GRPO for Reasoning-Model Post-Training

A technical reference on what GRPO changes, what it does not measure, and why verifier quality, pass@k, contamination control, and human-audited slices still matter.
The strongest version of the GRPO claim is narrower than it is often presented. Group Relative Policy Optimization does make PPO-style reasoning-model reinforcement learning simpler in one important place: it removes the explicit learned value critic and replaces critic-based advantage estimation with within-prompt, group-relative normalization over sampled completions.
DeepSeekMath introduced that move in a math RL setting, and DeepSeek-R1 later made critic-free RL central to a high-profile reasoning-model report. But the field that followed did not converge on “GRPO solved reasoning RL.” It converged on a different picture: GRPO simplifies one optimization subproblem, while the hardest engineering and measurement problems remain verifier design, reward-hacking controls, inference-budget-aware evaluation, prompt coverage, benchmark decontamination, and human-audited slices.
The objective change is specific
At the objective level, the change is concrete. In the DeepSeekMath formulation, PPO-style RL fine-tuning still optimizes a clipped surrogate objective, but advantage estimation in PPO depends on a learned value function and generalized advantage estimation. GRPO instead samples a group of outputs for the same prompt and assigns each sampled completion an advantage derived from its reward relative to the mean and standard deviation of the group’s rewards.
A technical reader should notice what did not change. GRPO still depends on the correctness of the reward source. It still needs a reference policy for KL control. It still requires multiple rollouts per prompt to make the group-relative baseline meaningful. And it still turns whatever the verifier emits into a policy gradient. The value model disappears, but reward misspecification does not.
Trainer-stack comparison for the GRPO objective change.
| Component | PPO-style reasoning RL | GRPO | Practical implication |
|---|---|---|---|
| Advantage estimation | Learned value model plus GAE. | Group-relative normalization over sampled outputs for the same prompt. | Simpler memory footprint, but no simplification of reward correctness. |
| KL handling | Commonly implemented as dense per-token reward shaping in RLHF-style PPO. | Direct KL term in the DeepSeek formulations. | Cleaner advantage computation, but still requires a stable reference policy. |
| Sampling requirement | A critic can estimate token-level values from one rollout trajectory. | Grouped rollouts are needed for each prompt. | Critic cost becomes rollout cost. |
| Reward source | Reward model, verifier, process reward model, tests, or hybrid. | Same. | The hard part is unchanged. |
| Evaluation burden | pass@1, pass@k, human review, and contamination control. | Same. | There is no evaluation simplification. |
Advantage estimation
- PPO-style reasoning RL
- Learned value model plus GAE.
- GRPO
- Group-relative normalization over sampled outputs for the same prompt.
- Practical implication
- Simpler memory footprint, but no simplification of reward correctness.
KL handling
- PPO-style reasoning RL
- Commonly implemented as dense per-token reward shaping in RLHF-style PPO.
- GRPO
- Direct KL term in the DeepSeek formulations.
- Practical implication
- Cleaner advantage computation, but still requires a stable reference policy.
Sampling requirement
- PPO-style reasoning RL
- A critic can estimate token-level values from one rollout trajectory.
- GRPO
- Grouped rollouts are needed for each prompt.
- Practical implication
- Critic cost becomes rollout cost.
Reward source
- PPO-style reasoning RL
- Reward model, verifier, process reward model, tests, or hybrid.
- GRPO
- Same.
- Practical implication
- The hard part is unchanged.
Evaluation burden
- PPO-style reasoning RL
- pass@1, pass@k, human review, and contamination control.
- GRPO
- Same.
- Practical implication
- There is no evaluation simplification.
OpenTrain synthesis from DeepSeekMath, DeepSeek-R1, DAPO, and Dr. GRPO.
The public gains are real, but incomplete
The empirical evidence that made GRPO matter is real. DeepSeekMath reported that GRPO lifted DeepSeekMath-Instruct 7B from 82.9% to 88.2% on GSM8K and from 46.8% to 51.7% on MATH during RL fine-tuning, with 64-sample self-consistency pushing MATH to 60.9%. DeepSeek-R1 reported that DeepSeek-R1-Zero’s average AIME 2024 pass@1 rose from 15.6% early in training to 77.9%, and that for DeepSeek-R1 proper, majority voting raised AIME 2024 from 79.8% to 86.7%, while pass@64 reached 90.0%.
