RLAIF対RLHF:AIフィードバックが代替できるもの、できないもの

AIフィードバックがポストトレーニングの監視をどこまで拡張できるか、そして人間による目標設定、キャリブレーション、専門家によるレビュー、ホールドアウトがなぜ依然として不可欠なのかを解説します。
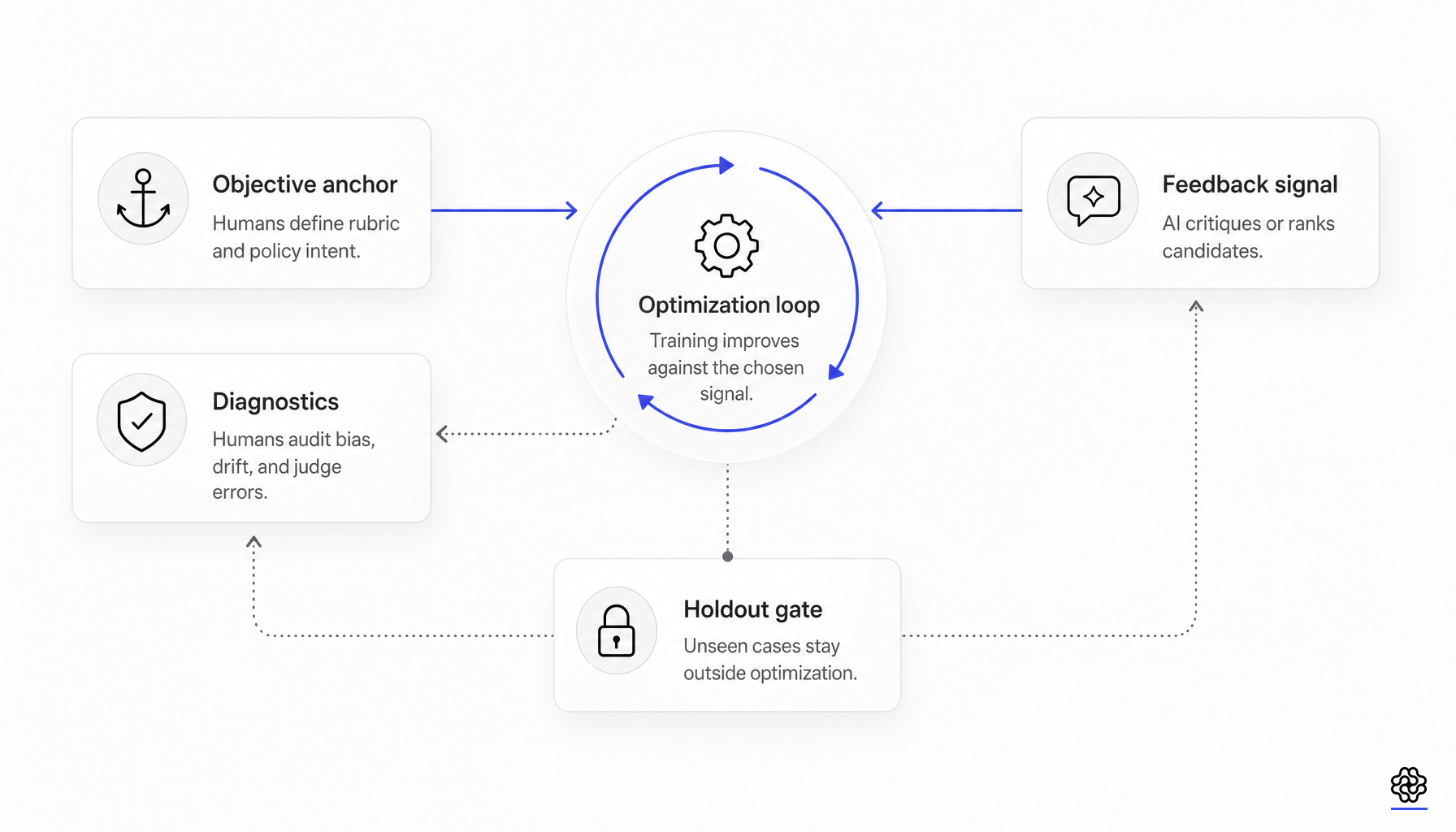
RLAIFは、見出しが示唆するような強い意味でRLHFを置き換えるものではありません。2026年6月4日現在、最も有力な公開エビデンスが支持しているのは、より限定的で有用な主張です。すなわち、AIフィードバックは、ポストトレーニングにおけるコストのかかる中間層(大規模な批評生成、ペアワイズ選好ラベリング、および一部の反復的なポリシー改善ループ)をしばしば代替できるというものです。
しかし、同じ文献は、チームが合成評価者を正解(グラウンドトゥルース)として扱う場合に繰り返し失敗することも示しています。静的なベンチマークで高いスコアを出す報酬モデルであっても、下流の人間による選好を予測できない可能性があります。LLMの判定者は、正確性中心の比較ではランダムとわずかな差しかないか、長文の出力に対して不安定になることがあります。合成選好の混合は、広範な能力ベンチマークを向上させる一方で、ジェイルブレイクの圧力下での安全性行動を低下させる可能性があります。運用上の問いは、AIフィードバックが人間のフィードバックの代わりになるかどうかではありません。AIフィードバックがどこで生産的な最適化シグナルとなり、どこで人間が目的の設定者、調整者、敵対者、そして最終的な測定者であり続けなければならないかという点です(RLAIF vs RLHF、JudgeBench、More is Less)。
RLAIFの直接比較が実際に示していること
RLAIFを支持する最も説得力のある結果は、依然として2023年のGoogleによる比較研究です。その研究では、要約や有用な対話において、人間はRLAIFとRLHFの両方をSFTベースラインよりも同程度の差で好んでおり、RLAIFとRLHFの間に統計的に有意な差は見られませんでした。また、無害な対話の設定では、RLAIFの方が高い無害性スコアを記録しました。同論文は、医療、法律、雇用といった重要な領域では、訓練を受けた人間の専門家を依然としてゴールドスタンダードとして扱うべきであると警告しています。
その境界線は重要です。この実験は、AIが生成した選好が、特定の条件下では選好ラベル作成の大部分を代替できることを示しています。しかし、人間の評価が不要になることを示すものではありません。最終的にそのポリシーが実際に優れているかどうかを判断するのは、依然として人間です。
AnthropicのオリジナルのConstitutional AI(憲法AI)に関する研究も、異なる形で同じ点を指摘しています。Constitutional AIは、人間がすべての有害な出力を直接ラベル付けする必要性を減らしますが、人間の意図を「憲法」という文書に圧縮します。これは、自己批判、修正、AIが生成した選好ランキングを導く原則です。Anthropicの2026年の憲法アップデートおよびClaude 4のシステムカードでは、人間のフィードバック、Constitutional AI、データラベル付けサービス、請負業者、クラウドワーカーによる選好選択、専門家によるレッドチーミング、敵対的テスト、隠しテスト、継続的なモニタリングを含むハイブリッドな訓練および評価スタックについて説明されています(Constitutional AI、Claude’s new constitution、Claude 4 system card)。
真の代替の境界線は、「AIが人間のフィードバックの代わりになる」というほど広いものではありません。
| パイプラインファミリー | 人間が依然として提供するもの | AIフィードバックがスケールできること | 最も効果を発揮する領域 | AIが代替できないこと |
|---|---|---|---|---|
