How to scope an RLHF data program

A practical framework for launching an RLHF program: define queue geometry, size raters from observed throughput, budget the review loop, and run weekly refresh gates.
Most first RLHF data programs break at the human layer, not the PPO loop. The expensive mistakes are ordinary: a rubric that mixes safety, factuality, style, and task success into one click; no calibration pass before production labeling; and a budget that assumes every preference pair has the same cost. Public examples range from OpenAI’s early backflip work, which used about 900 bits of feedback in under an hour of evaluator time, to Anthropic’s HH-RLHF release with 169,352 chosen/rejected rows (OpenAI, Anthropic HH-RLHF dataset). Scope should come from task geometry, not from copying a frontier-lab headline number.
What are humans actually judging?
Start with a narrower question than “which response is better?” InstructGPT separated supervised demonstrations, reward-model comparisons, and prompts for policy optimization; those data products teach different parts of the system (InstructGPT). Demonstrations teach format and task completion. Preference pairs teach relative judgment. Prompt pools decide what the tuned model sees during training.
For a first or second program, split work into three queues:
- Success queue: prompts where the model is usually right and needs occasional preference checks.
- Boundary queue: edge cases where behavior drifts on policy, safety, factuality, or style.
- Recovery queue: adversarial or high-risk cases where a wrong answer is expensive.
That queue split determines which annotation product to buy first. If you need pairwise preferences, route the program around RLHF and preference data. If the failure lives inside the response, collect labels inside the response. OpenAI’s process-supervision work released PRM800K with roughly 800,000 step-level labels and found that process supervision outperformed outcome supervision on the evaluated MATH setting (Let’s Verify Step by Step). For math, code reasoning, and multi-step tool use, pairwise preference alone is often too coarse.
How much data is enough for the first serious run?
Use public programs as operating shapes, not quotas. OpenAI’s summarization work used 64,832 summary comparisons; InstructGPT reported about 13,000 supervised prompts, about 33,000 reward-model prompts, and about 40 screened contractors; PRM800K was much larger because each unit of supervision was a smaller step-level judgment (summarization from human feedback, InstructGPT, PRM800K).
Public RLHF program shapes
| Public program | Human-feedback footprint | What it tells you |
|---|---|---|
| OpenAI backflip | About 900 bits of feedback, under 1 hour of evaluator time, and about 70 hours of simulated experience. | Very narrow objectives can justify tiny pilots if the task is easy to judge. |
| OpenAI summarization | 64,832 summary comparisons. | A single-task text-alignment program reaches tens of thousands quickly once you want stable reward modeling. |
| InstructGPT | About 13k SFT prompts, 33k reward-model prompts, and about 40 contractors. | Assistant alignment usually needs multiple queues, not one annotation type. |
| Anthropic HH-RLHF | 169,352 chosen and rejected rows in the released dataset; the underlying training setup used weekly online refresh with fresh human feedback. | Conversational post-training benefits from refresh loops, not one static batch. |
| OpenAI process supervision | PRM800K with 800,000 step-level labels; the process-supervised model solved 78% of a representative MATH subset. | Step-level labels are only worth the cost when intermediate correctness is the real bottleneck. |
OpenAI backflip
- Human-feedback footprint
- About 900 bits of feedback, under 1 hour of evaluator time, and about 70 hours of simulated experience.
- What it tells you
- Very narrow objectives can justify tiny pilots if the task is easy to judge.
OpenAI summarization
- Human-feedback footprint
- 64,832 summary comparisons.
- What it tells you
- A single-task text-alignment program reaches tens of thousands quickly once you want stable reward modeling.
InstructGPT
- Human-feedback footprint
- About 13k SFT prompts, 33k reward-model prompts, and about 40 contractors.
- What it tells you
- Assistant alignment usually needs multiple queues, not one annotation type.
Anthropic HH-RLHF
- Human-feedback footprint
- 169,352 chosen and rejected rows in the released dataset; the underlying training setup used weekly online refresh with fresh human feedback.
- What it tells you
- Conversational post-training benefits from refresh loops, not one static batch.
OpenAI process supervision
- Human-feedback footprint
- PRM800K with 800,000 step-level labels; the process-supervised model solved 78% of a representative MATH subset.
- What it tells you
- Step-level labels are only worth the cost when intermediate correctness is the real bottleneck.
OpenTrain synthesis from cited public sources.
The first rule is to pilot before scaling. RewardBench reports that some preference-data test sets have human ceiling accuracy in the 60-70% range, which means disagreement can be a property of the task rather than a rater-capacity failure (RewardBench). If your pilot agreement is bad, add specification before adding seats.
The second rule is to increase information density before prompt count. InstructGPT asked labelers to rank 4 to 9 outputs for a prompt, which created more comparison information per prompt than a single binary choice (InstructGPT). That is often a better first move than doubling the rater pool on an unstable rubric.
How many raters do you actually need?