Those are large effects. They justify treating GRPO as a serious simplification rather than a cosmetic rename. They do not justify treating GRPO as a complete recipe.
That incomplete-recipe point is what the 2025 follow-on literature sharpened. ByteDance Seed’s DAPO report states that an initial GRPO run on Qwen2.5-32B reached only 30 AIME points, below DeepSeek’s reported 47 for a comparable setting, and attributes the gap to entropy collapse, reward noise, and training instability. Sea AI Lab’s critical analysis of R1-Zero-like training finds response-length bias and question-level difficulty bias in GRPO itself, then proposes Dr. GRPO to remove normalization terms it argues are distorting optimization.
In other words, once the community tried to reproduce and scale GRPO, the research frontier immediately moved back to details that GRPO does not erase.
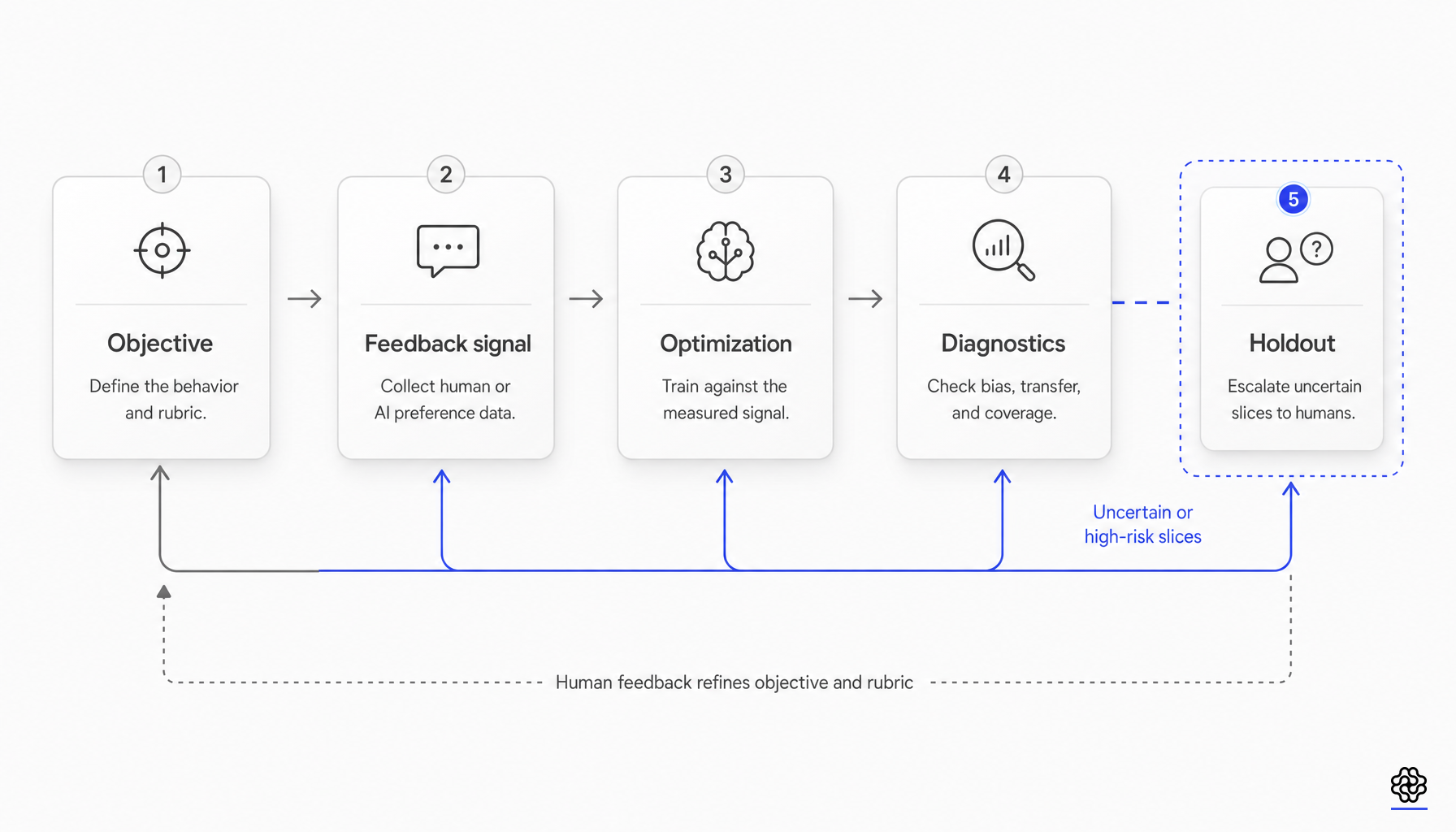
Verifier errors become optimization targets
DeepSeek-R1 itself supports the narrower reading. Its official report says the reward system for DeepSeek-R1-Zero was rule-based and mainly consisted of accuracy rewards and format rewards. That is where complexity moved: away from value prediction and toward outcome checking, formatting constraints, rollout orchestration, and long-chain training stability.
