RLHFデータプログラムのスコープ設定方法

RLHFプログラムを立ち上げるための実践的なフレームワーク:キューの形状定義、観測されたスループットに基づく評価者数の算出、レビューサイクルの予算策定、および週次リフレッシュゲートの運用について解説します。
多くの初期の RLHF データプログラムは、PPOループではなく、人間によるレイヤーで破綻します。よくある高コストな失敗例として、安全性、事実性、スタイル、タスクの成功を1回のクリックに混在させるルーブリック、本番のラベリング前のキャリブレーションパスの欠如、そしてすべての選好ペアが同じコストであると想定した予算設定などが挙げられます。公開されている事例としては、1時間未満の評価者時間で約900ビットのフィードバックを使用したOpenAIの初期のbackflip作業から、169,352件の選択/拒否行を含むAnthropicのHH-RLHFリリースまで多岐にわたります(OpenAI、Anthropic HH-RLHF dataset)。スコープは、最先端ラボのヘッドライン数値をコピーするのではなく、タスクの幾何学的構造から導き出すべきです。
人間は実際に何を判断しているのか?
「どちらの回答が優れているか?」という問いよりも、もっと絞り込んだ質問から始めましょう。InstructGPTは、教師ありデモンストレーション、報酬モデルの比較、ポリシー最適化のためのプロンプトを分離しました。これらのデータプロダクトは、システムの異なる部分を学習させるものです(InstructGPT)。デモンストレーションは形式とタスクの完了を教え、選好ペアは相対的な判断を教えます。プロンプトプールは、チューニングされたモデルがトレーニング中に何を見るかを決定します。
1回目または2回目のプログラムでは、作業を以下の3つのキューに分割してください:
- 成功キュー: モデルが通常は正しく、時折選好チェックが必要なプロンプト。
- 境界キュー: ポリシー、安全性、事実性、またはスタイルにおいて挙動が逸脱するエッジケース。
- リカバリーキュー: 間違った回答が大きな損失につながる、敵対的または高リスクなケース。
このキューの分割によって、最初に購入すべきアノテーションプロダクトが決まります。ペアワイズ選好が必要な場合は、RLHF and preference data を中心にプログラムを構成してください。失敗の原因が回答の内部にある場合は、回答の内部でラベルを収集します。OpenAIのプロセス監視に関する研究では、約800,000件のステップレベルのラベルを含むPRM800Kがリリースされ、評価されたMATH設定において、プロセス監視が結果監視を上回ることが判明しました(Let’s Verify Step by Step)。数学、コード推論、マルチステップのツール使用においては、ペアワイズ選好だけでは粗すぎることがよくあります。
最初の本格的な実行に必要なデータ量はどれくらいか?
公開されているプログラムをノルマではなく、運用のモデルとして活用してください。OpenAIの要約作業では64,832件の要約比較が使用されました。InstructGPTでは約13,000件の教師ありプロンプト、約33,000件の報酬モデル用プロンプト、および約40名の選抜されたコントラクターが報告されています。PRM800Kの規模がはるかに大きかったのは、各監督単位がステップレベルのより小さな判断であったためです(人間からのフィードバックによる要約、InstructGPT、PRM800K)。
公開されている RLHF プログラムのモデル
| 公開プログラム | 人間からのフィードバックのフットプリント | そこからわかること |
|---|---|---|
| OpenAIの転換 | 約900件のフィードバック、1時間未満の評価者による作業時間、そして約70時間のシミュレーション経験。 | タスクの判定が容易であれば、非常に限定的な目的でも小規模なパイロット運用を正当化できます。 |
| OpenAIの要約 | 64,832件の要約比較。 | 安定した報酬モデリングを目指す場合、単一タスクのテキストアライメントプログラムでも、すぐに数万件規模に達します。 |
| InstructGPT | 約13,000件のSFTプロンプト、33,000件の報酬モデル用プロンプト、および約40名のコントラクター。 | アシスタントのアライメントには通常、単一のアノテーションタイプではなく、複数のキューが必要です。 |
| Anthropic HH-RLHF | 公開されたデータセットには169,352件の選択・拒否された行が含まれており、基盤となるトレーニング設定では、毎週オンラインで最新の人間のフィードバックを取り入れる更新が行われました。 | 会話型ポストトレーニングは、一度きりの静的なバッチではなく、更新ループから恩恵を受けます。 |
| OpenAIのプロセス監視 | 800,000件のステップレベルラベルを持つPRM800K。プロセス監視モデルは、代表的なMATHサブセットの78%を解決しました。 | ステップレベルのラベルは、中間的な正確さが真のボトルネックである場合にのみ、コストに見合う価値があります。 |
OpenAIの転換
- 人間からのフィードバックのフットプリント
- 約900件のフィードバック、1時間未満の評価者による作業時間、そして約70時間のシミュレーション経験。
- そこからわかること
- タスクの判定が容易であれば、非常に限定的な目的でも小規模なパイロット運用を正当化できます。
OpenAIの要約
- 人間からのフィードバックのフットプリント
- 64,832件の要約比較。
- そこからわかること