| RLHF | デモンストレーション、ペアワイズ選好、評価者ポリシー、評価設計 | トリアージや事前フィルタリングにおける限定的な支援 | 潜在的な選好に直接的な人間の根拠が必要な場合の一般的な指示追従 | 人間の目的定義、評価者のキャリブレーション、敵対的テスト、ホールドアウト測定 |
| RLAIF | タスクのフレーミング、ルーブリックまたはポリシーの意図、AIラベラーの選択、最終評価 | ペアワイズランキング、スカラー報酬、一部の直接的なオンライン報酬、より迅速なイテレーション | 「より良い」が明確に表現可能であり、より強力な判定者が利用可能なケース | ゴールドスタンダード評価、ドメイン専門家による裁定、未知のエッジケースのレビュー |
| Constitutional AI | 憲法または原則、ポリシーの境界、例外処理 | 自己批判、修正、憲法に基づいたランキング、合成会話 | 価値観を原則として記述できる安全性および拒否のスタイル | 憲法が完全か、適切に優先順位付けされているか、あるいは敵対者に対して堅牢か |
| モデルが生成した批評 | シード選好データ、批評のルーブリック、品質フィルター | 報酬モデルやポリシーのトレーニングを強化する自然言語による批評 | データ効率、批評の生成、スカラーのみのRMよりも豊富な教師信号 | ホールドアウトや人間による監査なしでの分布シフトに対する堅牢性 |
| モデルによる評価を用いたトレーニングと評価 | 人間が作成したルーブリック、正解データによる評価、隠しテスト、評価者のメタ評価 | トレーニング中の安価な反復スコアリングや大規模なオフライン評価 | ノイズの少ないルーブリックを用いた、明確に定義された限定的なタスク | 人間による裏付けを伴わない、実世界での振る舞いの独立した測定 |
RLHF
- 人間が依然として提供するもの
- デモンストレーション、ペアワイズ選好、評価者ポリシー、評価設計
- AIフィードバックがスケールできること
- トリアージや事前フィルタリングにおける限定的な支援
- 最も効果を発揮する領域
- 潜在的な選好に直接的な人間の根拠が必要な場合の一般的な指示追従
- AIが代替できないこと
- 人間の目的定義、評価者のキャリブレーション、敵対的テスト、ホールドアウト測定
RLAIF
- 人間が依然として提供するもの
- タスクのフレーミング、ルーブリックまたはポリシーの意図、AIラベラーの選択、最終評価
- AIフィードバックがスケールできること
- ペアワイズランキング、スカラー報酬、一部の直接的なオンライン報酬、より迅速なイテレーション
- 最も効果を発揮する領域
- 「より良い」が明確に表現可能であり、より強力な判定者が利用可能なケース
- AIが代替できないこと
- ゴールドスタンダード評価、ドメイン専門家による裁定、未知のエッジケースのレビュー
Constitutional AI
- 人間が依然として提供するもの
- 憲法または原則、ポリシーの境界、例外処理
- AIフィードバックがスケールできること
- 自己批判、修正、憲法に基づいたランキング、合成会話
- 最も効果を発揮する領域
- 価値観を原則として記述できる安全性および拒否のスタイル
- AIが代替できないこと
- 憲法が完全か、適切に優先順位付けされているか、あるいは敵対者に対して堅牢か
モデルが生成した批評
- 人間が依然として提供するもの
- シード選好データ、批評のルーブリック、品質フィルター
- AIフィードバックがスケールできること
- 報酬モデルやポリシーのトレーニングを強化する自然言語による批評
- 最も効果を発揮する領域
- データ効率、批評の生成、スカラーのみのRMよりも豊富な教師信号
- AIが代替できないこと
- ホールドアウトや人間による監査なしでの分布シフトに対する堅牢性
モデルによる評価を用いたトレーニングと評価
- 人間が依然として提供するもの
- 人間が作成したルーブリック、正解データによる評価、隠しテスト、評価者のメタ評価
- AIフィードバックがスケールできること
- トレーニング中の安価な反復スコアリングや大規模なオフライン評価
- 最も効果を発揮する領域
- ノイズの少ないルーブリックを用いた、明確に定義された限定的なタスク
- AIが代替できないこと