Rater count is a throughput calculation with a disagreement buffer:
Use your pilot numbers for the denominator. Productive utilization includes everything that steals time from pure labeling: rubric refresh, adjudication, spot checks, retraining, breaks, and tool friction.
For example, suppose the pilot shows 180 calibrated judgments per rater per week and the next refresh needs 3,000 judgments per week. At 70% productive utilization, the base team is ceil(3000 / 180 / 0.70) = 24 raters before domain, language, time-zone, and backup-capacity buffers. If the queue needs four domain-language cells, do the math per cell before pooling the total.
Public anchors are useful only as sanity checks. InstructGPT reported training-labeler agreement of 72.6 +/- 1.5% and held-out labeler agreement of 77.3 +/- 1.3%; OpenAI’s summarization work reported 73 +/- 4% researcher-researcher agreement (InstructGPT, summarization from human feedback). Those numbers are not rater-count prescriptions. They are reminders that a small calibrated team can support a serious run, and that disagreement in the high-60s or low-70s may be normal when the task is hard.
Coverage matters as much as raw count. If the queue spans medicine, multilingual safety, and code review, you are sizing domain-language cells, not one pooled labor bucket. NIST’s AI RMF calls for diverse perspectives in mapping and measuring AI risks; its Generative AI Profile also recommends structured human-feedback exercises with documented roles and review paths (NIST AI RMF 1.0, NIST GenAI Profile).
How should the budget be built?
A primary-source rate card for RLHF preference pairs across domains, languages, and task designs is not publicly verifiable. Budget from timed work instead:
The line item teams miss is adjudication and researcher time. OpenAI’s summarization paper says the human-feedback dataset required significant labeler hours and researcher time to ensure quality (summarization from human feedback). That is why pilots that look cheap on a spreadsheet get expensive once the rubric starts changing.
Treat sourcing and marketplace fees as separate from labor. OpenTrain publishes a 15% self-serve fee and a 20% managed-service fee; teams can either hire directly or use managed service when they want OpenTrain to run the project operations (OpenTrain pricing). That matters when the bottleneck is sourcing and operating a calibrated queue, not designing the model update.
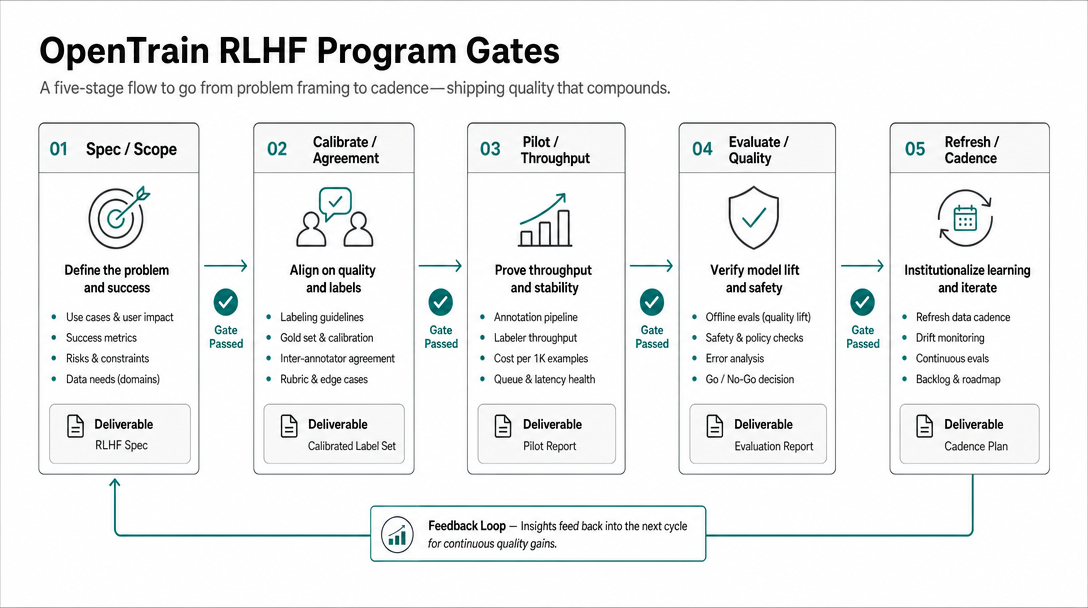
What timeline should you plan?
Think in gates, not in one monolithic labeling phase:
- Spec: define the rubric, disagreement rules, and escalation path.
- Calibrate: run sample items until adjudication stops discovering new rubric branches every day.
- Pilot: label a narrow queue with strict review.
- Evaluate: require hard negatives in the eval set.
- Refresh: update the rubric and repeat on a weekly or release-based cadence.