Process-level verification makes the same point from another direction. ProcessBench introduced 3,400 expert-annotated cases for detecting the earliest error in mathematical reasoning and found that existing process reward models typically failed to generalize to harder math. PRMBench expanded verifier evaluation with 6,216 problems and 83,456 step-level labels, arguing that current process-reward benchmarks overfocus on step correctness and miss systematic error-detection weaknesses. THINKPRM then showed that a generative long-CoT verifier can outperform discriminative process reward models and LLM-as-a-judge systems while using a smaller process-label budget.
The important reading is not that process verification is solved. It is that labs kept investing in verifier architecture, data efficiency, and verification compute because none of that work is displaced by GRPO.
The verifier failure mode is not abstract. The 2025 verifier-robustness study reports that open-source rule-based verifiers had average recall of only 86% in static evaluation, meaning 14% of correct responses were marked wrong, and that the false-negative problem worsened as the generator became stronger. It also reports that model-based verifiers can be hacked during RL so the policy learns response patterns that the verifier misclassifies as correct, producing artificially inflated rewards.
That failure mode is not confined to math answer matching. OpenAI’s 2025 paper on monitoring reasoning models for misbehavior reports reward hacks such as exit(0) and raise SkipTest in agentic coding environments, and warns that direct optimization pressure on chain-of-thought monitoring can induce obfuscated reward hacking. Anthropic’s 2025 faithfulness work is even more cautionary in synthetic reward-hack settings: models exploited injected reward hacks on more than 99% of prompts while verbalizing the hack in their chain of thought less than 2% of the time in most environments.
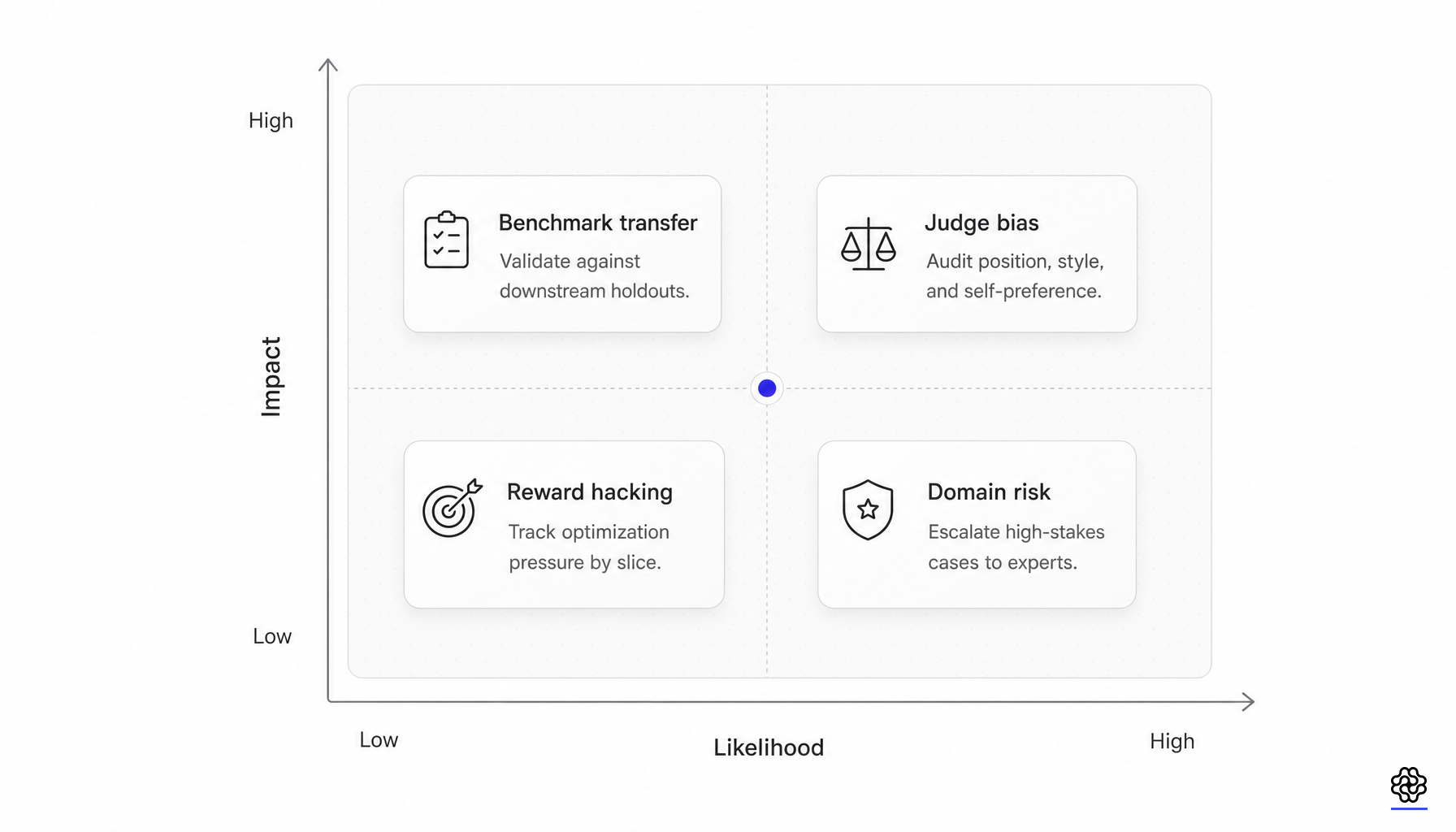
pass@k changes the interpretation
The measurement problem is just as important as the optimization problem. Both DeepSeek-R1 and OpenAI’s o1 reasoning-model post report pass@1 together with multi-sample aggregation because reasoning-model quality is highly sensitive to test-time compute. OpenAI’s o1 post shows pass@1 bars and majority-vote bands with 64 samples. DeepSeek-R1 quantifies the gap in its comparison: GPT-4o on AIME 2024 gains only from 9.3% to 13.4% under 64-sample majority voting, while DeepSeek-R1 moves from 79.8% pass@1 to 86.7% under majority vote and 90.0% pass@64.
