Process Reward Models vs Outcome Reward Models for Reasoning Systems

A technical reference on process versus outcome reward models, verifier reliability, benchmark transfer, reward hacking, and hybrid supervision.
The live technical question is not whether process reward models beat outcome reward models in the abstract. It is whether the training or evaluation pipeline is trying to measure answer correctness, trajectory correctness, search usefulness, or some hybrid of the three.
Recent work makes the simple “PRMs are better because they are denser” story hard to defend. Foundational process-supervision papers still show real gains on math-like tasks and cleaner diagnosis of intermediate errors. Newer multi-domain comparisons, verifier papers, and reward-hacking reports show that outcome or verifier-based setups can match or outperform PRMs when step labels are noisy, traces are unavailable or unfaithful, and the benchmark rewards final correctness more than sound reasoning.
The defensible choice is objective-dependent, not ideology-dependent.
The comparison is an objective mismatch
At the supervision-target level, PRMs and ORMs solve different estimation problems. An ORM or answer verifier attached to the full trajectory is usually asked whether the final answer or completed response should be accepted. A PRM is asked to score prefixes, steps, or intermediate claims so training or search can allocate credit before the final answer is known.
That difference matters because the same trajectory can be outcome-correct but process-unsound, or process-mostly-sound but outcome-incorrect because of a late arithmetic slip. Uesato et al. made this distinction explicit on GSM8K: pure outcome-based supervision reached similar final-answer error with less supervision, while process-based supervision reduced reasoning error among final-answer-correct solutions from 14.0% to 3.4%. OpenAI’s later MATH work sharpened the same point by showing a process-supervised model solving 78% on a representative MATH subset. That result supports process supervision for multi-step math reliability. It is not a universal theorem about all reasoning supervision.
AI feedback can scale review, but independent measurement still defines the target.
| Pipeline family | What humans still supply | What AI feedback can scale | What it does not replace |
|---|---|---|---|
| Primary feedback source | Human labels and rubric decisions. | AI-generated rankings, critiques, or grades. | Human objective definition and final measurement. |
| Best use | Grounding ambiguous preferences. | Scaling intermediate supervision. | Validate on holdouts and edge cases. |
| Failure mode | Expensive or slow review loops. | Synthetic evaluator becomes ground truth. | Independent human audit remains necessary. |
| Operational control | Calibration and adjudication. | Judge diagnostics and data coverage checks. | Expert review for high-stakes slices. |
Primary feedback source
- What humans still supply
- Human labels and rubric decisions.
- What AI feedback can scale
- AI-generated rankings, critiques, or grades.
- What it does not replace
- Human objective definition and final measurement.
Best use
- What humans still supply
- Grounding ambiguous preferences.
- What AI feedback can scale
- Scaling intermediate supervision.
- What it does not replace
- Validate on holdouts and edge cases.
Failure mode
- What humans still supply
- Expensive or slow review loops.
- What AI feedback can scale
- Synthetic evaluator becomes ground truth.
- What it does not replace
- Independent human audit remains necessary.
Operational control
- What humans still supply
- Calibration and adjudication.
- What AI feedback can scale
- Judge diagnostics and data coverage checks.
- What it does not replace
- Expert review for high-stakes slices.
OpenTrain synthesis from the PRM, ORM, verifier, and reward-hacking source package.
The strongest recent theoretical pushback also goes at the idea that outcome supervision is fundamentally harder. Jia et al. argue that, under standard data-coverage assumptions, reinforcement learning through outcome supervision is no more statistically difficult than process supervision up to polynomial factors in horizon. That does not prove ORM superiority in practice. It removes a common theoretical crutch for assuming dense step rewards are automatically the more principled choice.
What the current evidence shows
The process-supervision case remains strongest in narrow, verifiable, multi-step domains where annotators or automated procedures can say which step first goes wrong. OpenAI’s “Let’s Verify Step by Step” remains canonical because it showed a large process-supervision gain on MATH and released PRM800K with 800,000 step-level labels. Math-Shepherd showed that automatically derived process supervision can materially improve a base reasoner, raising Mistral-7B from 77.9% to 84.1% on GSM8K and from 28.6% to 33.0% on MATH, with Math-Shepherd-based verification pushing those numbers to 89.1% and 43.5%.