The public research pattern supports short loops. OpenAI’s early human-preference work actively sampled comparisons where the model was uncertain; InstructGPT used separate datasets for demonstrations, reward-model training, and policy optimization; DeepMind’s Sparrow work used targeted human judgments and evidence-backed evaluation; Anthropic’s helpful-harmless assistant paper describes iterative online data collection with fresh human feedback (OpenAI human preferences, InstructGPT, Sparrow, Anthropic HH-RLHF). First and second programs should copy the operating loop, not the dataset size.
How does scope change after the first run?
The first program should buy learning speed. A mature program should buy repeatability. Treat those as different purchases.
How RLHF scope changes after the first run
| Decision | First RLHF program | Second or mature program |
|---|---|---|
| Data target | Pilot the smallest queue that exposes rubric disagreement, task friction, and obvious reward-model failure modes. | Size weekly refresh batches from observed model drift, new product surfaces, and hard-negative mining. |
| Rater pool | Start with a small calibrated group and over-invest in adjudication notes. | Maintain domain-language cells, backup capacity, reviewer promotion paths, and attrition buffers. |
| QA | Review a high share of labels until the rubric stops changing daily. | Move to sampled review, gold items, disagreement dashboards, and scheduled rubric refresh. |
| Timeline | Gate on specification, calibration, pilot, evaluation, and a first refresh decision. | Gate on weekly or release-based refresh, eval regression checks, and queue-health metrics. |
| Sourcing model | Hire directly if the team can run calibration and adjudication. Use managed service if operating the queue is the bottleneck. | Keep a stable bench, add specialists only where the model or product surface changed, and separate sourcing fees from labor rates. |
| Success artifact | A usable rubric, an eval set with misses, and a rater-capacity model. | A repeatable operating cadence with known throughput, known disagreement bands, and a clear escalation path. |
Data target
- First RLHF program
- Pilot the smallest queue that exposes rubric disagreement, task friction, and obvious reward-model failure modes.
- Second or mature program
- Size weekly refresh batches from observed model drift, new product surfaces, and hard-negative mining.
Rater pool
- First RLHF program
- Start with a small calibrated group and over-invest in adjudication notes.
- Second or mature program
- Maintain domain-language cells, backup capacity, reviewer promotion paths, and attrition buffers.
QA
- First RLHF program
- Review a high share of labels until the rubric stops changing daily.
- Second or mature program
- Move to sampled review, gold items, disagreement dashboards, and scheduled rubric refresh.
Timeline
- First RLHF program
- Gate on specification, calibration, pilot, evaluation, and a first refresh decision.
- Second or mature program
- Gate on weekly or release-based refresh, eval regression checks, and queue-health metrics.
Sourcing model
- First RLHF program
- Hire directly if the team can run calibration and adjudication. Use managed service if operating the queue is the bottleneck.
- Second or mature program
- Keep a stable bench, add specialists only where the model or product surface changed, and separate sourcing fees from labor rates.
Success artifact
- First RLHF program
- A usable rubric, an eval set with misses, and a rater-capacity model.
- Second or mature program
- A repeatable operating cadence with known throughput, known disagreement bands, and a clear escalation path.
OpenTrain scoping model.
Where do programs usually fail?
Most quality failures are measurement failures. RewardBench reports that some hard subsets remain difficult for reward models, and that human disagreement can cap benchmark reliability (RewardBench). If an internal eval saturates immediately, it is probably too easy to govern the next model refresh.
For factuality and policy-sensitive work, make judgment easier for the rater. Sparrow attached evidence to factual claims and evaluated rule violations under adversarial probing (DeepMind Sparrow blog, Sparrow paper). For production programs, connect this to LLM evaluation early: the eval set should contain examples the model still misses, not only examples that prove the pilot worked.
Governance belongs in scope when the system is high-risk or production-bound. NIST’s AI RMF and GenAI Profile are useful operating references for documenting risks, measurement methods, and feedback use; the EU AI Act requires governance practices such as technical documentation, logging, human oversight, and robustness for high-risk AI systems (NIST AI RMF 1.0, NIST GenAI Profile, EU AI Act overview). This is not legal advice. It is a scoping reminder: if the RLHF pipeline feeds a high-risk workflow, documentation starts in week one.
What should the first program leave behind?
A good first RLHF program leaves three reusable assets:
- A rubric that absorbed repeated adjudication.
- An evaluation set with examples the model still misses.
- A rater-capacity model the team can run weekly without relearning operations.
If those artifacts exist, the next program gets cheaper to scope. If they do not, the team bought labels but did not buy an operating system.
What to do next
Citations
- OpenAI — Learning from human preferences
- Training language models to follow instructions with human feedback
- Learning to summarize from human feedback
- Anthropic HH-RLHF dataset card
- Training a Helpful and Harmless Assistant with RLHF
- Sparrow: Improving alignment of dialogue agents via targeted human judgements
- DeepMind — Building safer dialogue agents
- Let’s Verify Step by Step
- RewardBench
- NIST AI RMF 1.0
- NIST Generative AI Profile
- EU AI Act overview
- OpenTrain pricing