Direct Preference Optimization対PPO:RLHF後の比較

RLHF後にDPOが何を変えるのか、PPOとオンラインデータが依然として重要である理由、そしてなぜ選好の測定が依然として困難な課題であるのかについての技術リファレンス。
Direct Preference Optimizationは、RLHFを完全に置き換えたわけではありません。多くのチームがRLHFに関連付けていたプロセスの大部分、つまり明示的な報酬モデルを学習させ、それに対してPPOを実行するという部分を置き換えたのです。より強力な解釈は、より狭義であり、より有用です。DPOは測定を簡素化する以上に、最適化を大幅に簡素化します。
オフラインの選好データが不十分な場合、評価者にバイアスがある場合、報酬モデルの汎化がうまくいかない場合、あるいはラベルにノイズが多い場合、PPOループの欠如が根本的な問題ではありません。根本的な問題は、測定された選好目的が、チームが実際に重視する挙動に転移するかどうかです(DPO、InstructGPT、helpful-harmless RLHF)。
目的は変わっても、エビデンスの負担は変わらない
PPO形式のRLHFとDPOは、関連する選好学習目標に対する異なる最適化インターフェースです。どちらも、基礎となるデータや評価スタックが十分であることを証明するものではありません。
従来のPPOベースのRLHFでは、ポリシーは参照ポリシーの近くに留まりながら、学習された報酬に対して最適化されます:
一方、DPOは選択された応答と拒否された応答のペアワイズ損失を最適化し、参照モデルをアンカーとして保持します。
この置き換えは実質的なものです。これにより、ポリシー最適化の前提条件としての明示的な報酬モデルのトレーニングが不要になり、ファインチューニング中のロールアウト時の報酬クエリが削除され、PPOの個別の価値関数やポリシー勾配の仕組みを回避できます。ただし、ペアワイズ選好データ、参照ポリシーのアンカー、転移評価への依存は排除されません。
DPOは明示的な報酬モデルとPPOのトレーニング作業を排除しますが、調整されたデータ、判定の診断、転移評価は排除しません。
| レイヤー | PPO時代のRLHF | DPO系のアプローチ | 依然として測定が必要なもの | なぜ難しいままなのか |
|---|---|---|---|---|
| 報酬モデル | PPOの前に明示的な報酬モデルを学習させる。 | 報酬関係をペアワイズ損失の中に暗黙的に表現する。 | 選好ラベルの妥当性。 | ノイズの多いラベルや限定的なラベルでは、依然として誤ったシグナルを最適化してしまう。 |
| ポリシー最適化 | 価値関数とポリシー勾配の仕組みを用いてPPOを実行する。 | 参照モデルに固定されたオフライン目的関数を最適化する。 | デプロイ時の挙動へ転移させる。 | オフラインデータでは、現在のポリシーにおけるエラーを見逃す可能性がある。 |
| オンポリシーデータ | 反復プロセス中に新しい選好データを収集できる。 | 多くの場合、固定された比較データから開始する。 | ターゲットスライスのカバレッジ。 | 静的データでは、デフォルトで新しい動作をカバーすることはできません。 |
| 評価スタック | 報酬モデルのトレーニングおよびリリース時のエビデンスに使用されます。 | 多くの場合、判定者や固定データへの信頼度が高まります。 | 判定者のバイアスと信頼性。 | 位置、冗長性、摂動による失敗が依然として残ります。 |
| ホールドアウト転送 | PPO後のベンチマークおよびダウンストリームチェック。 | DPO後のベンチマークおよびダウンストリームチェック。 | 未知のプロンプトとポリシーの系譜。 | ベンチマークのランクは有用だが、それだけでは不十分である。 |
報酬モデル
- PPO時代のRLHF
