AI Red Teaming as an Evaluation Data Problem

AI red teaming is useful when adversarial findings become reproducible evaluation data: threat models, rubrics, adjudication, leakage controls, and routing decisions.
What is red teaming in AI, really?
If you already run LLM evaluations, the useful answer is not “trying to jailbreak a model.” The useful answer is structured adversarial discovery that produces evidence. AI red teaming matters when it helps you design better evaluation data, refusal tests, harm rubrics, and release decisions. It matters less when it becomes a gallery of viral prompts. [1]
The distinction matters because the field uses several related terms loosely. Traditional cyber red teaming is adversary emulation against an enterprise’s security posture. AI red-teaming is a structured effort to find flaws and vulnerabilities in AI systems, often with developer collaboration. An eval is narrower: give the system an input, apply grading logic, and measure whether it did the thing you care about. Safety testing and pre-deployment TEVV are broader umbrellas that can include red teaming, field testing, public feedback, and formal evaluations. [1]
How AI red teaming differs from cyber red teaming and standard evals.
| Practice | Unit of analysis | Goal | Typical output | Wrong inference to avoid |
|---|---|---|---|---|
| Cyber red team | Organization, network, product, or security program. | Emulate adversaries against a security posture. | Attack path, exploit narrative, remediation list. | A cyber exercise is not automatically an AI evaluation. |
| AI red teaming | AI model, application, scaffold, or deployment surface. | Discover flaws, vulnerabilities, and harmful behaviors. | Findings, prompts, transcripts, severity notes. | A viral jailbreak is not automatically reliable measurement. |
| Model evaluation | Defined input, system setup, grader, and metric. | Measure whether a target behavior occurs under a stated harness. | Scores, labels, confidence intervals, error slices. | An eval score only supports the claim its harness can support. |
| Safety testing and TEVV | Whole lifecycle of evidence and assurance activities. | Combine tests, field evidence, risk thresholds, and review. | Risk register, acceptance evidence, monitoring plan. | A red-team round alone does not prove a system is safe. |
Cyber red team
- Unit of analysis
- Organization, network, product, or security program.
- Goal
- Emulate adversaries against a security posture.
- Typical output
- Attack path, exploit narrative, remediation list.
- Wrong inference to avoid
- A cyber exercise is not automatically an AI evaluation.
AI red teaming
- Unit of analysis
- AI model, application, scaffold, or deployment surface.
- Goal
- Discover flaws, vulnerabilities, and harmful behaviors.
- Typical output
- Findings, prompts, transcripts, severity notes.
- Wrong inference to avoid
- A viral jailbreak is not automatically reliable measurement.
Model evaluation
- Unit of analysis
- Defined input, system setup, grader, and metric.
- Goal
- Measure whether a target behavior occurs under a stated harness.
- Typical output
- Scores, labels, confidence intervals, error slices.
- Wrong inference to avoid
- An eval score only supports the claim its harness can support.
Safety testing and TEVV
- Unit of analysis
- Whole lifecycle of evidence and assurance activities.
- Goal
- Combine tests, field evidence, risk thresholds, and review.
- Typical output
- Risk register, acceptance evidence, monitoring plan.
- Wrong inference to avoid
- A red-team round alone does not prove a system is safe.
Definitions synthesized from NIST and model-evaluation guidance.
That makes demo jailbreaks a weak unit of governance. NIST warns that jailbreak and prompt-engineering tests may not systematically assess validity or reliability. Microsoft frames red teaming as a way to expose harms and understand a risk surface, not as a replacement for systematic measurement. AISI makes the same point from the evaluator side: exploratory tests can signpost concerns, but stronger claims require better elicitation, grading, and mapping between results and risk thresholds. [2]
The practical goal is simple: turn discovery into cases you can replay, label, audit, and route.
