LLM ジャッジはオラクルではなく測定システムである

LLM ジャッジが本番環境の評価やポストトレーニングにおいて十分に信頼できるのはどのような場合か、またそれらをどのように調整、監査、ゲート制御すべきかについての証拠に基づく技術リファレンス。
LLMは本番環境でも使用可能ですが、それはバージョン管理、キャリブレーション、監査が行われる測定システムとしてのみです。中心的な緊張関係は、この分野で最も引用されている成功事例である、GPT-4がMT-BenchやChatbot Arenaにおいて人間の好みと80%以上の合意に達したという事実が、タスクの組み合わせ、ベンチマークの構成、指標、またはジャッジのファミリーが変更されると急激な転移失敗を示す新しい証拠と並んで存在していることにあります(MT-Bench and Chatbot Arena、Arena-Hard、JUDGE-BENCH、JudgeBench)。
これらの結果は矛盾していません。これらは、ジャッジをキャリブレーションされた測定器ではなく、ポータブルな真実のソースとして扱った場合に何が起こるかを説明しています。
初期の合意結果はベンチマーク固有のものであり、普遍的なものではなかった
初期の肯定的な結果は本物でした。MT-BenchとChatbot Arenaは、強力なペアワイズジャッジが広範なチャット形式の比較において人間の好みによる判断を近似できることを確立しました。G-Evalは、構造化されたGPT-4の判断が要約において古い自動指標を上回る可能性があることを示しつつ、LLMが生成したテキストに対する評価者のバイアスについて警告しました(G-Eval)。その後、Prometheus 2は、オープンな評価モデルがユーザー定義の基準を持つ専用のジャッジモデルとして大幅に改善できることを示しました(Prometheus 2)。
その組み合わせが重要です。つまり、この分野は抽象的な意味で「LLMジャッジが機能する」ことを証明したわけではありません。より限定的な主張、すなわち、特定のプロンプトおよび集計スキームの下で、特定のベンチマークファミリーにおいて、特定の人間による好みの分布をジャッジが追跡できるということを証明したのです。
AlpacaEvalも同じ点を別の方向から指摘しています。その長さ調整された勝率はChatbot Arenaとの相関を高め、長さによるゲーム性を低減させましたが、そのメンテナは依然としてリリース判断のために自動評価者のみを使用することに対して警告しています。ジャッジは反復的な開発には役立ちますが、最終的なゲートとしては依然として脆弱である可能性があります。
より困難なメタ評価がポータビリティの物語を崩壊させた