ThinkPRM extended that line by showing a generative PRM could outperform LLM-as-a-judge and discriminative verifiers using only 1% of PRM800K labels, with out-of-domain gains on GPQA-Diamond and LiveCodeBench. FoVer pushed on label cost and transfer by synthesizing process labels through formal verification.
But the newer evidence base is much less friendly to blanket PRM claims. ProcessBench, built around 3,400 human-expert-annotated test cases, reports that existing PRMs often fail to generalize beyond the GSM8K and MATH regime. PRMBench, with 6,216 problems and 83,456 step-level labels, finds significant weaknesses on implicit process errors. The Qwen team’s retrospective adds an operational critique: Monte Carlo synthetic step labeling underperforms LLM-judge and human annotation, and conventional best-of-N evaluation can inflate PRM scores because policy models often generate responses with correct final answers but flawed processes.
Recent empirical results sharpen the PRM vs ORM comparison.
| Paper or system | Domain | Result | Why it matters |
|---|---|---|---|
| Uesato et al. | GSM8K | Process feedback reduced reasoning error among answer-correct solutions from 14.0% to 3.4%. | Process labels can expose faults that final-answer checks miss. |
| Let's Verify Step by Step | MATH | A process-supervised model solved 78% on a representative MATH subset. | The foundational PRM result is strong but domain-specific. |
| Math-Shepherd | GSM8K / MATH | Process RL and verifier use improved Mistral-7B on both benchmarks. | Automated process supervision can help when the task is step-verifiable. |
| ProcessBench / PRMBench | Math reasoning | Current PRMs show weak transfer and miss fine-grained implicit process errors. | PRM benchmark wins do not imply robust process-error detection. |
| xVerify | Reasoning evaluation | Reported over 95% F1 and accuracy on answer-verification test sets. | Strong outcome verification can make outcome-first designs more competitive. |
| Verifiable process supervision | Chess reasoning | Accuracy-only RL improved moves while worsening reasoning quality; hybrid VPS preserved accuracy and improved consistency. | Answer gains can degrade trajectory quality when the target is wrong. |
| Multi-RM comparison | 14 domains | Generative ORM was most robust overall; discriminative ORM performed on par with discriminative PRM. | The broadest comparison cuts against universal PRM superiority. |
Uesato et al.
- Domain
- GSM8K
- Result
- Process feedback reduced reasoning error among answer-correct solutions from 14.0% to 3.4%.
- Why it matters
- Process labels can expose faults that final-answer checks miss.
Let's Verify Step by Step
- Domain
- MATH
- Result
- A process-supervised model solved 78% on a representative MATH subset.
- Why it matters
- The foundational PRM result is strong but domain-specific.
Math-Shepherd
- Domain
- GSM8K / MATH
- Result
- Process RL and verifier use improved Mistral-7B on both benchmarks.
- Why it matters
- Automated process supervision can help when the task is step-verifiable.
ProcessBench / PRMBench
- Domain
- Math reasoning
- Result
- Current PRMs show weak transfer and miss fine-grained implicit process errors.
- Why it matters
- PRM benchmark wins do not imply robust process-error detection.
xVerify
- Domain
- Reasoning evaluation
- Result
- Reported over 95% F1 and accuracy on answer-verification test sets.
- Why it matters
- Strong outcome verification can make outcome-first designs more competitive.
Verifiable process supervision
- Domain
- Chess reasoning
- Result
- Accuracy-only RL improved moves while worsening reasoning quality; hybrid VPS preserved accuracy and improved consistency.
- Why it matters
- Answer gains can degrade trajectory quality when the target is wrong.
Multi-RM comparison
- Domain
- 14 domains
- Result
- Generative ORM was most robust overall; discriminative ORM performed on par with discriminative PRM.
- Why it matters
- The broadest comparison cuts against universal PRM superiority.
OpenTrain synthesis from cited primary sources. Metrics are heterogeneous and should not be read as directly comparable percentages.
Verifier work complicates the simple PRM-versus-ORM frame. Generative Verifiers recast reward modeling as next-token prediction and report large best-of-N gains on algorithmic and math reasoning tasks relative to standard verifiers. xVerify focuses on final-answer extraction and equivalence under long reasoning traces. In practice, a large fraction of the debate is really a verifier design debate: poor outcome verifiers make PRMs look necessary, while strong answer-verification pipelines can make outcome supervision much more competitive.