- 安定した報酬モデリングを目指す場合、単一タスクのテキストアライメントプログラムでも、すぐに数万件規模に達します。
InstructGPT
- 人間からのフィードバックのフットプリント
- 約13,000件のSFTプロンプト、33,000件の報酬モデル用プロンプト、および約40名のコントラクター。
- そこからわかること
- アシスタントのアライメントには通常、単一のアノテーションタイプではなく、複数のキューが必要です。
Anthropic HH-RLHF
- 人間からのフィードバックのフットプリント
- 公開されたデータセットには169,352件の選択・拒否された行が含まれており、基盤となるトレーニング設定では、毎週オンラインで最新の人間のフィードバックを取り入れる更新が行われました。
- そこからわかること
- 会話型ポストトレーニングは、一度きりの静的なバッチではなく、更新ループから恩恵を受けます。
OpenAIのプロセス監視
- 人間からのフィードバックのフットプリント
- 800,000件のステップレベルラベルを持つPRM800K。プロセス監視モデルは、代表的なMATHサブセットの78%を解決しました。
- そこからわかること
- ステップレベルのラベルは、中間的な正確さが真のボトルネックである場合にのみ、コストに見合う価値があります。
引用された公開ソースからの OpenTrain 合成。
第一のルールは、スケールアップの前にパイロット運用を行うことです。RewardBenchの報告によると、一部の選好データテストセットにおける人間の正解率の上限は60-70%の範囲にあり、これは意見の不一致が評価者の能力不足ではなく、タスク自体の性質である可能性があることを意味します(RewardBench)。パイロット運用での合意率が低い場合は、評価者の人数を増やす前に、仕様を明確にしてください。
第二のルールは、プロンプトの数を増やす前に情報の密度を高めることです。InstructGPTでは、ラベル担当者に1つのプロンプトに対して4から9の出力をランク付けするよう求めました。これにより、単一の二者択一よりもプロンプトあたりの比較情報が多く生成されました(InstructGPT)。多くの場合、これは不安定な評価基準のまま評価者のプールを倍にするよりも優れた最初の一手となります。
実際に必要な評価者の数は?
評価者の数は、不一致バッファを考慮したスループット計算によって算出されます:
分母にはパイロット運用時の数値を使用してください。実稼働率には、純粋なラベル付け以外の時間を奪うすべての要素(ルールの再確認、裁定、スポットチェック、再トレーニング、休憩、ツールの操作による摩擦など)が含まれます。
例えば、パイロット運用で評価者1人あたり週180件の調整済み判断が得られ、次の更新で週3,000件の判断が必要だとします。実稼働率を70%とすると、ドメイン、言語、タイムゾーン、バックアップ容量のバッファを除いた基本チームの人数は ceil(3000 / 180 / 0.70) = 24 名となります。キューに4つのドメインと言語の組み合わせが必要な場合は、合計をプールする前に、各セルごとに計算を行ってください。
公開されている基準値は、妥当性の確認としてのみ有用です。InstructGPTは、トレーニングラベル付け担当者間の合意率を72.6 +/- 1.5%、ホールドアウトされたラベル付け担当者間の合意率を77.3 +/- 1.3%と報告しました。OpenAIの要約作業では、研究者間の合意率が73 +/- 4%であると報告されています(InstructGPT、人間からのフィードバックによる要約)。これらの数値は、評価者数を規定するものではありません。これらは、少数の調整済みチームでも大規模な実行をサポートできること、そしてタスクが困難な場合には60%台後半から70%台前半の不一致が正常である可能性があることを思い出させるものです。
カバレッジは純粋な数と同じくらい重要です。キューが医学、多言語の安全性、コードレビューにまたがる場合、単一の労働力バケットにまとめるのではなく、ドメインと言語のセルごとに規模を決定する必要があります。NISTのAI RMFは、AIリスクのマッピングと測定において多様な視点を持つことを求めており、その生成AIプロファイルでも、役割とレビュー経路を文書化した構造化された人間によるフィードバック演習を推奨しています(NIST AI RMF 1.0、NIST GenAI Profile)。
予算はどのように構築すべきか?
RLHFの選好ペアに関するドメイン、言語、タスク設計ごとの一次ソースのレートカードは、公に検証可能なものではありません。時間ベースの作業から予算を算出してください:
チームが見落としがちな項目は、判定とリサーチャーの時間です。OpenAIの要約に関する論文では、人間によるフィードバックのデータセットには、品質を確保するために膨大なラベラーの時間とリサーチャーの時間が必要であったと述べられています(summarization from human feedback)。そのため、スプレッドシート上では安く見えるパイロットプロジェクトも、評価基準が変わり始めると高額になってしまうのです。
調達手数料とマーケットプレイス手数料は、労働コストとは別に考えてください。OpenTrainは15%のセルフサービス手数料と20%のマネージドサービス手数料を公開しています。チームは直接雇用することも、OpenTrainにプロジェクト運営を任せたい場合にマネージドサービスを利用することも可能です(OpenTrainの料金)。ボトルネックがモデルの更新設計ではなく、調整されたキューの調達と運用にある場合、これは重要な要素となります。
どのようなスケジュールを計画すべきか?
