Direct Preference Optimization vs PPO after RLHF

A technical reference on what DPO changes after RLHF, where PPO and online data still matter, and why preference measurement remains the hard part.
Direct Preference Optimization did not replace RLHF in full. It replaced a large part of what many teams associated with RLHF: training an explicit reward model and then running PPO against it. The stronger reading is narrower and more useful. DPO simplifies optimization much more than it simplifies measurement.
When offline preference data has weak coverage, when judges are biased, when reward models misgeneralize, or when labels are noisy, the missing PPO loop is not the core problem. The core problem is whether the measured preference objective transfers to the behavior the team actually cares about (DPO, InstructGPT, helpful-harmless RLHF).
The objective changes, but the evidence burden does not
PPO-style RLHF and DPO are different optimization interfaces to related preference-learning goals. Neither one proves that the underlying data or evaluator stack is good enough.
In classical PPO-based RLHF, the policy is optimized against a learned reward while staying near a reference policy:
DPO instead optimizes a pairwise loss over chosen and rejected responses, with the reference model still present as an anchor:
That substitution is real. It removes explicit reward-model training as a prerequisite for policy optimization, removes rollout-time reward queries during fine-tuning, and avoids PPO’s separate value-function and policy-gradient machinery. It does not remove dependence on pairwise preference data, the reference-policy anchor, or transfer evaluation.
DPO removes explicit reward-model-plus-PPO training work, but not calibrated data, judge diagnostics, or transfer evaluation.
| Layer | PPO-era RLHF | DPO-family approach | What still must be measured | Why it stays hard |
|---|---|---|---|---|
| Reward model | Train an explicit reward model before PPO. | Represent the reward relation implicitly in pairwise loss. | Preference-label validity. | Noisy or narrow labels still optimize the wrong signal. |
| Policy optimization | Run PPO with value and policy-gradient machinery. | Optimize a reference-anchored offline objective. | Transfer to deployment behavior. | Offline data may miss current-policy errors. |
| On-policy data | Can collect new preference data during iterations. | Often starts from fixed comparison data. | Coverage of target slices. | Static data cannot cover new behaviors by default. |
| Evaluator stack | Used for reward-model training and release evidence. | Often shifts more trust to judges or fixed data. | Judge bias and reliability. | Position, verbosity, and perturbation failures remain. |
| Holdout transfer | Benchmark and downstream checks after PPO. | Benchmark and downstream checks after DPO. | Unseen prompts and policy lineage. | Benchmark rank is useful but insufficient. |
Reward model
- PPO-era RLHF
- Train an explicit reward model before PPO.
- DPO-family approach
- Represent the reward relation implicitly in pairwise loss.
- What still must be measured
- Preference-label validity.
- Why it stays hard
- Noisy or narrow labels still optimize the wrong signal.
Policy optimization
- PPO-era RLHF
- Run PPO with value and policy-gradient machinery.
- DPO-family approach
- Optimize a reference-anchored offline objective.
- What still must be measured
- Transfer to deployment behavior.
- Why it stays hard
- Offline data may miss current-policy errors.
On-policy data
- PPO-era RLHF
- Can collect new preference data during iterations.
- DPO-family approach
- Often starts from fixed comparison data.
- What still must be measured
- Coverage of target slices.
- Why it stays hard
- Static data cannot cover new behaviors by default.
Evaluator stack
- PPO-era RLHF
- Used for reward-model training and release evidence.
- DPO-family approach
- Often shifts more trust to judges or fixed data.
- What still must be measured
- Judge bias and reliability.
- Why it stays hard
- Position, verbosity, and perturbation failures remain.
Holdout transfer
- PPO-era RLHF
- Benchmark and downstream checks after PPO.
- DPO-family approach
- Benchmark and downstream checks after DPO.
- What still must be measured
- Unseen prompts and policy lineage.
- Why it stays hard
- Benchmark rank is useful but insufficient.
OpenTrain synthesis from DPO, InstructGPT, Anthropic RLHF, coverage theory, RewardBench 2, and public post-training recipes cited in this article.
What DPO actually removes
DPO removes explicit reward-model training from the preference-tuning path and removes PPO-style online policy-gradient optimization from that phase. In engineering terms, that means fewer moving pieces, lower implementation complexity, less hyperparameter fragility, and fewer ways for reward-model collapse or PPO instability to dominate the run.
That simplification explains why open post-training stacks adopted DPO quickly. The original paper emphasized stability and low tuning burden, and public recipes such as Zephyr-style work and later Tulu-family releases made DPO a normal stage in open alignment workflows.
What DPO does not remove is dependence on trustworthy comparisons. The optimizer still inherits the preference relation encoded in the dataset. It still depends on the choice of reference model, beta scale, prompt distribution, and pair-selection policy. If the labels are noisy, distributionally narrow, biased by annotation artifacts, or produced by a brittle judge, DPO will optimize that problem efficiently.