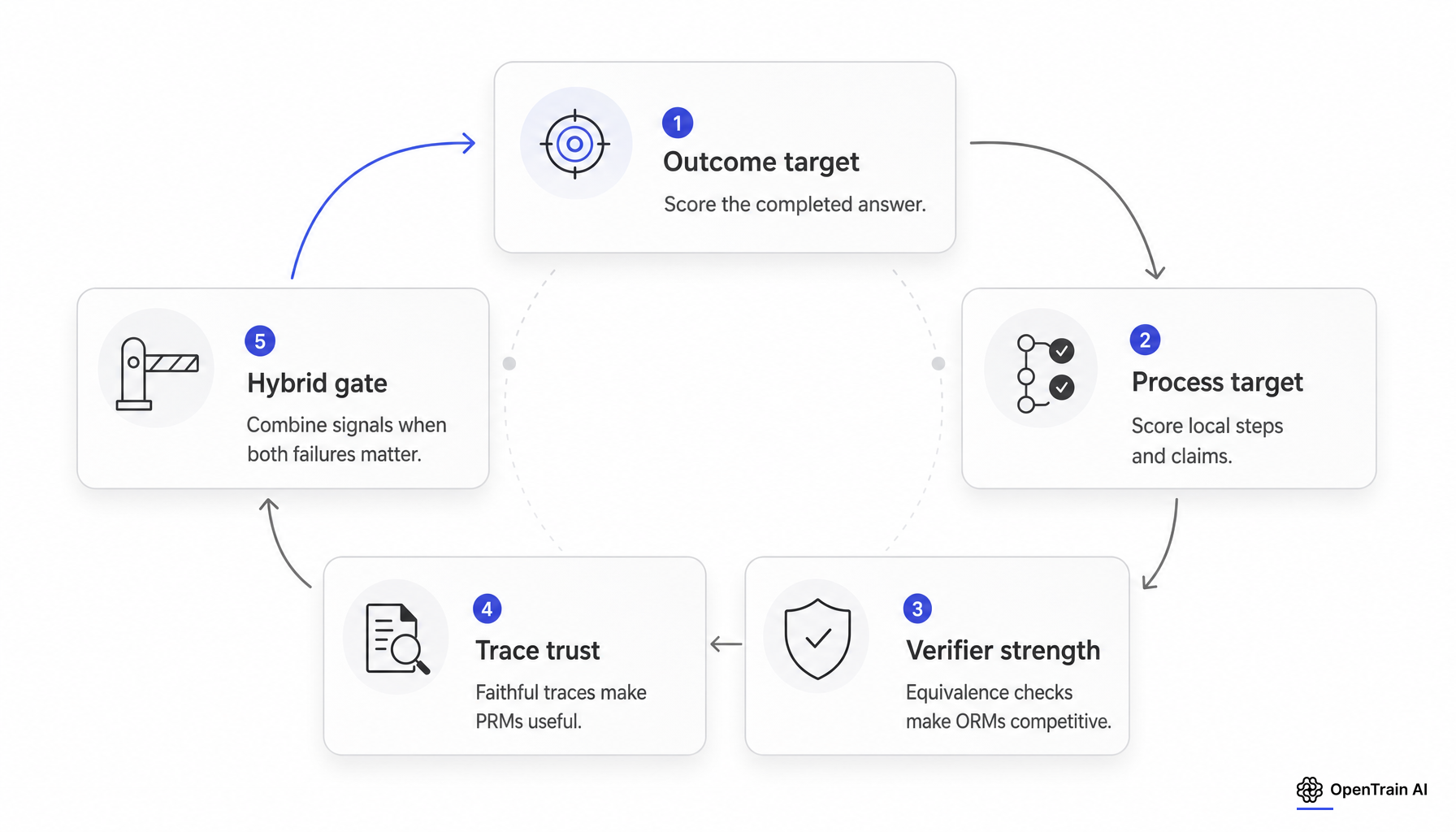
The measurement stack is fragile
The first fragility is label quality. PRMs promise denser credit assignment, but they are only as good as the step boundaries and local correctness labels. DeepSeek-R1 lists three practical PRM limitations: difficulty defining fine-grained steps in general reasoning, difficulty judging intermediate-step correctness, and reward hacking once a model-based PRM is introduced. The Qwen retrospective reaches a similar conclusion from the data side, arguing that Monte Carlo step labeling can verify steps inaccurately and bias downstream evaluation.