Arena-Hardはポータビリティの問題を具体化しました。これは、強力な指示チューニング済みモデル間の分離能を向上させるためにクラウドソースのライブデータから設計されており、著者らは低コストでChatbot Arenaと高い一致度を示したと報告しています。同研究において、MT-Benchは分離能の面で大きく失敗しつつも、大まかな順位付けの順序を維持することはできました。これこそがリリースゲートの推論を破綻させるメトリクスの不一致です。つまり、ベンチマークは候補をランク付けできても、出荷判断を下すのに十分な精度でフロンティアに近いシステムを分離することには失敗し得るのです。
JUDGE-BENCHは、この問題を20のNLP評価タスクと11のジャッジモデルにまで広げました。有効な回答を出すモデルの平均的な一致度は、偶然性を補正しても控えめなものであり、データセットごとの分散が非常に大きいという結果でした。GPT-4oは、あるセグメントでは強力に見えても、別のセグメントではゼロに近い、あるいは負の値を示すことがありました。同論文では、ジャッジは専門家によるアノテーションよりも非専門家によるアノテーションと、また機械生成テキストよりも人間が生成した言語とよりよく一致することも判明しました。
JudgeBenchは、スタイルや群衆の好みへの適合から脱却し、知識、推論、数学、コーディングにおける客観的な正しさを追求することで、さらに厳しい評価を行いました。その要旨によると、GPT-4oを含む多くの強力なジャッジモデルでさえ、難易度の高い回答ペアに対してはランダムな推測とわずかな差しか出ないことが報告されています。IF-RewardBenchは、ペアワイズのみのメタ評価は最適化で使用されるリストワイズランキングのワークフローと整合していないと主張することで、この批判を指示追従評価にまで広げています(IF-RewardBench)。
ベンチマークのスナップショットが示す転移の限界
| ベンチマーク | 評価体制 | 信頼性への影響 |
|---|---|---|
| MT-Bench / Chatbot Arena | ペアワイズチャットの選好判断 | ベンチマーク内での強い一致は、普遍的な転移を意味するものではない。 |
| Arena-Hard | ライブアリーナデータからのより困難な分離可能性 | ベンチマークの構築方法が「一致」の意味を変える。 |
| JUDGE-BENCH | 20のNLPタスクと11のジャッジモデル | 偶然性を補正した指標やランク指標は、タスクによって大きく異なります。 |
| JudgeBench | 推論ドメイン全体における客観的な正確性 | 正確性が重視されるタスクでは、選好ベースのジャッジからの転移が不十分であることが露呈します。 |
MT-Bench / Chatbot Arena
- 評価体制
- ペアワイズチャットの選好判断
- 信頼性への影響
- ベンチマーク内での強い一致は、普遍的な転移を意味するものではない。
Arena-Hard
- 評価体制
- ライブアリーナデータからのより困難な分離可能性
- 信頼性への影響
- ベンチマークの構築方法が「一致」の意味を変える。
JUDGE-BENCH
- 評価体制