- PPOの前に明示的な報酬モデルを学習させる。
- DPO系のアプローチ
- 報酬関係をペアワイズ損失の中に暗黙的に表現する。
- 依然として測定が必要なもの
- 選好ラベルの妥当性。
- なぜ難しいままなのか
- ノイズの多いラベルや限定的なラベルでは、依然として誤ったシグナルを最適化してしまう。
ポリシー最適化
- PPO時代のRLHF
- 価値関数とポリシー勾配の仕組みを用いてPPOを実行する。
- DPO系のアプローチ
- 参照モデルに固定されたオフライン目的関数を最適化する。
- 依然として測定が必要なもの
- デプロイ時の挙動へ転移させる。
- なぜ難しいままなのか
- オフラインデータでは、現在のポリシーにおけるエラーを見逃す可能性がある。
オンポリシーデータ
- PPO時代のRLHF
- 反復プロセス中に新しい選好データを収集できる。
- DPO系のアプローチ
- 多くの場合、固定された比較データから開始する。
- 依然として測定が必要なもの
- ターゲットスライスのカバレッジ。
- なぜ難しいままなのか
- 静的データでは、デフォルトで新しい動作をカバーすることはできません。
評価スタック
- PPO時代のRLHF
- 報酬モデルのトレーニングおよびリリース時のエビデンスに使用されます。
- DPO系のアプローチ
- 多くの場合、判定者や固定データへの信頼度が高まります。
- 依然として測定が必要なもの
- 判定者のバイアスと信頼性。
- なぜ難しいままなのか
- 位置、冗長性、摂動による失敗が依然として残ります。
ホールドアウト転送
- PPO時代のRLHF
- PPO後のベンチマークおよびダウンストリームチェック。
- DPO系のアプローチ
- DPO後のベンチマークおよびダウンストリームチェック。
- 依然として測定が必要なもの
- 未知のプロンプトとポリシーの系譜。
- なぜ難しいままなのか
- ベンチマークのランクは有用だが、それだけでは不十分である。
DPO、InstructGPT、Anthropic RLHF、カバレッジ理論、RewardBench 2、およびこの記事で引用されている公開済みのポストトレーニングレシピからのOpenTrain合成。
DPOが実際に排除するもの
DPOは、選好チューニングのパスから明示的な報酬モデルのトレーニングを排除し、そのフェーズにおけるPPO形式のオンライン・ポリシー勾配最適化を排除します。エンジニアリングの観点から言えば、これは可動部品が減り、実装の複雑さが軽減され、ハイパーパラメータの脆弱性が低下し、報酬モデルの崩壊やPPOの不安定さが実行を支配する可能性が低くなることを意味します。
この簡素化こそが、オープンなポストトレーニングスタックがDPOを迅速に採用した理由です。オリジナルの論文では安定性とチューニング負荷の低さが強調されており、Zephyrスタイルの取り組みやその後のTuluファミリーのリリースといった公開レシピにより、DPOはオープンなアライメントワークフローにおける標準的な段階となりました。
DPOが排除しないのは、信頼できる比較への依存です。オプティマイザは依然としてデータセットにエンコードされた選好関係を引き継ぎます。また、参照モデルの選択、ベータスケール、プロンプト分布、ペア選択ポリシーにも依存し続けます。ラベルにノイズが含まれていたり、分布が狭かったり、アノテーションのアーティファクトによってバイアスがかかっていたり、あるいは脆弱な判定者によって生成されたものであったりする場合、DPOはその問題を効率的に最適化してしまいます。
DPOファミリーも同様の理由で多様化しました。KTOは、教師あり学習の形式をペアワイズの選好から「望ましい」対「望ましくない」というシグナルに変更します。ORPOは、選好学習をモノリシックなSFTスタイルの段階に統合します。SimPOは参照モデル項を削除し、そのセットアップにおいてDPOを上回る成果を報告しました。これらは有意義なアルゴリズムの変更ですが、ラベル、判定者、またはベンチマークが下流の品質を反映しているかどうかを確認する必要性を排除するものではありません(KTO、ORPO、SimPO)。