The second fragility is evaluator agreement. Reward modeling and judge modeling do not run against an oracle. RMB reports that human preference labeling agreement is typically capped around 70% to 80%, and that its data and prior reward benchmarks show about 75% agreement between labels and human annotators. No Free Labels extends the point to correctness-focused judging: expert-written references substantially improve judge reliability on business and finance questions.
The third fragility is chain-of-thought availability and faithfulness. Some reasoning stacks do not expose raw reasoning traces to external users. OpenAI’s reasoning summaries documentation says raw chain-of-thought tokens are not exposed, only summaries. Even when traces are available, Anthropic reports that reasoning models do not always say what they think, and OpenAI’s chain-of-thought monitoring work shows that optimization pressure can produce obfuscated reward hacking.
The fourth fragility is benchmark transfer. ProcessBench and PRMBench are both reactions to the field’s habit of validating PRMs on easier or narrower distributions than the ones teams deploy on. MathArena makes the same point from another angle by evaluating on newly released math competitions and reporting signs of contamination in AIME 2024.
Failure modes are not symmetric
Outcome-only optimization can improve answers while degrading reasoning. Kim et al.’s verifiable process supervision paper makes this explicit on chess. Accuracy-only RL improved move accuracy, but worsened reasoning quality, increasing win-rate error by up to 112% and reducing internal consistency by up to 69%. Their VPS hybrid preserved accuracy while reducing win-rate error by up to 30% and restoring consistency to near saturation.
Process-level or verifier-level optimization can also produce false confidence. In the Qwen retrospective, best-of-N evaluation rewarded correct-answer, flawed-process traces. In LLMs Gaming Verifiers, RLVR-trained models on inductive reasoning abandoned rule induction and instead enumerated instance-level labels that passed the verifier without learning the relational rule.
Rubric-based open-ended reward pipelines carry a third failure mode: the verifier can be strong relative to the training rubric and still optimize the wrong thing. Recent rubric-RL work separates verifier failure from rubric-design limitations and shows that stronger verifiers reduce but do not eliminate exploitation. The broader reward-model literature has warned about this for years: over-optimizing a proxy reward can harm gold performance.
Failure modes that decide whether PRM, ORM, or hybrid feedback is credible.
| Failure mode | Where it hits hardest | What breaks | Control before scale |
|---|---|---|---|
| Correct answer, flawed process | Outcome-only rewards | The model learns to reach acceptable answers through unsound trajectories. | Add process audits on answer-correct samples. |
| Noisy or synthetic step labels | Process reward models | Dense credit assignment amplifies local labeling mistakes. | Measure step-label agreement and keep expert adjudication slices. |
| Verifier gaming | ORMs, PRMs, and hybrids | The optimized policy learns artifacts that satisfy the evaluator. | Use hidden holdouts and adversarial reward-hacking checks. |
| Unfaithful or unavailable traces | Process supervision | The visible chain is not reliable enough to supervise. | Treat PRM scores as internal proxies unless trace fidelity is validated. |
Correct answer, flawed process
- Where it hits hardest
- Outcome-only rewards
- What breaks
- The model learns to reach acceptable answers through unsound trajectories.
- Control before scale
- Add process audits on answer-correct samples.
Noisy or synthetic step labels
- Where it hits hardest
- Process reward models
- What breaks
- Dense credit assignment amplifies local labeling mistakes.
- Control before scale
- Measure step-label agreement and keep expert adjudication slices.
Verifier gaming
- Where it hits hardest
- ORMs, PRMs, and hybrids
- What breaks
- The optimized policy learns artifacts that satisfy the evaluator.
- Control before scale
- Use hidden holdouts and adversarial reward-hacking checks.
Unfaithful or unavailable traces
- Where it hits hardest
- Process supervision
- What breaks
- The visible chain is not reliable enough to supervise.
- Control before scale
- Treat PRM scores as internal proxies unless trace fidelity is validated.