The DPO family diversified for the same reason. KTO changes the supervision form from pairwise preferences to desirable-versus-undesirable signals. ORPO folds preference learning into a monolithic SFT-style stage. SimPO removes the reference-model term and reported gains over DPO in its setups. These are meaningful algorithmic changes, but none remove the need to know whether labels, judges, or benchmarks reflect downstream quality (KTO, ORPO, SimPO).
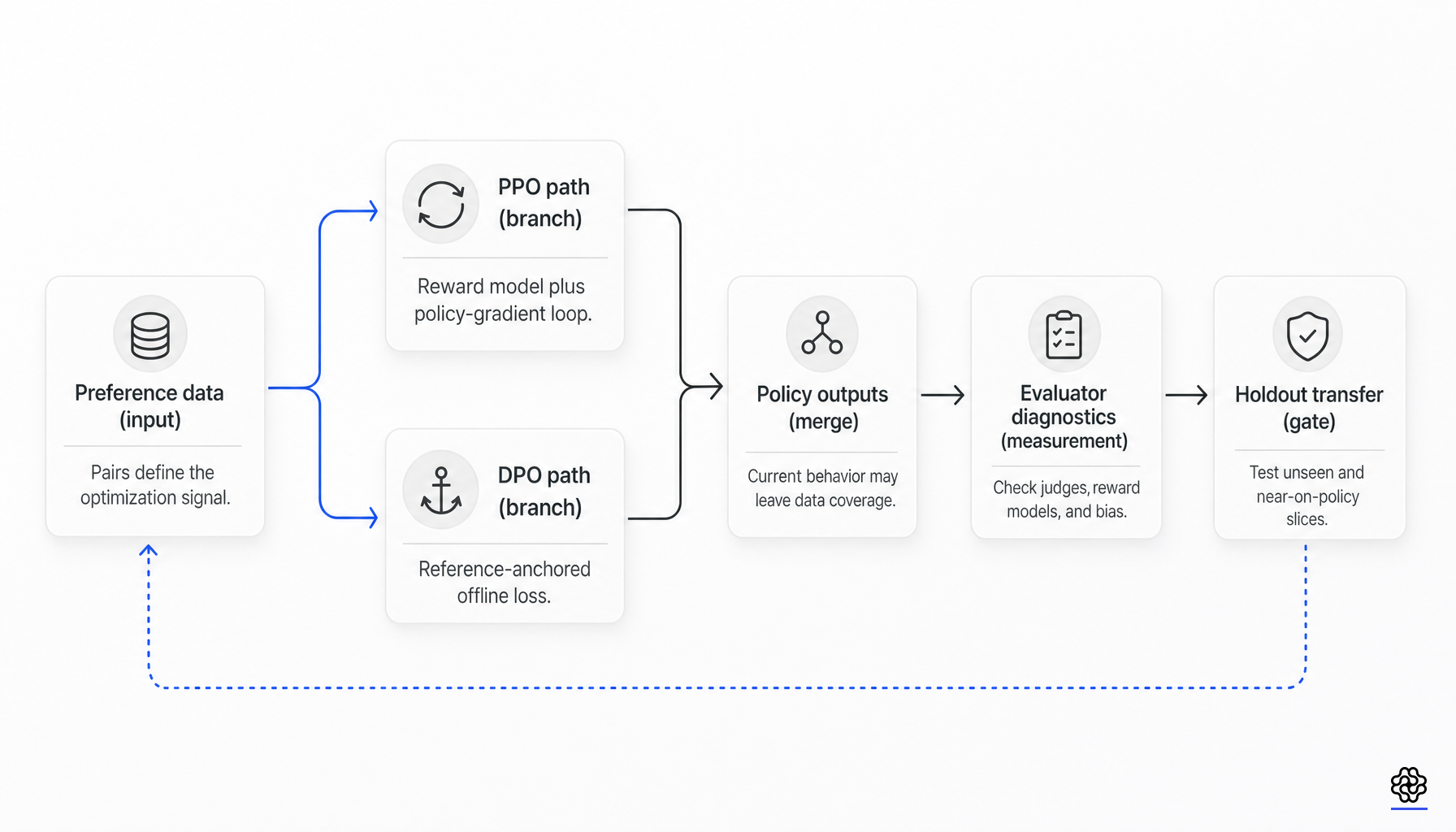
What DPO does not remove
The cleanest current limitation comes from the coverage literature. Song et al. argue that offline contrastive methods such as DPO need stronger global coverage to converge to the optimal policy, while online RL methods can succeed under weaker partial coverage. The operational point is simple: if the fixed preference dataset does not cover the response space that matters at evaluation time, the optimizer cannot infer that missing information (online data and coverage).