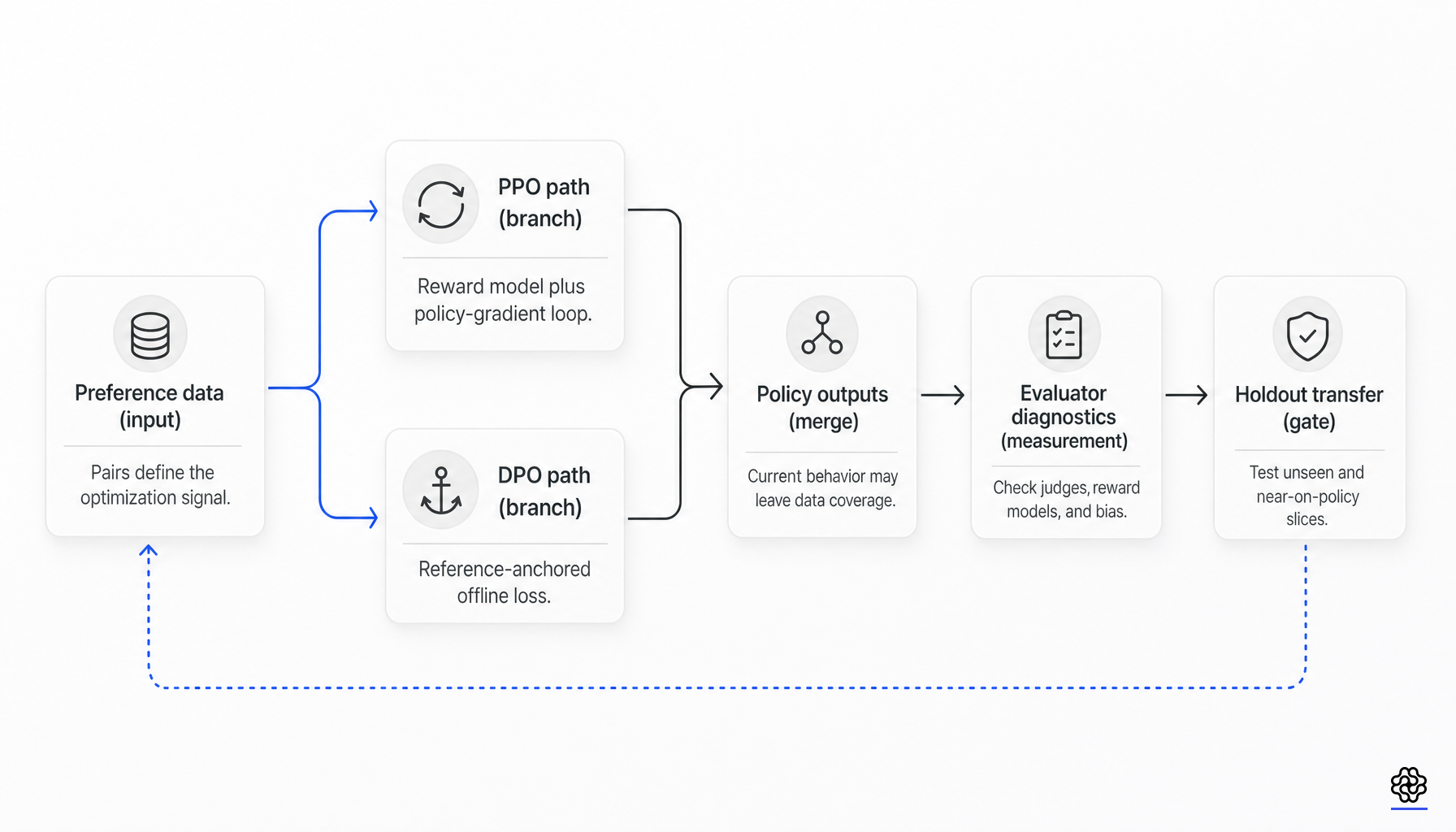
DPOが排除できないもの
現在の最も明確な制限は、カバレッジに関する文献から明らかになっています。Songらは、DPOのようなオフラインの対照学習手法が最適なポリシーに収束するためにはより強力なグローバルカバレッジが必要である一方、オンラインRL手法はより弱い部分的なカバレッジでも成功できると主張しています。運用の観点から言えば単純です。固定された選好データセットが評価時に重要な応答空間をカバーしていない場合、オプティマイザはその欠落した情報を推論することはできません(オンラインデータとカバレッジ)。
Tajwarらは、関連する実証的な結論に達しています。彼らの実験では、オンポリシーサンプリングと負の勾配スタイルの選好目的関数が、純粋なオフライン目的関数を上回る可能性があると論じています。なぜなら、それらはより迅速に確率質量を望ましい領域へ再配分できるからです。これはPPOを全面的に擁護するものではありません。現在のポリシー自身のミスが静的なデータに反映されていない場合、オンライン情報が重要になり得ることを思い出させるものです(オンポリシー選好ファインチューニング)。
ここで通常、DPO対PPOというスローガンが崩れます。ターゲットとなる動作が安定しており、選好データに十分に表現されている場合、DPOはより低い複雑さで実用的な利益の大部分を得ることができます。モデルがトレーニング後に新しい動作、新しいプロンプト体制、または敵対的なスライスへ移行することが期待される場合、チームには依然としてオンポリシーデータ、オンラインRL、棄却サンプリング、またはターゲットを絞ったデータ更新が必要です。
スローガンの背後にある実証的な対比
エビデンスの正しい解釈は「DPOの敗北」や「PPOの勝利」ではありません。DPOは認識論よりもオプティマイザーを大きく変化させたということです。より優れた選好データ、現在のポリシーの網羅性、報酬モデルの転移、そして判定の信頼性こそが、アルゴリズムのブランド名よりも重要であることが多々あります。
公開されているエビデンスは条件付きの解釈を支持しています。つまり、DPOは多くの場合シンプルで強力ですが、転移を決定づけるのは依然としてデータの品質、網羅性、評価者の妥当性であるということです。
| 研究/レポート | セットアップ | 主な結果 | 測定上の示唆 |
|---|---|---|---|
| DPO論文 | DPOとPPOベースのRLHFの比較。 | DPOは、学習の簡素化を実現しつつ、要約および対話の品質を維持または向上させました。 | 測定の問題が解決されたと証明することなく、DPOの採用について説明しています。 |
| DPOとPPOの解明 | 制御された選好学習レシピ。 | 一部の数学および一般的な領域ではPPOがDPOを上回りましたが、結果にはデータ品質の方が大きく影響しました。 | アルゴリズムの選択よりもデータの妥当性の方が重要である可能性があります。 |
| オンポリシー選好微調整 | オフライン対照学習手法 vs オンラインまたは負の勾配手法。 | オンポリシーサンプリングは純粋なオフライン目的関数を上回る可能性がある。 | カバレッジの失敗により、オンライン情報が価値を持つようになる。 |
| RewardBench 2 | ベンチマークスコア vs 下流タスクでの利用。 | Best-of-Nの相関は強かったが、PPOの転移性能は系統と分布に依存した。 | ベンチマークの順位だけでは転移の証拠にはならない。 |