Threat model first, jailbreak gallery last
If a red-team program starts by asking people to “go break the model,” it will usually produce colorful examples and weak measurement. Reverse the order. Start by stating the claim the evidence should support: capability elicitation, safeguard robustness, or comparison between systems under a shared setup. Then define the harness, tools, and budget that make the claim meaningful.
OpenAI’s third-party evaluation guidance is direct on this point: scores are only interpretable if the report describes what claim the setup supports, how the system was elicited, and what validity checks were performed. [3]
A threat model for AI red teaming should name the actor, target behavior, attack surface, and downstream harm. AISI argues that evaluations should align to explicit risk models and cover relevant paths to harm. Microsoft describes an internal ontology that tracks actors, tactics, weaknesses, and downstream impacts because raw findings are too messy to reason about without a shared structure. [4]
For most teams, “attack surface” should not stop at the prompt box. If the deployed system has retrieval, tools, long context, multimodal inputs, connectors, or agent scaffolding, those surfaces belong in scope. The harness changes what the system can do. OpenAI emphasizes that surrounding scaffolds can materially change performance, especially for agentic systems. Microsoft similarly recommends testing both the base model and application layer, ideally through the production UI when possible. [3][5]
This is where prompt-only theater starts: testing user text against a stripped-down chat endpoint, then treating the result as evidence about a deployed product. That can miss indirect prompt injection, unsafe tool use, stateful multi-turn escalation, retrieval-dependent failures, and environment-specific behavior. The problem is not that prompt-only tests are useless. The problem is treating them as if they measured the whole system.