Tajwar et al. reach a related empirical point. Their experiments argue that on-policy sampling and negative-gradient-style preference objectives can outperform purely offline objectives because they can reallocate probability mass toward preferred regions faster. That is not a blanket defense of PPO. It is a reminder that online information can matter when the current policy’s own mistakes are not represented in static data (on-policy preference fine-tuning).
This is where the DPO-versus-PPO slogan usually breaks. If the target behavior is stable and well represented in preference data, DPO can buy most of the practical gain at lower complexity. If the model is expected to move into new behaviors, new prompt regimes, or adversarial slices after training, the team still needs on-policy data, online RL, rejection sampling, or targeted data refresh.
Empirical contrasts behind the slogan
The right interpretation of the evidence is not “DPO lost” or “PPO won.” It is that DPO changed the optimizer more than it changed the epistemology. Better preference data, current-policy coverage, reward-model transfer, and judge reliability often dominate algorithm branding.
Public evidence favors a conditional reading: DPO is often simpler and strong, while data quality, coverage, and evaluator validity still decide transfer.
| Study/report | Setup | Key result | Measurement implication |
|---|---|---|---|
| DPO paper | DPO vs PPO-based RLHF. | DPO matched or improved summarization and dialogue quality while being simpler to train. | Explains DPO adoption without proving measurement is solved. |
| Unpacking DPO and PPO | Controlled preference-learning recipes. | PPO beat DPO in some math and general regimes while data quality moved results more. | Algorithm choice can matter less than data validity. |
| On-policy preference fine-tuning | Offline contrastive methods vs online or negative-gradient methods. | On-policy sampling can outperform pure offline objectives. | Coverage failures can make online information valuable. |
| RewardBench 2 | Benchmark score vs downstream use. | Best-of-N correlation was strong, but PPO transfer depended on lineage and distribution. | Benchmark rank alone is not transfer evidence. |
| JudgeBench | LLM judge evaluation. | Strong judges struggled on hard objective response pairs. | Automated evaluation can become the bottleneck after optimization is simplified. |
DPO paper
- Setup
- DPO vs PPO-based RLHF.
- Key result
- DPO matched or improved summarization and dialogue quality while being simpler to train.
- Measurement implication
- Explains DPO adoption without proving measurement is solved.
Unpacking DPO and PPO
- Setup
- Controlled preference-learning recipes.
- Key result
- PPO beat DPO in some math and general regimes while data quality moved results more.
- Measurement implication
- Algorithm choice can matter less than data validity.
On-policy preference fine-tuning
- Setup
- Offline contrastive methods vs online or negative-gradient methods.
- Key result
- On-policy sampling can outperform pure offline objectives.
- Measurement implication
- Coverage failures can make online information valuable.
RewardBench 2
- Setup
- Benchmark score vs downstream use.
- Key result
- Best-of-N correlation was strong, but PPO transfer depended on lineage and distribution.
- Measurement implication
- Benchmark rank alone is not transfer evidence.
JudgeBench
- Setup
- LLM judge evaluation.
- Key result
- Strong judges struggled on hard objective response pairs.
- Measurement implication
- Automated evaluation can become the bottleneck after optimization is simplified.
OpenTrain synthesis from the cited DPO, PPO, RewardBench 2, data-selection, and judge-evaluation sources.
Ivison et al. found PPO advantages in some controlled regimes while also showing that preference-data quality could move instruction-following and truthfulness more than the optimizer swap itself (Unpacking DPO and PPO). Data-centric work reaches the same practical conclusion. Filtered DPO, Less is More, and HelpSteer-style datasets all point to the same constraint: the chosen data distribution and label protocol can dominate raw dataset size or optimizer name (Filtered DPO, Less is More, HelpSteer3-Preference).
Where measurement fails first
The most useful failure mode is not abstract reward hacking. It is mispredicted transfer: the offline preference objective looks good on a training-aligned metric, but the downstream system fails on the behavior the team actually cares about.
RewardBench 2 is one clear public example. It was built around unseen human prompts and a harder best-of-4 format. Scores were about 20 points lower on average than on the original RewardBench. The benchmark correlated strongly with best-of-N downstream use, with Pearson correlation 0.87, but it was only a helpful signal, not sufficient transfer evidence for PPO. In the paper’s PPO experiments, an off-policy reward model with RewardBench 2 score 72.9 achieved PPO score 54.5, while an on-policy reward model with RewardBench 2 score 68.7 achieved PPO score 59.8 (RewardBench 2).
Reward-model evaluation work on overoptimization points the same way. If the benchmark does not approximate the optimization pressure the policy will experience, a high benchmark score may tell the team less than it thinks (reward model evaluation, reward overoptimization).