- 20のNLPタスクと11のジャッジモデル
- 信頼性への影響
- 偶然性を補正した指標やランク指標は、タスクによって大きく異なります。
JudgeBench
- 評価体制
- 推論ドメイン全体における客観的な正確性
- 信頼性への影響
- 正確性が重視されるタスクでは、選好ベースのジャッジからの転移が不十分であることが露呈します。
OpenTrain 引用されたベンチマークおよびメタ評価ソースからの統合。
偶然性を補正した信頼性指標
一致率(Percent agreement)は、それ単体では弱い根拠となります。ラベルのバランスが偏っている場合、ジャッジはほとんど情報を付加することなく高い一致率を示す可能性があるからです。カテゴリ評価においては、偶然性を補正した一致率を主要な一致率指標と併記すべきです。
バイアスとジャッジファミリーの影響が構造的なエラーを生む
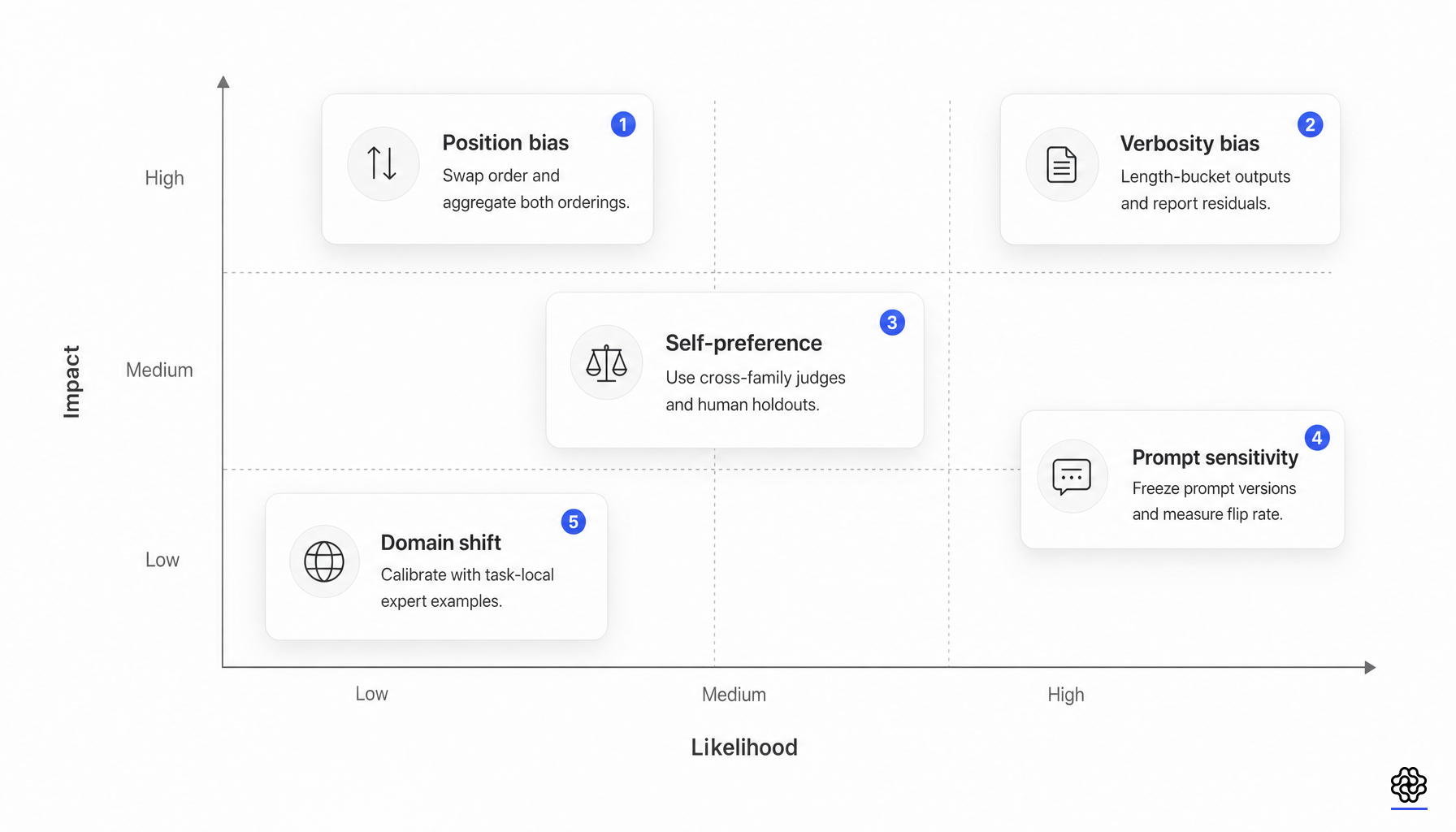
この分野における最も重要な信頼性のアップデートは、バイアスがもはや単なる付随的な注釈ではないという点です。それは構造的なエラーの測定可能な発生源となっています。
ポジションバイアスに関する研究は、逸話の域を超えました。MTBenchおよびDevBench全体にわたる体系的な研究により、反復安定性、位置の一貫性、選好の公平性が導入され、100,000件以上の評価インスタンスが分析されました。その結果、ポジションバイアスはランダムな偶然ではないことが判明しました(ポジションバイアス研究)。ジャッジのアイデンティティ、タスクカテゴリ、回答の品質差はすべて重要です。
自己選好も同様に重要です。なぜなら、それが評価をモデルファミリーと結びつけてしまうからです。ある研究では、LLM の評価者が自身の生成物を認識し、それを優遇できることが示されました。後の研究では、GPT-4の自己選好は単なる虚栄心ではなく、親近感や低いパープレキシティと結びついていることが明らかになりました(自己認識、自己選好)。これは、ジャッジ、ポリシー、データ生成者が同じファミリー出身であるか、あるいは同様のポストトレーニングスタイルを共有している場合に問題となります。
リファレンス設計は、再び失敗モードを変化させます。「No Free Labels」の研究では、質問に回答するジャッジの能力が、その質問に対する回答を評価する能力と結びついていることが明らかになりました。また、より強力な人間によるリファレンスを持つ弱いジャッジの方が、合成リファレンスを持つ強いジャッジよりも優れた結果を出す可能性があることも示されています(No Free Labels)。アンサンブルに関する知見も同様の方向性を示しており、多様なジャッジパネルを構成することで単一ファミリーのバイアスを軽減でき、場合によっては単一の巨大なジャッジよりも低コストで済むことが示唆されています(Replacing Judges with Juries)。