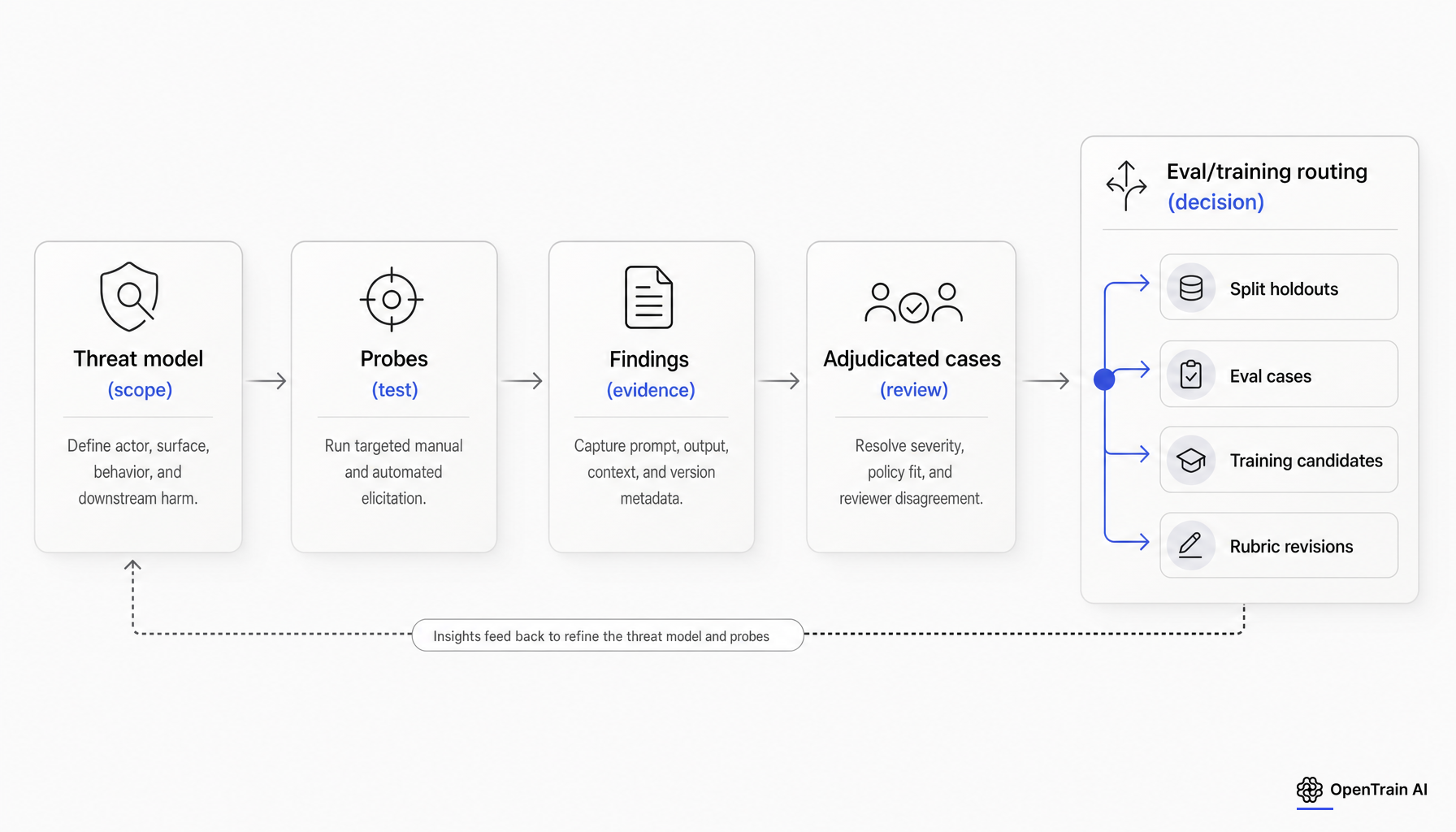
Sampling, severity, and adjudication
Sampling is where red teaming becomes evaluation design. Google recommends diverse and representative inputs across product policies, use cases, failure modes, lexical variety, and semantic variety. Microsoft recommends starting with open-ended testing to discover harms, then moving into guided rounds based on an evolving harm list. In practice, a sample should not be a public jailbreak list plus a few improvised prompts. It should be a planned slice across harm categories, user intents, surfaces, languages, and plausible elicitation strategies. [6]
Severity also needs structure before the program scales. NIST frames risk as a combination of likelihood and consequence. For red-team labeling, that is a starting point, not a finished rubric. Most teams also need dimensions such as harm type, actionability, reproducibility, realism, and whether the behavior persists after ordinary safeguards. This rubric is editorial synthesis grounded in NIST risk framing and evaluation practice, not a quoted standard. [2]
Adjudication is where teams often fail quietly. Google notes that humans may annotate troubling content differently and recommends clear guidelines or templates for raters. OpenAI recommends clear rubrics, example score levels, pass-fail thresholds, and consensus aggregation when multiple reviewers are used. For high-severity or policy-ambiguous cases, treat human disagreement as a signal about the measurement system, not just annotator noise. [6][7]
A useful operating rule follows: if a finding is high severity, policy-ambiguous, or domain-specialized, escalate it from single-review labeling to expert adjudication. If reviewers disagree on whether the model violated policy, the case should usually drive rubric revision before it drives post-training. That recommendation is synthesis, but it follows from the cited guidance on rubric clarity, calibration, and human review.
