing against it.
Where judge signals enter post-training
| Workflow stage | Judge artifact | Minimum control |
|---|---|---|
| Eval-only regression testing | Versioned judge prompt over a calibration set | Track drift, slice deltas, and chance-corrected agreement. |
| Rejection sampling | Pairwise, listwise, or verifier score | Audit whether selection improves human-preferred outputs on target slices. |
| Reward-model benchmarking | Reward model or judge ensemble | Separate benchmark score from downstream PPO or best-of-N behavior. |
| RFT / RLHF grading | Rubric grader or reward signal | Run small-scale validation before scaling optimization. |
| Release gating | Calibrated judge score plus human audit | Require uncertainty bounds, disagreement limits, and slice checks. |
Eval-only regression testing
- Judge artifact
- Versioned judge prompt over a calibration set
- Minimum control
- Track drift, slice deltas, and chance-corrected agreement.
Rejection sampling
- Judge artifact
- Pairwise, listwise, or verifier score
- Minimum control
- Audit whether selection improves human-preferred outputs on target slices.
Reward-model benchmarking
- Judge artifact
- Reward model or judge ensemble
- Minimum control
- Separate benchmark score from downstream PPO or best-of-N behavior.
RFT / RLHF grading
- Judge artifact
- Rubric grader or reward signal
- Minimum control
- Run small-scale validation before scaling optimization.
Release gating
- Judge artifact
- Calibrated judge score plus human audit
- Minimum control
- Require uncertainty bounds, disagreement limits, and slice checks.
OpenTrain synthesis from RewardBench 2, OpenAI grader guidance, RLAIF literature, and recent rubric-based post-training work.
A production judge stack needs calibration, versioning, and human escalation
Public material from OpenAI and Anthropic suggests that frontier teams treat judges as components in layered measurement stacks, not as standalone release authorities. OpenAI exposes graders as part of eval and reinforcement fine-tuning workflows. Anthropic reports that a single LLM judge can be consistent for clear-answer components of a research system, while also stating that human testing remains essential because people catch hallucinations, system failures, and source-quality errors that automation misses (Anthropic engineering).