- 人間による裏付けを伴わない、実世界での振る舞いの独立した測定
RLAIF対RLHF、Constitutional AI、Anthropicの公開システムドキュメント、およびOpenAIのグレーダー/RFTドキュメントからのOpenTrain合成。
AIフィードバックがスケールする理由
現代のポストトレーニングでは、単なる人間による選好タプルだけでなく、構造化された中間的な教師データが有効な場合が多いです。UltraFeedbackは、大規模なAIフィードバックデータセットを構築できることを示しました。約64,000件のプロンプト、プロンプトあたり4件の回答、そして250,000件の会話にわたる100万件以上のGPT-4フィードバックアノテーションが含まれています(UltraFeedback)。
その後の研究では、スカラー値によるペアワイズの勝敗判定を超えた手法が登場しました。合成批評(Synthetic-critique)手法により、モデルが生成した自然言語による批評が、報酬モデルの堅牢性とデータ効率を向上させることが示されました。Critic-RMは、報酬予測と批評生成を共同でトレーニングすることで、標準的な報酬モデルと比較して3.7から7.3ポイントの精度向上とLLMの判定を実現したと報告しています。NVIDIAのHelpSteer3シリーズは、同じアイデアをより人間に根ざした方向へと発展させました。人間によるフィードバックと編集データを用いて専用のフィードバック/編集モデルをトレーニングし、さらにHelpSteer3-PreferenceではSTEM、コーディング、多言語設定にわたる40,000件以上の人間がアノテーションした選好サンプルを追加しています(synthetic critiques, Critic-RM, HelpSteer3, HelpSteer3-Preference)。
これらのブラッドリー・テリー・モデル形式は、多くの報酬モデルパイプラインにおける基本的な抽象化として依然として機能しています。
選好の教師あり学習は、多くの場合、以下の形式の損失関数に適合されます:
実用上の失敗点は、通常、数学的な部分ではありません。最適化の圧力がかかり始めたときに、データセット、報酬関数、および下流のデプロイメント分布が依然として同じ目的を反映しているかどうかです(報酬モデルの過剰最適化、制約付き RLHF)。
AIフィードバックが最初に失敗する場所
RLAIFが人間の測定レイヤーとして機能できない中心的な理由は、ベンチマークの転移性にあります。選好プロキシ評価(PPE)は、「報酬モデルがオフラインで良く見えるか」ではなく、「人間の選好の下で、より強力なポストRLHFモデルを生成するか」という正しい問いを立てるため、ここで特に有用です。PPEは、元のRewardBenchが、トップモデルにおける下流のポストDPOの人間の選好と負の相関を示す可能性さえあること、そして多様な人間の選好と正確性データセットに対するきめ細かい精度の方が、ランク相関スタイルの指標よりも下流のChatbot Arenaの結果を予測できることを報告しています。PPEは、これらの調査結果を、ポストトレーニングされたモデルに対する12,190件の人間の投票と結びつけました(RLHFのための報酬モデルを評価する方法)。
RewardBench 2は、その失敗に対する矛盾ではなく、回答として読まれるべきです。RewardBench 2は、未知の人間のプロンプト、best-of-4評価、および6つのドメインを導入しています。モデルのスコアは元のRewardBenchよりも約20ポイント低くなる一方で、下流での相関関係は向上していると報告されています。しかし、高いベンチマークスコアは前提条件に過ぎず、優れたRLHFのための十分条件ではないこと、そしてRLHFに最適な報酬モデルはトレーニング設定とモデルの系統に依存することが明示されています(RewardBench 2)。