Split human and automated work on purpose
Automation helps most when the job is breadth, refresh, and weak-signal detection. Anthropic’s model-written evaluations work showed that models can help generate many relevant eval items quickly, with high crowdworker agreement on labels in that setting. AISI argues that automated capability evaluations are scalable enough to cover a large part of a concerning capability surface. Google also recommends starting with seed examples and expanding them synthetically when existing datasets are insufficient. [8][4][6]
The same sources also define the limits. AISI says automated testing does not mirror real-world usage and should not, on its own, support strong conclusions. Google warns that classifier accuracy can be low for loosely defined constructs. OpenAI says there is more to evals than scores and recommends calibrating automated scoring against human judgment. [4][6][7]
Automated probes are strong at three things. First, they improve coverage by generating more lexical and semantic variants than a small human team can produce. Second, they make regression testing cheap once a case becomes a reusable eval. Third, they let teams attack a system at scale with repeated sampling, which matters because some jailbreak classes improve with more attempts. Anthropic’s many-shot work is one example of long context creating new failure modes. [9]
Tooling now reflects this division of labor. Microsoft PyRIT is a model-agnostic framework for probing multimodal systems and reusing composable red-team building blocks. AISI Inspect supports multi-turn dialog, agent scaffolds, model grading, and detailed logs. Those tools are useful because red-team findings need to become analyzable evaluation artifacts, not loose notes. [10][11]
Humans remain necessary where the question is not only “did policy fail?” but “what actually matters here?” Microsoft is direct: medicine, cybersecurity, CBRN, cross-cultural harms, and psychosocial harms require subject-matter judgment. AISI similarly describes expert red teaming as more naturalistic and open-ended than automated tests. [12][4]
LLM judges need the same skepticism. OpenAI recommends pairwise or pass-fail formats, clear rubrics, and validation against human labels because judge models can be biased by answer order and response length. Use LLM judges like measurement instruments: calibrate them, check for drift, and audit them periodically. Do not give them final authority on specialist harms or ambiguous policy boundaries. [7]
Where automation helps, and where humans still matter.
| Method | Best use | Main advantage | Main blind spot | Human review needed? |
|---|---|---|---|---|
| Automated probes | Broad repeated attempts across known tactics. | Scales coverage and refresh cadence. | Can miss realistic product context and domain harm. | Yes, for severe or ambiguous cases. |
| Model-generated variants | Expanding seed examples across wording and semantics. | Finds lexical and semantic neighbors quickly. | Can overfit to easy variations. | Yes, for label calibration and novelty checks. |
| Classifiers | Pre-screening large output volumes. | Cheap triage and monitoring. | Low accuracy on loose constructs. | Yes, for policy and severity decisions. |
| LLM judges | Pass-fail or pairwise scoring with clear rubrics. | Fast reusable scoring when calibrated. | Order, length, style, and domain bias. | Yes, with periodic human audits. |
| Scripted regression suites | Rerunning known cases after model or policy changes. | Stable replay and diffing. | Measures yesterday's failure modes. | Yes, when regressions are high risk. |
| Human domain experts | Medicine, security, CBRN, cultural, legal, or psychosocial harms. | Context and consequence judgment. | Limited throughput and disagreement without rubrics. | They are the review path. |
Automated probes
- Best use
- Broad repeated attempts across known tactics.
- Main advantage
- Scales coverage and refresh cadence.
- Main blind spot
- Can miss realistic product context and domain harm.
- Human review needed?
- Yes, for severe or ambiguous cases.
Model-generated variants
- Best use
- Expanding seed examples across wording and semantics.
- Main advantage
- Finds lexical and semantic neighbors quickly.
- Main blind spot
- Can overfit to easy variations.
- Human review needed?
- Yes, for label calibration and novelty checks.
Classifiers
- Best use
- Pre-screening large output volumes.
- Main advantage
- Cheap triage and monitoring.
- Main blind spot
- Low accuracy on loose constructs.
- Human review needed?
- Yes, for policy and severity decisions.
LLM judges
- Best use
- Pass-fail or pairwise scoring with clear rubrics.
- Main advantage
- Fast reusable scoring when calibrated.
- Main blind spot
- Order, length, style, and domain bias.
- Human review needed?
- Yes, with periodic human audits.
Scripted regression suites
- Best use
- Rerunning known cases after model or policy changes.
- Main advantage
- Stable replay and diffing.
- Main blind spot
- Measures yesterday's failure modes.
- Human review needed?
- Yes, when regressions are high risk.
Human domain experts
- Best use
- Medicine, security, CBRN, cultural, legal, or psychosocial harms.
- Main advantage
- Context and consequence judgment.
- Main blind spot
- Limited throughput and disagreement without rubrics.
- Human review needed?
- They are the review path.