ポストトレーニングにおいて、報酬の質はジャッジのキャリブレーション次第である
ジャッジが評価からトレーニングへと移行すると、測定誤差は最適化誤差へと変わります。RewardBenchは、プロンプト、選択された回答、拒否された回答のトリプルを用いた報酬モデルの直接評価という先駆けとなりました。RewardBench 2は、その物語を更新し、主に未知の人間のプロンプト、6つのドメイン、1,865件のプロンプト、20のモデルまたは人間による回答、best-of-4のスコアリング設定、そして同等に有効な回答間でのキャリブレーションをテストするためのタイ(引き分け)サブセットで構成された、より難易度の高いベンチマークを提供しています(RewardBench 2、データセットカード)。
RewardBench 2が有用なのは、ベンチマークスコアがトレーニングにそのまま転移するという単純な物語に抗っているからです。論文ではbest-of-Nサンプリングのパフォーマンスとの強い相関が示されていますが、同時にRLHF PPOの相関はコンテキスト固有の要因に影響を受けるとも述べられています。精度ベースの報酬ベンチマークスコアは強力なRLHFトレーニングの前提条件ですが、それだけでは不十分です。
より優れたジャッジシグナルは、慎重に使用すれば役立ちます。Crowd comparative reasoning(群衆による比較推論)は、ペアワイズ評価に群衆の回答を追加することで、ダウンストリームの拒否サンプリングの改善を含む、選好ベンチマーク全体での向上を示しています(Crowd Comparative Reasoning)。教訓は、ジャッジ時の計算量を増やせば信頼性が解決するというものではありません。より豊かな判断プロトコルが、選択やフィルタリングに使用される測定シグナルを改善できるということです。
公式の製品ドキュメントも、現在この現実を反映しています。OpenAIのグレーダー(評価者)ドキュメントでは、グレーダーを評価や強化学習によるファインチューニングのための第一級オブジェクトとして扱い、高品質なモデルや人間の例を用いてグレーダーをテストすることを推奨しています。また、グレーダーハッキングを、モデルがグレーダー評価では高スコアを出すものの、専門家による人間評価では低い評価になるケースと定義しています(OpenAI graders、reinforcement fine-tuning cookbook)。失敗のモードは単純です。チームは、ポリシーがそれに対して最適化を開始した後もスコアが整合性を保つかどうかを検証する前に、ジャッジをループに組み込んでしまうのです。
ジャッジシグナルがポストトレーニングに導入される場所
| ワークフローの段階 | ジャッジアーティファクト | 最小制御 |
|---|---|---|
| 評価専用の回帰テスト | キャリブレーションセットに対するバージョン管理されたジャッジプロンプト | ドリフト、スライスデルタ、および偶然性を補正した一致率を追跡します。 |