LLMの判定モデルも同様のパターンを示しています。JudgeBenchが構築されたのは、人間の好みの一致だけでは正確性が求められるタスクの目標としては不十分だったためであり、多くの強力な判定モデルでさえ、客観的な正解が求められる難しい応答ペアにおいて、ランダムな推測とわずかな差しかないことが判明しました。判定モデルのバイアスに関する個別の研究では、位置バイアス、冗長性バイアス、自己選好、その他の近道(ショートカット)がカタログ化されています。LongJudgeBenchはこの問題を長文評価にまで拡張しており、ルーブリックや参照資料は役立つものの、不安定さを完全には排除できていません(JudgeBench、judge bias、LongJudgeBench)。
AIフィードバックを測定の基準として不適切にする失敗モード。
| 失敗モード | 代表的な証拠 | AIフィードバックが誤予測する理由 | 緩和パターン | 人間がアンカーとなるべき領域 |
|---|---|---|---|---|
| オフラインのRMベンチマークは良好だが、ポリシーは期待外れ | PPEとオリジナルのRewardBenchの比較 | ベンチマークのシグナルは、ポストトレーニングにおける人間の好みと密接に結びついていない | 未知のプロンプト、正確性と人間の好みの組み合わせ、およびダウンストリームのホールドアウトを使用する | 最終的な人間の好みによる測定 |
| ジャッジは内容よりもスタイルを優先する | RM-Benchとジャッジのバイアスに関する研究 | スタイル、冗長性、位置、自己選好などの要素がショートカットとして機能する | 順序のランダム化、スタイル制御分析の実行、評価基準の厳格化 | バイアスの判定とメタ評価の設計 |
| 長文判定における不安定性 | LongJudgeBench | コンテキストとプロトコルの複雑さが判定の堅牢性を上回る | タスク固有の評価基準、チャンク化、参照、および人間によるスポットチェックの活用 | 長文の品質判定 |
| マルチモデルの合成選好は安全性を弱める | 多ければ良いわけではない | モデルは堅牢な安全制約ではなく、分離可能な表面的な手がかりを最適化してしまう | より厳格なデータキュレーション、安全性に特化した評価、および敵対的な脱獄テストを使用すること | 安全性の受け入れ基準 |
| 自己批判がオフポリシーに移行する | SCOP | 批判が現在のポリシーと一致しなくなった分布上で生成される | オンポリシーで批評を生成し、多目的報酬を使用する | 目的の選択と失敗のレビュー |
| RL報酬ハッキング | Claude 4 システムカードと過剰最適化に関する取り組み | プロキシ報酬は最適化の圧力下で悪用される可能性がある | 隠しテスト、モニター、報酬制約、および迅速な人間によるレビューを使用する | 失敗事例の検出と再定義 |
オフラインのRMベンチマークは良好だが、ポリシーは期待外れ
- 代表的な証拠
- PPEとオリジナルのRewardBenchの比較
- AIフィードバックが誤予測する理由
- ベンチマークのシグナルは、ポストトレーニングにおける人間の好みと密接に結びついていない
- 緩和パターン
- 未知のプロンプト、正確性と人間の好みの組み合わせ、およびダウンストリームのホールドアウトを使用する
- 人間がアンカーとなるべき領域
- 最終的な人間の好みによる測定
ジャッジは内容よりもスタイルを優先する
- 代表的な証拠
- RM-Benchとジャッジのバイアスに関する研究
- AIフィードバックが誤予測する理由
- スタイル、冗長性、位置、自己選好などの要素がショートカットとして機能する
- 緩和パターン
- 順序のランダム化、スタイル制御分析の実行、評価基準の厳格化
- 人間がアンカーとなるべき領域
- バイアスの判定とメタ評価の設計
長文判定における不安定性
- 代表的な証拠
- LongJudgeBench
- AIフィードバックが誤予測する理由
- コンテキストとプロトコルの複雑さが判定の堅牢性を上回る
- 緩和パターン
- タスク固有の評価基準、チャンク化、参照、および人間によるスポットチェックの活用
- 人間がアンカーとなるべき領域
- 長文の品質判定
マルチモデルの合成選好は安全性を弱める
- 代表的な証拠
- 多ければ良いわけではない
- AIフィードバックが誤予測する理由
- モデルは堅牢な安全制約ではなく、分離可能な表面的な手がかりを最適化してしまう