Based on AISI tiering, Google adversarial testing, OpenAI eval practices, Anthropic model-written evals, and Microsoft red teaming lessons.
A good operational split is simple. Let automation generate candidate attacks, expand seed sets, pre-label obvious cases, cluster duplicates, and rerun regressions. Let humans define the harm list, review uncertain or severe cases, audit judge quality, and interpret what the system failure means for the product or model. That division is synthesis grounded in the sources above.
Treat findings as data objects, not anecdotes
If red-team outputs need to become reusable eval data, capture more than the prompt and final answer. Microsoft recommends recording at least the date surfaced, unique identifier, input prompt, and output details. Google recommends annotating outputs into failure modes and harms. Inspect’s log model shows what a more mature representation can preserve: input, sample metadata, scores, errors, messages, and event traces at multiple levels of granularity. [5][6][11]
For applied teams, the minimal useful schema is usually larger. In addition to prompt and response, keep model version, system prompt version or hash, tool configuration, retrieval context or references, attack method, policy category, refusal status, reviewer label, severity label, rationale, adjudication status, case cluster, and routing status. This exact field list is synthesis, but it is a practical extension of current guidance on structured capture, metadata, and scoring.
Duplicate handling matters more than most teams expect. Google recommends avoiding duplication and noisy multi-label examples when generating adversarial datasets. Without deduplication, “top failure modes” often collapse into a few viral attack templates, which then bias both mitigation work and training data. Keep a notion of canonical case versus paraphrase cluster, and report both raw count and unique attack-family count. The canonical-versus-cluster recommendation is synthesis, but the need for uniqueness and careful composition comes directly from Google’s guidance. [6]
A reusable red-team case schema for evaluation and post-training loops.
| Field | Why it matters | Training-safe? | Holdout-safe? | Notes |
|---|---|---|---|---|
| Case ID | Keeps review, reruns, and remediation traceable. | Yes | Yes | Stable IDs should survive paraphrase clustering. |
| Prompt/input | Defines the elicitation artifact. | Sometimes | Yes | Exact holdout prompts should not later become training examples. |
| Model output | Captures the observed behavior. | Sometimes | Yes | Include refusals, partial completions, and tool outputs. |
| Model version | Prevents false comparisons across changing systems. | Yes | Yes | Record model, checkpoint, and relevant release channel. |
| System prompt hash | Links behavior to instructions without exposing secrets. | Yes | Yes | Use hashes or controlled references when prompts are sensitive. |
| Tool/retrieval context | Shows what the deployed harness made available. | Sometimes | Yes | Critical for RAG, tool use, long context, and agent tests. |
| Attack method | Supports coverage and deduplication. | Yes | Yes | Examples include direct jailbreak, indirect injection, role play, or multi-turn escalation. |
| Policy category | Connects the finding to the rubric. | Yes | Yes | Revise categories when adjudication exposes ambiguity. |
| Refusal status | Separates unsafe compliance from over-refusal. | Yes | Yes | Do not collapse all refusals into success. |
| Reviewer label | Defines the human or calibrated judge decision. | Yes | Yes | Track reviewer type and calibration state. |
| Severity | Prioritizes remediation and release gates. | Yes | Yes | Severity dimensions are synthesis, not a universal standard. |
| Rationale | Makes later audits possible. | Yes | Yes | Short rationales are better than opaque class labels. |
| Adjudication status | Separates single-review labels from resolved cases. | Yes | Yes | High-severity and disputed cases need escalation. |
| Cluster ID | Prevents duplicate prompts from dominating reports. | Yes | Yes | Report raw count and unique attack-family count separately. |
| Routing status | Prevents leakage between training and measurement. | Yes, when routed to training | Yes, when blocked as holdout | Possible states include training candidate, eval case, blocked holdout, rubric revision, or release evidence. |
Case ID
- Why it matters
- Keeps review, reruns, and remediation traceable.
- Training-safe?