| JudgeBench | LLM ジャッジ評価。 | 強力なジャッジモデルであっても、難易度の高い客観的な応答ペアの評価には苦戦した。 | 最適化が簡素化された後では、自動評価がボトルネックとなる可能性がある。 |
DPO論文
- セットアップ
- DPOとPPOベースのRLHFの比較。
- 主な結果
- DPOは、学習の簡素化を実現しつつ、要約および対話の品質を維持または向上させました。
- 測定上の示唆
- 測定の問題が解決されたと証明することなく、DPOの採用について説明しています。
DPOとPPOの解明
- セットアップ
- 制御された選好学習レシピ。
- 主な結果
- 一部の数学および一般的な領域ではPPOがDPOを上回りましたが、結果にはデータ品質の方が大きく影響しました。
- 測定上の示唆
- アルゴリズムの選択よりもデータの妥当性の方が重要である可能性があります。
オンポリシー選好微調整
- セットアップ
- オフライン対照学習手法 vs オンラインまたは負の勾配手法。
- 主な結果
- オンポリシーサンプリングは純粋なオフライン目的関数を上回る可能性がある。
- 測定上の示唆
- カバレッジの失敗により、オンライン情報が価値を持つようになる。
RewardBench 2
- セットアップ
- ベンチマークスコア vs 下流タスクでの利用。
- 主な結果
- Best-of-Nの相関は強かったが、PPOの転移性能は系統と分布に依存した。
- 測定上の示唆
- ベンチマークの順位だけでは転移の証拠にはならない。
JudgeBench
- セットアップ
- LLM ジャッジ評価。
- 主な結果
- 強力なジャッジモデルであっても、難易度の高い客観的な応答ペアの評価には苦戦した。
- 測定上の示唆
- 最適化が簡素化された後では、自動評価がボトルネックとなる可能性がある。
OpenTrain 引用されたDPO、PPO、RewardBench 2、データ選択、および判定評価ソースからの統合。
Ivisonらは、特定の制御された条件下でPPOの優位性を確認しつつ、最適化手法の変更以上に、選好データの品質が指示追従能力や真実性に影響を与えることを示した(Unpacking DPO and PPO)。データ中心のアプローチも同様の実践的な結論に達している。Filtered DPO、Less is More、HelpSteer形式のデータセットはすべて同じ制約を指し示している。つまり、選択されたデータ分布とラベル付けのプロトコルが、データセットの純粋なサイズや最適化手法の名称よりも支配的になり得るということである(Filtered DPO, Less is More, HelpSteer3-Preference)。
測定が最初に失敗する場所
最も有益な失敗モードは、抽象的な報酬ハッキングではない。それは転移の予測ミスである。オフラインの選好目的関数は、学習時に調整された指標上では良好に見えるが、ダウンストリームのシステムが、チームが実際に重視する挙動において失敗してしまうというケースである。
RewardBench 2はその明確な公開例である。これは未知の人間によるプロンプトと、より困難なbest-of-4形式に基づいて構築された。スコアは元のRewardBenchと比較して平均で約20ポイント低かった。このベンチマークはbest-of-Nのダウンストリーム利用と強く相関しており、ピアソン相関係数は0.87であったが、それはあくまで有益なシグナルに過ぎず、PPOにとって十分な転移の証拠とはならなかった。論文内のPPO実験では、RewardBench 2のスコアが72.9のオフポリシー報酬モデルがPPOスコア54.5を達成したのに対し、RewardBench 2のスコアが68.7のオンポリシー報酬モデルはPPOスコア59.8を達成した(RewardBench 2)。