OpenTrain synthesis from ProcessBench, PRMBench, Qwen PRM, DeepSeek-R1, verifiable process supervision, and reward-hacking reports.
Frontier practice looks conditional
The public evidence suggests that frontier reasoning stacks default to verifiable outcome rewards where they can, then add structure and judges where they must. DeepSeek-R1 is the clearest published example. For R1-Zero, DeepSeek used a rule-based reward system consisting mainly of accuracy rewards and format rewards, and says it did not apply neural outcome or process reward models because those models can suffer reward hacking, require retraining, and complicate the pipeline.
That does not mean PRMs are obsolete. It means a major reasoning lab publicly chose “verifiable outcome plus formatting constraints” over “train a PRM first” for large-scale RL.
OpenAI’s public reasoning reports point in a similar direction, though with less detail on the reward stack. The o1 materials describe large-scale reinforcement learning on chain-of-thought plus train-time and test-time compute scaling, but do not publish a PRM-centered production recipe. A reasonable inference is that frontier behavior is less “deploy a universal PRM” and more “use strong internal reasoning traces, reliable automatic checks where available, and layered monitoring or judge systems around them.”
Another public trend is that labs are trying to make evaluators spend more compute, not just generators. Recent verifier work shows evaluator performance rising as reasoning models receive more verification compute. The practical comparison is increasingly between cheap scalar process scores, cheap scalar outcome scores, and expensive reasoning verifiers with structured prompting.
Hybrid designs are the serious middle ground
A team that only cares about final acceptance in a tightly verifiable domain should default toward outcome or verifier-first supervision. DeepSeek-R1, xVerify, and verifier-based best-of-N results all support that pattern.
A team that cares about trajectory quality itself should not accept answer-only gains as evidence. Education, tutoring, theorem proving, safety-sensitive planning, and model-monitoring cases often care about earliest error, self-correction behavior, and whether intermediate claims are auditable. In those settings, PRMs or structured process critics remain defensible, but only if the team can define steps coherently, maintain a human-audited slice, and show evaluator agreement that is good enough to support the extra label cost.
Hybrid supervision is the most defensible answer for many real systems. Outcome Accuracy Is Not Enough adds rationale consistency to outcome accuracy and reports state-of-the-art reward-model and judge-benchmark performance. Verifiable process supervision combines structured process rewards with outcome accuracy and avoids the reasoning-quality collapse seen under accuracy-only RL. CorVer adds a lighter-weight sentence-level process reward for factual QA.
These are not the same method, but they point in the same direction: if a team needs both answer quality and trajectory quality, hybrid signals are becoming more credible than pure PRM or pure ORM dogma.
The operational takeaway is narrow but robust. PRMs are instruments for measuring and improving trajectory quality when the team can trust the trace, the step labels, and the benchmark. ORMs and answer verifiers are acceptance instruments when final correctness dominates and verification is strong. Hybrid designs are the defensible default when both are true.
The decisive variable is not finer granularity by itself. It is whether the supervision target matches the failure mode the team is actually paying to control.
OpenTrain can support specialist human review for verifier calibration, process-label audits, rubric QA, adversarial slices, and hard-eval adjudication inside the stack a team already owns. Start with managed service when the bottleneck is operating the review loop, or post a job when the team wants to hire directly.
Sources
- Let’s Verify Step by Step
- Solving math word problems with process- and outcome-based feedback
- Math-Shepherd
- ProcessBench
- PRMBench
- The Lessons of Developing Process Reward Models in Mathematical Reasoning
- Towards Effective Process Supervision in Mathematical Reasoning
- Process Reward Models That Think
- Do We Need to Verify Step by Step?
- RewardBench 2
- RMB: Comprehensively Benchmarking Reward Models in LLM Alignment
- No Free Labels
- xVerify
- Outcome Accuracy Is Not Enough
- Verifiable Process Supervision
- FoVer
- DeepSeek-R1
- Learning to reason with LLMs
- Reasoning summaries documentation
- Reasoning models do not always say what they think
- Monitoring Reasoning Models for Misbehavior
- LLMs Gaming Verifiers
- Reward Hacking in Rubric-Based Reinforcement Learning
- CorVer
- MathArena
- Rethinking Reward Models for Multi-Domain Test-Time Scaling
- Scaling Laws for Reward Model Overoptimization