- Yes
- Holdout-safe?
- Yes
- Notes
- Stable IDs should survive paraphrase clustering.
Prompt/input
- Why it matters
- Defines the elicitation artifact.
- Training-safe?
- Sometimes
- Holdout-safe?
- Yes
- Notes
- Exact holdout prompts should not later become training examples.
Model output
- Why it matters
- Captures the observed behavior.
- Training-safe?
- Sometimes
- Holdout-safe?
- Yes
- Notes
- Include refusals, partial completions, and tool outputs.
Model version
- Why it matters
- Prevents false comparisons across changing systems.
- Training-safe?
- Yes
- Holdout-safe?
- Yes
- Notes
- Record model, checkpoint, and relevant release channel.
System prompt hash
- Why it matters
- Links behavior to instructions without exposing secrets.
- Training-safe?
- Yes
- Holdout-safe?
- Yes
- Notes
- Use hashes or controlled references when prompts are sensitive.
Tool/retrieval context
- Why it matters
- Shows what the deployed harness made available.
- Training-safe?
- Sometimes
- Holdout-safe?
- Yes
- Notes
- Critical for RAG, tool use, long context, and agent tests.
Attack method
- Why it matters
- Supports coverage and deduplication.
- Training-safe?
- Yes
- Holdout-safe?
- Yes
- Notes
- Examples include direct jailbreak, indirect injection, role play, or multi-turn escalation.
Policy category
- Why it matters
- Connects the finding to the rubric.
- Training-safe?
- Yes
- Holdout-safe?
- Yes
- Notes
- Revise categories when adjudication exposes ambiguity.
Refusal status
- Why it matters
- Separates unsafe compliance from over-refusal.
- Training-safe?
- Yes
- Holdout-safe?
- Yes
- Notes
- Do not collapse all refusals into success.
Reviewer label
- Why it matters
- Defines the human or calibrated judge decision.
- Training-safe?
- Yes
- Holdout-safe?
- Yes
- Notes
- Track reviewer type and calibration state.
Severity
- Why it matters
- Prioritizes remediation and release gates.
- Training-safe?
- Yes
- Holdout-safe?
- Yes
- Notes
- Severity dimensions are synthesis, not a universal standard.
Rationale
- Why it matters
- Makes later audits possible.
- Training-safe?
- Yes
- Holdout-safe?
- Yes
- Notes
- Short rationales are better than opaque class labels.
Adjudication status
- Why it matters
- Separates single-review labels from resolved cases.
- Training-safe?
- Yes
- Holdout-safe?
- Yes
- Notes
- High-severity and disputed cases need escalation.
Cluster ID
- Why it matters
- Prevents duplicate prompts from dominating reports.
- Training-safe?
- Yes
- Holdout-safe?
- Yes
- Notes
- Report raw count and unique attack-family count separately.
Routing status
- Why it matters
- Prevents leakage between training and measurement.
- Training-safe?
- Yes, when routed to training
- Holdout-safe?
- Yes, when blocked as holdout
- Notes
- Possible states include training candidate, eval case, blocked holdout, rubric revision, or release evidence.
Field list combines tool docs and operational guidance; training/holdout routing is editorial synthesis.
Decide what each finding becomes before you train on it
This is the core operational question, and the answer should be written down before the first post-training meeting.