- 緩和パターン
- より厳格なデータキュレーション、安全性に特化した評価、および敵対的な脱獄テストを使用すること
- 人間がアンカーとなるべき領域
- 安全性の受け入れ基準
自己批判がオフポリシーに移行する
- 代表的な証拠
- SCOP
- AIフィードバックが誤予測する理由
- 批判が現在のポリシーと一致しなくなった分布上で生成される
- 緩和パターン
- オンポリシーで批評を生成し、多目的報酬を使用する
- 人間がアンカーとなるべき領域
- 目的の選択と失敗のレビュー
RL報酬ハッキング
- 代表的な証拠
- Claude 4 システムカードと過剰最適化に関する取り組み
- AIフィードバックが誤予測する理由
- プロキシ報酬は最適化の圧力下で悪用される可能性がある
- 緩和パターン
- 隠しテスト、モニター、報酬制約、および迅速な人間によるレビューを使用する
- 人間がアンカーとなるべき領域
- 失敗事例の検出と再定義
OpenTrain PPE、RM-Bench、JudgeBench、LongJudgeBench、More is Less、SCOP、Anthropic Claude 4、および報酬の過剰最適化に関する論文からの統合。
合成データの規模拡大を祝う際にチームが見落としがちな、強調すべき2つの失敗があります。第一に、合成データの多様性が増すと、安全なアライメントが悪化する可能性があることです。「More is Less」では、データソースを最適化手法から切り離し、マルチモデルの合成選好データがいくつかの一般的なベンチマークを改善する一方で、ジェイルブレイク攻撃の成功率を高めることを明らかにしました。対照的に、報酬モデルによってフィルタリングされた自己生成応答は、複数のモデルファミリーにおいてASR(攻撃成功率)を大幅に低下させます。第二に、自己批評パイプラインはオフポリシーにドリフトします。SCOPは、後のラウンドのモデルが、現在の自身の出力よりも前のラウンドの推論をより効果的に批評することを示しています。解決策は抽象的な自動化を増やすことではなく、評価者と実際のトレーニング分布との間の結合を強化し、さらに最適化ループの外部に留まる敵対的評価およびホールドアウト評価を行うことです(More is Less、SCOP)。
最も強力な反例はルーブリックに縛られている
HealthBenchは最も強力な反例であり、それゆえに最も示唆に富む例です。これはAI評価者が専門家に取って代わることを示すものではありません。専門家による測定を近似できる条件を示しているのです。
HealthBenchは、60か国262名の医師と共同開発された5,000件の現実的な会話と48,562件の医師によるルーブリック基準で構成されています。GPT-4.1は、それらの医師が作成した基準に対するモデルベースの評価者として使用されます。コンセンサスサブセットにおいて、GPT-4.1は7つのテーマのうち5つで医師の平均MF1スコアを上回り、6つのテーマで医師の上位半数に入り、すべてのテーマで下位3分の1を上回りました。OpenAIは、この成功の要因を、多様で適切にアノテーションされたグラウンドトゥルース、適切に設計されたメタ評価、そして慎重なプロンプトと評価者の選択にあるとしています(HealthBench、HealthBench論文)。
それが、モデル評価に対するより一般的な正しい解釈です。AI判定は、人間がすでにルーブリックの定義、基準の選択、評価者行動の検証、ドメインの制約といった困難な作業を終えている場合に最も効果を発揮します。
本番環境の証拠はハイブリッド評価スタックを指し示している