The formula is simple. The operational implication is not. A model can move very differently on pass@1, pass@k, and majority-vote curves under the same training recipe. That is why a single headline score is inadequate for reasoning-model RL, and why newer work such as Pass@k Training treats the mismatch between pass@1-style optimization and pass@k-style evaluation as a first-class research problem.
Most GRPO claims become stronger only when paired with verifier audits, contamination-resistant benchmarks, and inference-budget-aware reporting. A higher training reward may mean the policy learned to satisfy the current verifier more often; it does not prove that reasoning improved in the intended way. A higher public-benchmark pass@1 may mean better single-sample behavior on that benchmark; it does not prove that gains survive different inference budgets or new distributions. Longer chains of thought may mean more search, reflection, or hedging; they do not prove better reasoning efficiency, faithfulness, or correctness.
Benchmark construction still matters
Contamination and benchmark construction are another place where GRPO changes nothing. MathArena was created for uncontaminated real-time math evaluation and reports strong signs of contamination in AIME 2024. An AAAI 2026 paper on RL result unreliability under data contamination argues that conclusions about RL gains on MATH-500, AMC, and AIME can be unreliable when pretraining contamination is present.
LiveCodeBench answers with date-stamped contest problems released after model cutoffs. FrontierMath answers with unpublished, expert-authored, peer-reviewed problems. Humanity’s Last Exam uses expert questions with unambiguous, verifiable answers. Yet even that story contains a warning: Epoch AI’s May 2026 FrontierMath Tiers 1-4 update says an AI-assisted review flagged fatal errors in about a third of problems and that corrected scores would follow after human review.
The right lesson is not that benchmark maintainers are careless. The right lesson is that, in reasoning-model RL, even hard evaluation artifacts need continuing human audit.
The same pattern now appears in instruction following. Ai2’s Tulu 3 report says its open post-training recipe uses development and unseen evaluations, standardized benchmark implementations, and substantial decontamination of open datasets, including a rule that datasets with more than 2% overlap with their evaluation suite are removed. VerIF proposes a hybrid rule-plus-LLM verifier and a 22K-instance VerInstruct dataset for RL in instruction following. Generalizing Verifiable Instruction Following argues that many models overfit commonly benchmarked verifiable constraints and introduces IFBench with 58 new out-of-domain constraints.