| 棄却サンプリング | ペアワイズ、リストワイズ、またはベリファイアスコア | 選択によってターゲットスライスにおける人間が好む出力が改善されるかどうかを監査します。 |
| 報酬モデルのベンチマーク | 報酬モデルまたはジャッジアンサンブル | ベンチマークスコアを、後続のPPOやbest-of-Nの挙動から分離します。 |
| RFT / RLHF グレーディング | ルーブリックグレーダーまたは報酬シグナル | 最適化を拡大する前に小規模な検証を実行します。 |
| リリースゲーティング | 調整済みジャッジスコアと人間による監査 | 不確実性の境界、不一致の制限、およびスライスチェックを必須とする。 |
評価専用の回帰テスト
- ジャッジアーティファクト
- キャリブレーションセットに対するバージョン管理されたジャッジプロンプト
- 最小制御
- ドリフト、スライスデルタ、および偶然性を補正した一致率を追跡します。
棄却サンプリング
- ジャッジアーティファクト
- ペアワイズ、リストワイズ、またはベリファイアスコア
- 最小制御
- 選択によってターゲットスライスにおける人間が好む出力が改善されるかどうかを監査します。
報酬モデルのベンチマーク
- ジャッジアーティファクト
- 報酬モデルまたはジャッジアンサンブル
- 最小制御
- ベンチマークスコアを、後続のPPOやbest-of-Nの挙動から分離します。
RFT / RLHF グレーディング
- ジャッジアーティファクト
- ルーブリックグレーダーまたは報酬シグナル
- 最小制御
- 最適化を拡大する前に小規模な検証を実行します。
リリースゲーティング
- ジャッジアーティファクト
- 調整済みジャッジスコアと人間による監査
- 最小制御
- 不確実性の境界、不一致の制限、およびスライスチェックを必須とする。
RewardBench 2、OpenAIのグレーダーガイダンス、RLAIFの文献、および最近のルーブリックベースのポストトレーニング研究からのOpenTrain合成。
本番環境のジャッジスタックには、キャリブレーション、バージョニング、人間によるエスカレーションが必要である
OpenAIやAnthropicが公開している資料によると、最先端のチームはジャッジを単独のリリース判定権限としてではなく、階層化された測定スタックの構成要素として扱っていることが示唆されています。OpenAIは、評価および強化学習によるファインチューニングのワークフローの一部としてグレーダーを公開しています。Anthropicは、単一の LLM ジャッジは研究システムの明確な回答コンポーネントに対しては一貫性を保てる可能性があると報告する一方で、人間によるテストが依然として不可欠であるとも述べています。なぜなら、人間は自動化では見逃してしまうハルシネーション、システム障害、ソース品質の誤りを検知できるからです(Anthropic engineering)。