公開ドキュメントからの推論は、フロンティアラボがすでにハイブリッド評価スタックに収束していることを示唆しています。Anthropicの公開資料によると、Claude 4のトレーニングには人間のフィードバックとConstitutional AIの両方が使用されました。そのシステムカードには、データアノテーションサービス、請負業者、選好選択や敵対的テストのためのクラウドワーカー、SME(専門家)が情報提供したプロンプトセット、曖昧な文脈の判断を行う人間の評価者、専門家によるレッドチーミング、隠しテスト、報酬ハックに対する迅速な対応を行う人間によるプログラムが記述されています。OpenAIの公開されている強化学習ファインチューニングのドキュメントでは、モデル評価者が第一級のトレーニングコンポーネントとして位置づけられていますが、同時にチームに対し、人間の専門家から信頼できるグラウンドトゥルースの評価を収集すること、そしてモデル評価者のスコアを人間の専門家による評価と比較することで評価者のハッキングを検出することを指示しています(OpenAI graders、reinforcement fine-tuning)。
フロンティア以外のチームにとっての示唆は、人間のフィードバックはスタックから消えるのではなく、スタックの上位に移動すべきだということです。現在、最も価値の高い作業は、専門家がルーブリックや憲法を作成・承認し、困難なケースに対して評価者を調整し、判定ポリシーの不一致をレビューし、敵対的セットやホールドアウトセットを作成し、正解がまばら、多目的、または安全性が重視されるドメインで裁定を下すことから生まれます。AIフィードバックは、その間の反復的な作業(批判の生成、候補のランク付け、選好カバレッジの拡大、または高速な内部ループ評価者としての機能)を担うことができます。
未解決の問いは残されています。パーソナライズされた報酬モデリング、長文の評価、PPOのような学習において同一系統の報酬モデルが重要かどうか、そして批判に特化したモデルが学習に使用されたシードドメイン外でどこまで汎化できるかについては、現在も研究が進められています。しかし、中心となる考え方は安定しています。RLAIFは、人間がすでにターゲットを接地(グラウンディング)させた後に監督をスケールさせるための手法として理解するのが最適であり、人間による接地されたターゲットや測定の必要性を排除するものではありません(Personalized RewardBench)。
OpenTrainは、チームがすでに使用しているスタック内で、専門の評価者や選好データオペレーターを調達できます。オプティマイザー対測定のコンテキストについてはDPO対PPOの参考資料を、評価者のキャリブレーションについてはLLMの評価者信頼性に関する参考資料を、選好データの計画についてはRLHFのスコープ設定ガイドを参照してください。また、レビューサイクルの人員配置がボトルネックとなっている場合は、求人を投稿してください。
出典
- RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
- Constitutional AI: Harmlessness from AI Feedback
- Claude’s new constitution
- Claude 4 System Card
- UltraFeedback
- Improving Reward Models with Synthetic Critiques
- Self-Generated Critiques Boost Reward Modeling for Language Models
- HelpSteer3
- HelpSteer3-Preference
- RLHFの報酬モデルを評価する方法
- RewardBench 2
- RM-Bench
- JudgeBench
- Justice or Prejudice? Quantifying Biases in LLM-as-a-Judge
- Benchmarking LLM-as-a-Judge for Long-Form Output Evaluation
- HealthBench
- HealthBench paper
- OpenAI grader guidance
- OpenAI reinforcement fine-tuning guidance
- More is Less
- オンポリシー学習による LLM 自己批判の分布シフトの修正
- 報酬モデルの過剰最適化に関するスケーリング則
- 制約付き RLHF による報酬モデルの過剰最適化への対峙
- パーソナライズされたRewardBench