報酬モデルの過剰最適化に関する評価研究も同様の方向性を示しています。ベンチマークがポリシーの受ける最適化圧力を近似できていない場合、高いベンチマークスコアはチームが考えているほど意味をなさない可能性があります(報酬モデル評価、報酬の過剰最適化)。
3つ目のバージョンは、人間のフィードバックそのものに現れます。Anthropic-HHに関する2024年の研究では、報酬モデルの委員会と比較して、合意がほとんどまたは全く得られないデータスライスが相当数存在することが判明しました。また、クリーンなデータを用いたモデルは、同論文の評価設定において下流のDPOの挙動を改善しました。これは報酬モデルの委員会が正解(グラウンドトゥルース)と等価であることの証明ではありません。固定された選好データが単一の塊ではないことの証拠です(人間のフィードバックの信頼性)。
判定者と報酬モデルには依然として診断が必要
チームがPPOのために明示的な報酬モデルを学習させることをやめると、多くの場合、LLMの判定者や静的な選好セットへの信頼を強めるようになります。それは、よりクリーンな最適化ツールの背後に同じ測定誤差を隠してしまう可能性があります。
JudgeBenchは、GPT-4oのような強力な判定者であっても、知識、推論、数学、コーディングにおける困難な客観的応答ペアに対しては、ランダムな推測とわずかな差しかないことを示しました。RANDの2026年版Judge Reliability Harnessは、この点をさらに広げました。テストされたどの判定者もベンチマーク全体で一貫して信頼できるものはなく、フォーマットの変更、言い換え、冗長性の変化、ラベルの反転といった摂動が、信頼性に有意な変動をもたらしました(JudgeBench、Judge Reliability Harness)。
バイアスに関する文献は、この問題をより明確にしています。LLMの評価者は、自分自身が生成したものを認識し、それを好む傾向があります。ペアワイズ判定者は、位置バイアス、タスク依存性、そして意見の不一致が激しい困難なスライスを示す可能性があります。Length-Controlled AlpacaEvalは、単に最適化ツールを改善するのではなく、測定上のアーティファクトを修正した好例です(自己選好、位置バイアス、Length-Controlled AlpacaEval)。
緩和策の教訓は、自動化された判定器が使えないということではありません。判定器はあくまでツールであるということです。位置の入れ替え、言い換えの不変性、冗長性の制御、反復サンプリング、そして既知のラベルを持つアンカー項目といった、ツールとしてのチェックが必要です。
公開されている本番環境のスタックはマルチステージであり続ける
主要なモデル開発者による公開データは、同じ方向を指し示しています。MetaのLlama 3.1のポストトレーニングに関する報告書では、各アライメントラウンドにSFT、拒否サンプリング、DPOが含まれていたと述べられています。Qwen2.5は大規模なSFTとマルチステージの強化学習を報告しています。DeepSeek-R1は、2つのRLステージ、コールドスタートデータ、拒否サンプリング、そしてその後の教師あり学習の拡張について説明しています。Tulu 3は、SFT、DPO用にキュレーションされたオンポリシーの選好データ、報酬モデリング、検証可能な報酬を用いたRL、汚染除去、そして開発用と未知の評価用スイートの分離を組み合わせています(Llama 3.1, Qwen2.5, DeepSeek-R1, Tulu 3)。
適切な表現は、すべてのクローズドなフロンティアスタックに関する普遍的な事実ではなく、公開されている証拠からの推論です。しかし、その推論は強力です。高性能な公開スタックは、DPOを採用したからといって、評価、オンポリシーデータの更新、拒否サンプリング、あるいはターゲットを絞ったRLステージへの投資を止めることはありません。彼らはDPOを、より広範なポストトレーニングシステムにおける一つのステージとして利用しています。