より最近のキャリブレーションに関する文献も、同様の枠組みに収束しつつあります。SLMEvalは、複数の調整済み評価者が実世界のオープンエンドなタスクで失敗することを指摘し、少量の人間による選好データとエントロピーベースのキャリブレーションを組み合わせることで本番環境でのユースケースが改善したと報告しています(SLMEval)。IRT(項目反応理論)に基づく信頼性に関する論文では、プロンプトの変動に対してジャッジが安定して動作するかを問う「本質的一貫性」と、その安定した動作が実際の人間による品質評価と一致しているかを問う「人間とのアライメント」を区別しています(IRT reliability)。
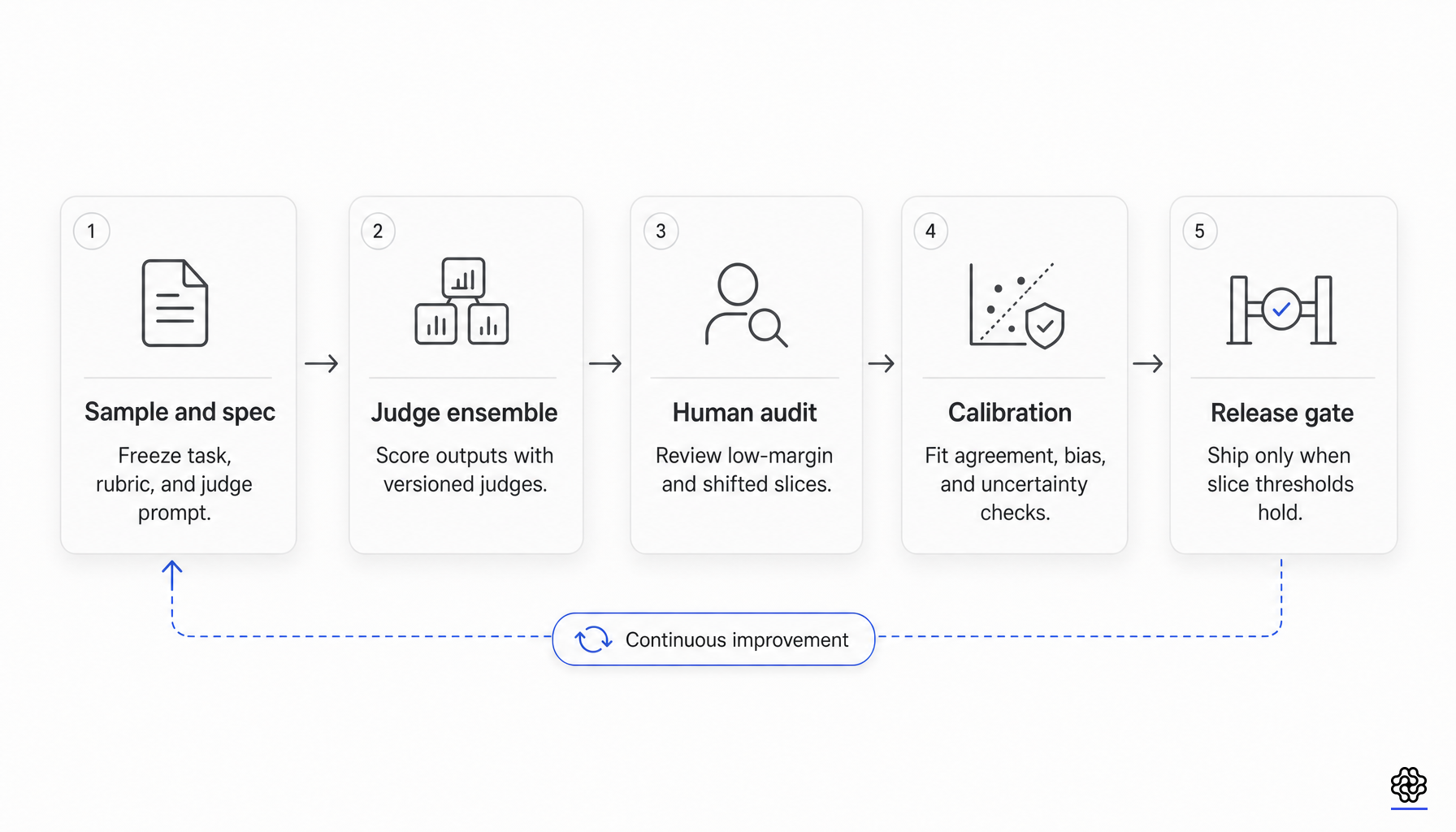
リリースゲートにおける具体的なアンチパターンは、証拠から明らかです。それは、単一の平均ジャッジスコアやペアワイズ勝率を普遍的な合格基準として使用することです。これは、現在の証拠が裏付けていない測定の不変性を前提としています。より優れた最小契約は、より狭い範囲で、かつ明示的に監査されるものです。
- ジャッジモデルのバージョン、ジャッジプロンプト、ルーブリックテキスト、参照ポリシー、タイ(引き分け)ポリシー、および集計ロジックを固定してください。
- 高リスクなスライスを含む、正確なリリース分布に対する人間がラベル付けしたキャリブレーションセットを維持してください。
- 少なくとも1つの偶然性を補正した一致度指標と、1つのランクまたは分離可能性指標を報告してください。
- 順序効果、スタイルおよび長さの効果、自己ファミリーへの選好、および参照感度を監査してください。
- 学習時の報酬選択とリリース時の受け入れを分離してください。
- マージンが低い、意見の不一致が多い、または新たにシフトしたスライスは、人間の判断に委ねてください。
実用上の境界線
本番環境を運用するチームにとっての実用的な意味合いは限定的ですが、依然として強力です。LLMによる評価は、人間の評価では継続的な実行が遅すぎる、あるいはコストが高すぎる場合や、評価対象がオープンエンドである場合、そしてチームがキャリブレーション、バイアス監査、人間による判定キューに真剣に取り組む意欲がある場合に有用です。
これらは持ち運び可能な真実の測定器ではありません。これらは測定インフラです。そのように扱うチームは、日々の回帰検知、候補のフィルタリング、報酬モデルの選択、そして人間による選択的なエスカレーションに活用できます。そうしないチームは、最終的に自分たちの盲点を最適化してしまうことになるでしょう。
OpenTrainは、チームがすでに使用している評価スタック内で、キャリブレーションセット、監査スライス、ドリフトチェックのための専門的な人間による判定者を調達できます。レビューサイクルの運用がボトルネックとなっている場合はマネージドサービスから始めるか、直接採用したい場合は求人を投稿してください。