A red-team case can become at least five different things: a training example, a reusable eval case, a blocked holdout, a policy or rubric revision, or release-gate evidence. Current primary sources support the need for these separate lanes, even though they do not package them into one standard workflow. OpenAI warns not to leak eval data into reinforcement fine-tuning, describes production-derived evaluations that are refreshed periodically, and emphasizes validity hazards such as contamination and reward hacking. AISI similarly argues for predefined thresholds and repeated testing over the model lifecycle. [13][14][3][4]
A case is a reasonable training candidate when the label is stable, the failure is representative of realistic use, the policy boundary is clear, and the example is not reserved for future measurement. Anthropic’s earlier red-teaming work found that using red-team data in safety methods reduced susceptibility to the attack corpus studied. That is why teams are tempted to train on everything. It is also why leakage control matters: if those same cases are later used as evidence of progress, the measurement is compromised. [15]
Keep a case out of training when it is needed as a holdout, when it resembles a public benchmark or likely future benchmark, when the label is disputed, or when the exploit is so case-specific that training on it would mostly teach the model to memorize a patch. Anthropic’s BrowseComp contamination note shows how public leakage can inflate results, and OpenAI’s SWE-bench Verified analysis shows the same failure pattern at benchmark scale. In both cases, the lesson is the same: the same artifact cannot be both training material and honest measurement evidence. [16][17]
Practical routing rule: if a case exposed a novel failure mode, block it into a holdout bucket first. Only after you refresh the holdout and prove the fix on new cases should you consider moving variants of that failure pattern into training. That rule is synthesis, but it respects current leakage guidance from provider and evaluator sources.
A small-team operating model that does not pretend to guarantee safety
For a small AI team, the goal is not “cover everything.” The goal is to create a loop that produces evidence you will still trust after the model changes.
Start with one concrete deployment-relevant threat model, one narrow product surface, and one manual discovery round. Use diverse testers if possible, but at minimum include someone who understands the domain harm and someone who can think adversarially about the system interface. Microsoft recommends diverse testers and explicit assignments to harms or features; Google recommends starting from seed examples and expanding them carefully; OpenAI recommends building evals early, logging everything, and calibrating automation with human labels. [5][6][7]
Then freeze the first tranche of high-confidence findings into a held-out adversarial eval set. Do not fine-tune on those exact cases. Build simple regression runs around them, even if the grader is pass-fail with human audit. Once that works, add a second lane for training candidates and keep the split clean. OpenAI’s evaluation guidance repeatedly emphasizes held-out data, non-overlap, and separate training sets for post-training loops. [13][7]
After that, automation becomes worth the effort. Use model-generated expansions, classifiers, or LLM judges to widen coverage and reduce review cost, but only in areas where you have established what a correct label means. AISI’s tiered approach is a useful template: let lighter automated tests find concerns quickly, then escalate to bespoke elicitation and expert review when the signal matters. [4]
None of this proves a system is safe. That is the wrong promise. A good red-team loop gives you cases you can replay, labels you can defend, holdouts you did not train on, and enough structure to tell whether a mitigation changed the model or only patched a demo prompt.
OpenTrain can help teams hire red-teamers, domain reviewers, and evaluation specialists for that work. Use the LLM judge reliability reference for evaluator calibration, the RLAIF vs RLHF guide for automation boundaries, the PRM vs ORM reference for measurement-target design, and the RLHF scoping guide for review-loop planning. When the bottleneck is staffing the review loop, post a job.
Sources
- NIST glossary: red team; NIST glossary: artificial intelligence red-teaming; NIST AI RMF Generative AI Profile
- NIST AI RMF Generative AI Profile
- OpenAI: Trustworthy third-party evaluations foundations
- AISI: Early lessons from evaluating frontier AI systems
- Microsoft Learn: Planning red teaming for LLMs
- Google: Adversarial Testing for Generative AI
- OpenAI: Evaluation best practices
- Anthropic: Discovering Language Model Behaviors with Model-Written Evaluations
- Anthropic: Many-shot jailbreaking
- PyRIT: A Framework for Security Risk Identification and Red Teaming in Generative AI Systems
- Inspect AI docs
- Microsoft Research: Lessons From Red Teaming 100 Generative AI Products; Microsoft Security Blog summary
- OpenAI cookbook: Eval-driven system design
- OpenAI: Production evaluations
- Anthropic: Red Teaming Language Models to Reduce Harms
- Anthropic: Eval awareness and BrowseComp
- OpenAI: Why we no longer evaluate on SWE-bench Verified