A third version appears in human feedback itself. A 2024 study on Anthropic-HH found substantial low-agreement or no-agreement slices relative to a committee of reward models, and its cleaned-data model improved downstream DPO behavior under the paper’s evaluation setup. This is not proof that a reward-model committee equals ground truth. It is evidence that fixed preference data is not a monolith (human feedback reliability).
Judges and reward models still need diagnostics
Once teams stop training an explicit reward model for PPO, they often shift more trust onto LLM judges or static preference sets. That can hide the same measurement error behind a cleaner optimizer.
JudgeBench showed that strong judges such as GPT-4o performed only slightly better than random guessing on difficult objective response pairs in knowledge, reasoning, math, and coding. RAND’s 2026 Judge Reliability Harness broadened the point: no judge they tested was uniformly reliable across benchmarks, and perturbations such as formatting changes, paraphrases, verbosity shifts, and label flips caused meaningful reliability variation (JudgeBench, Judge Reliability Harness).
The bias literature makes this sharper. LLM evaluators can recognize and favor their own generations. Pairwise judges can exhibit position bias, task dependence, and disagreement-heavy hard slices. Length-Controlled AlpacaEval is a good example of the field correcting a measurement artifact rather than merely improving an optimizer (self-preference, position bias, Length-Controlled AlpacaEval).
The mitigation lesson is not that automated judges are unusable. It is that a judge is an instrument. It needs instrument checks: position swaps, paraphrase invariance, verbosity controls, repeated sampling, and anchor items with known labels.
Public production stacks stay multistage
Public evidence from leading model producers points in the same direction. Meta’s Llama 3.1 post-training writeup says each alignment round involved SFT, rejection sampling, and DPO. Qwen2.5 reports large-scale SFT and multistage reinforcement learning. DeepSeek-R1 describes two RL stages, cold-start data, rejection sampling, and later supervision expansion. Tulu 3 combines SFT, curated on-policy preference data for DPO, reward modeling, RL with verifiable rewards, decontamination, and separate development versus unseen evaluation suites (Llama 3.1, Qwen2.5, DeepSeek-R1, Tulu 3).
The appropriate phrasing is inference from public evidence, not a universal fact about every closed frontier stack. But the inference is strong: high-performing public stacks do not treat DPO as a reason to stop investing in evaluation, on-policy data refresh, rejection sampling, or targeted RL stages. They use DPO as one stage in a broader post-training system.
A practical implementation pattern
A technically defensible post-training pattern in 2026 looks less like “pick DPO or PPO” and more like staged measurement design.
First, teams need a preference dataset calibrated for the target use case rather than merely large. If the data source is heterogeneous, slice it by judge source, prompt family, task type, and likely noise regime before training claims are made.
Second, teams need evaluator diagnostics before using a reward model or LLM judge as either a trainer or an assessor. At minimum, that means position-swap checks, paraphrase and formatting invariance checks, verbosity-bias checks, repeated-sampling stability, and a small human-verified anchor set.
Third, teams need real transfer evaluation. The holdout is not only held-out preference pairs. It should include unseen prompts, adversarial slices, judge-stress slices, and, where possible, an on-policy or near-on-policy slice produced by the current model.
Fourth, teams should decide whether online data is necessary by diagnosing coverage, not by ideology. If evaluation failures cluster on current-policy outputs, or if the model is moving into reasoning or safety regimes not represented in the dataset, online collection, rejection sampling, or RL can still be the cheaper way to buy reliable improvement.
The practical takeaway is narrow but strong. DPO should be treated as an optimizer substitution, not an evaluation substitution. It often removes expensive online optimization machinery. It does not remove the need to know whether the chosen preference objective, label process, reward model, or judge actually transfers.
OpenTrain can source specialist evaluators and preference-data operators inside the stack a team already uses. Use the LLM judge reliability reference for evaluator calibration context, the RLHF scoping guide for preference-data planning, and post a job when the bottleneck is staffing the review loop.
Sources
- Direct Preference Optimization
- Training language models to follow instructions with human feedback
- Training a Helpful and Harmless Assistant with RLHF
- Unpacking DPO and PPO
- Preference fine-tuning with suboptimal on-policy data
- The Importance of Online Data
- RewardBench 2
- Reward model evaluation
- Reward overoptimization
- JudgeBench
- Judge Reliability Harness
- LLM evaluators recognize and favor their own generations
- Judging the Judges
- Filtered Direct Preference Optimization
- Less is More
- HelpSteer3-Preference
- Llama 3.1
- Qwen2.5 technical report
- Tulu 3
- DeepSeek-R1
- KTO
- ORPO
- SimPO
- Length-Controlled AlpacaEval