More recent calibration literature is converging on the same framing. SLMEval argues that several calibrated evaluators fail on real-world open-ended tasks and reports a production-use-case improvement using small amounts of human preference data plus entropy-based calibration (SLMEval). An IRT-based reliability paper separates intrinsic consistency, which asks whether the judge behaves stably under prompt variation, from human alignment, which asks whether that stable behavior is actually aligned with human quality assessments (IRT reliability).
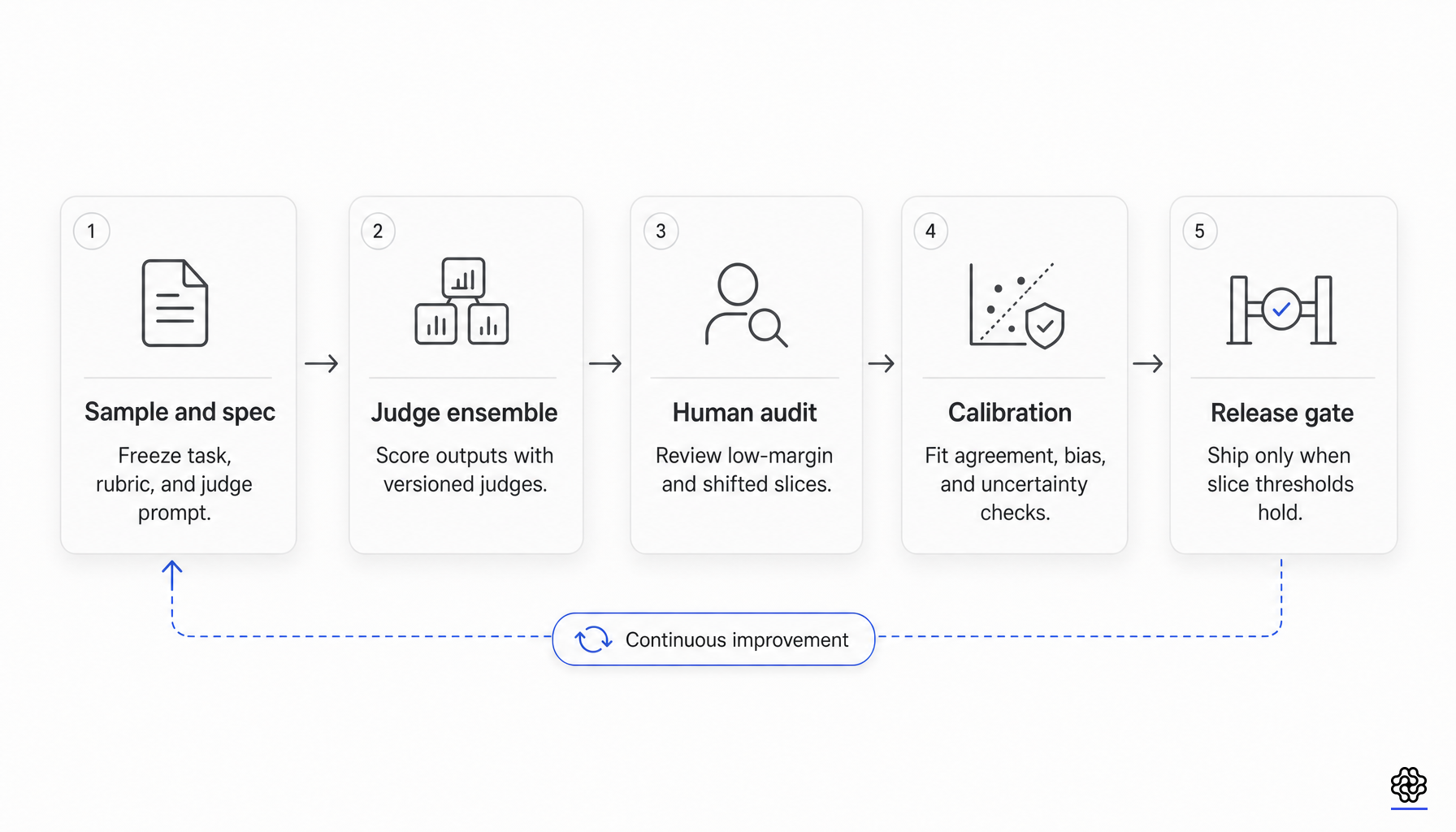
A concrete release-gate anti-pattern follows from the evidence: using a single average judge score or pairwise win rate as a universal pass threshold. That assumes measurement invariance the current evidence does not support. A better minimum contract is narrower and explicitly audited:
- Pin the judge model version, judge prompt, rubric text, reference policy, tie policy, and aggregation logic.
- Maintain a human-labeled calibration set for the exact release distribution, including high-risk slices.
- Report at least one chance-corrected agreement metric plus one rank or separability metric.
- Audit order effects, style and length effects, self-family preference, and reference sensitivity.
- Separate training-time reward selection from release-time acceptance.
- Escalate low-margin, high-disagreement, or newly shifted slices to human adjudication.
The practical boundary
The practical implication for production teams is narrow, but still strong. LLM judges are useful where human evaluation is too slow or expensive to run continuously, where the evaluation target is open-ended, and where the team is willing to spend real effort on calibration, bias audits, and human adjudication queues.
They are not portable truth meters. They are measurement infrastructure. Teams that treat them that way can use them for daily regression detection, candidate filtering, reward-model selection, and selective human escalation. Teams that do not will eventually optimize into their blind spots.
OpenTrain can source specialist human adjudicators for calibration sets, audit slices, and drift checks inside the evaluation stack a team already uses. Start with managed service when the bottleneck is operating the review loop, or post a job when the team wants to hire directly.
Sources
- MT-Bench and Chatbot Arena
- G-Eval
- AlpacaEval
- Arena-Hard
- JUDGE-BENCH
- JudgeBench
- IF-RewardBench
- Position bias in LLM-as-a-judge
- Self-recognition and self-preference
- No Free Labels
- RewardBench 2
- OpenAI graders
- OpenAI reinforcement fine-tuning cookbook
- Anthropic multi-agent research system
- SLMEval
- Diagnosing reliability via item response theory