実践的な実装パターン
2026年において技術的に正当化できるポストトレーニングのパターンは、「DPOかPPOか」を選ぶことよりも、段階的な測定設計に近いものとなります。
第一に、チームは単に大規模なデータセットではなく、ターゲットとなるユースケースに合わせて調整された選好データセットを必要とします。データソースが異種混合である場合は、トレーニングの主張を行う前に、判定器のソース、プロンプトファミリー、タスクタイプ、および想定されるノイズの状況ごとにデータをスライスする必要があります。
第二に、報酬モデルやLLM判定器をトレーナーまたは評価者として使用する前に、チームは評価者の診断を必要とします。最低限、位置入れ替えチェック、言い換えやフォーマットの不変性チェック、冗長性バイアスのチェック、反復サンプリングの安定性、そして人間が検証した小さなアンカーセットが必要です。
第3に、チームは真の転移評価を必要とします。ホールドアウトは、単に保持された選好ペアだけではありません。未知のプロンプト、敵対的スライス、ジャッジのストレススライス、そして可能な場合は現在のモデルによって生成されたオンポリシーまたはそれに近いスライスを含めるべきです。
第4に、チームはイデオロギーではなく、カバレッジを診断することによってオンラインデータが必要かどうかを決定すべきです。評価の失敗が現在のポリシーの出力に集中している場合、あるいはモデルがデータセットに含まれていない推論や安全性の領域に移行している場合、オンライン収集、棄却サンプリング、またはRLの方が、信頼性の高い改善を得るための安価な方法となる可能性があります。
実用上の結論は限定的ですが、強力です。DPOは評価の代替手段ではなく、最適化の代替手段として扱うべきです。DPOは多くの場合、コストのかかるオンライン最適化の仕組みを排除します。しかし、選択された選好目的関数、ラベル付けプロセス、報酬モデル、または判定者が実際に機能するかどうかを確認する必要性までを排除するものではありません。
OpenTrain は、チームが既に使用しているスタック内で、専門的な評価者や選好データオペレーターを調達できます。評価者のキャリブレーションに関するコンテキストについては LLM の判定者信頼性リファレンス を、選好データの計画については RLHF のスコープ設定ガイド を参照してください。レビューサイクルの人員配置がボトルネックとなっている場合は、求人を投稿してください。
出典
- Direct Preference Optimization
- Training language models to follow instructions with human feedback
- Training a Helpful and Harmless Assistant with RLHF
- DPOとPPOの解説
- 最適ではないオンポリシーデータを用いた選好微調整
- オンラインデータの重要性
- RewardBench 2
- 報酬モデルの評価
- 報酬の過剰最適化
- JudgeBench
- 判定の信頼性ハーネス
- LLM 評価者は自身の生成物を認識し、それを好む傾向がある
- Judging the Judges
- Filtered Direct Preference Optimization
- Less is More
- HelpSteer3-Preference
- Llama 3.1
- Qwen2.5 technical report
- Tulu 3
- DeepSeek-R1
- KTO
- ORPO
- SimPO
- Length-Controlled AlpacaEval