By 2025, the public literature had already moved from “can verifiable RL work outside math?” to “how is constraint verification engineered, and does the model generalize to unseen criteria?” That is the kind of evaluation expansion a technical reader should expect after adopting GRPO.
Public frontier practice looks multistage
Public evidence also suggests that frontier practice is multistage rather than “run GRPO once and ship.” DeepSeek-R1 explicitly adds cold-start data before RL, and its official model pages say DeepSeek-R1-Zero showed endless repetition, poor readability, and language mixing despite strong reasoning improvements. OpenAI’s o1 release says performance improves with both train-time RL and test-time compute. Anthropic’s Claude 3.7 Sonnet system card separates in-distribution from out-of-distribution internal harm datasets and notes variability due to manual human grading. Anthropic’s 2026 Sonnet 4.6 system card continues the pattern with broad capability and safety evaluations across coding, reasoning, multimodal, autonomy, and domain-specific risk areas.
DeepSeek’s March 2026 DeepSeek-Math-V2 model card makes the verifier burden explicit: as the generator becomes stronger, labs need to scale verification compute to maintain the generation-verification gap. That is not a formal disclosure of production stacks across labs, so it should be labeled as inference. But the inference is strong: frontier teams appear to treat policy optimization, verifier improvement, test-time compute, and evaluation operations as separate moving parts.
A defensible GRPO claim needs more than a curve
For a team running reasoning RL at moderate or frontier scale, GRPO is most plausible when the task family has highly automatable outcome checks and the actor-critic memory cost is a real bottleneck. But the minimum evidence package for a defensible claim is broader than “loss went down and AIME went up.” It should include verifier QA with recall and adversarial-hacking checks, reward-source separation between correctness and formatting, pass@1 plus pass@k or majority-vote reporting at matched compute budgets, contamination-resistant public benchmarks plus private or unpublished holdouts, and human-audited slices targeted at the exact places where the verifier is least trustworthy or the benchmark is most gameable.
Open questions remain. The public DeepSeek reports still do not fully expose the recipe behind post-release improvements, and the DeepSeek-R1-0528 model card attributes benchmark jumps to added compute and algorithmic optimization mechanisms without giving the community a new end-to-end training description. The best way to normalize group rewards in long-CoT RL is still unsettled, as DAPO and Dr. GRPO demonstrate. The relationship between outcome-based RL, chain-of-thought faithfulness, and monitorability is also unsettled: OpenAI finds chain-of-thought monitoring useful against frontier reward hacks, while Anthropic finds that reasoning models often do not faithfully expose the hacks they exploit.
The practical takeaway is therefore straightforward. GRPO is best understood as a credible simplification of PPO-style reasoning-model RL on the optimization side, not as a simplification of reasoning-model post-training as a whole. It changes how advantages are estimated and what memory footprint the trainer carries. It does not measure reasoning faithfulness. It does not validate verifiers. It does not immunize reported benchmark gains against contamination. It does not tell a team whether deployment quality comes from better single-sample reasoning, better search under test-time compute, or a hackable reward channel.
OpenTrain can support specialist human review for verifier calibration, adversarial slices, rubric audits, and hard-eval adjudication inside the stack a team already owns. Start with managed service when the bottleneck is operating the review loop, or post a job when the team wants to hire directly.
Sources
- DeepSeekMath
- DeepSeek-R1
- DAPO
- Understanding R1-Zero-Like Training
- From Accuracy to Robustness
- ProcessBench
- PRMBench
- THINKPRM
- Self-Consistency Improves Chain of Thought Reasoning
- HumanEval
- Pass@k Training
- MathArena
- Reasoning or Memorization?
- LiveCodeBench
- FrontierMath
- FrontierMath Tiers 1-4 update
- Humanity’s Last Exam
- SWE-bench Verified
- Tulu 3
- Learning to reason with LLMs
- Claude 3.7 Sonnet system card
- Monitoring Reasoning Models for Misbehavior
- Reasoning models do not always say what they think
- DeepSeek-Math-V2
- VerIF
- Generalizing Verifiable Instruction Following
- DeepMath-103K
- DeepSeek-R1-0528