単一のモノリシックなラベリングフェーズではなく、ゲート(段階)で考えてください:
- 仕様策定: 評価基準、意見の不一致に関するルール、エスカレーションパスを定義します。
- キャリブレーション: 判定作業において、評価基準の新たな分岐が毎日発見されなくなるまでサンプルアイテムを実行します。
- パイロット: 厳格なレビュー体制のもと、限定的なキューでラベリングを行います。
- 評価: 評価セットにハードネガティブ(誤分類しやすい例)を含めることを必須とします。
- リフレッシュ: ルーブリックを更新し、週次またはリリース単位のサイクルで繰り返します。
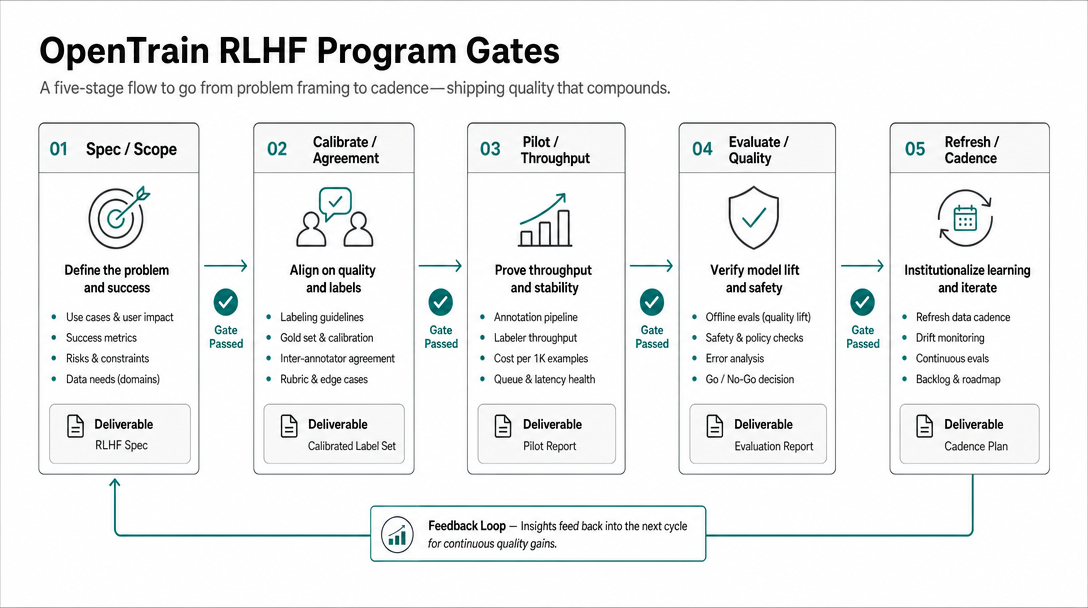
公開されている研究パターンは、短いループをサポートしています。OpenAIの初期の人間による選好の研究では、モデルが不確実な比較を積極的にサンプリングしました。InstructGPTは、デモンストレーション、報酬モデルのトレーニング、ポリシー最適化にそれぞれ別のデータセットを使用しました。DeepMindのSparrowの研究では、ターゲットを絞った人間の判断と証拠に基づいた評価が使用されました。Anthropicの「helpful-harmless」アシスタントに関する論文では、新しい人間のフィードバックを用いた反復的なオンラインデータ収集について説明されています(OpenAI human preferences, InstructGPT, Sparrow, Anthropic HH-RLHF)。最初のプログラムと2番目のプログラムでは、データセットのサイズではなく、運用ループを模倣すべきです。
最初の実行後、スコープはどのように変化しますか?
最初のプログラムでは学習のスピードを重視すべきです。成熟したプログラムでは再現性を重視すべきです。これらは異なる投資対象として扱ってください。
最初の実行後に RLHF スコープがどのように変化するか
| 決定 | 最初の RLHF プログラム | 2回目または成熟したプログラム |
|---|---|---|
| データターゲット | 評価基準の不一致、タスクの摩擦、報酬モデルの明らかな失敗モードを明らかにする最小限のキューでパイロット運用を行う。 | 観測されたモデルのドリフト、新しい製品サーフェス、ハードネガティブマイニングに基づいて、毎週の更新バッチサイズを決定する。 |
| 評価者プール | 少数の調整済みグループから開始し、判定ノートに過剰なほど投資する。 | ドメイン言語のセル、バックアップ体制、レビュアーの昇格パス、および離職バッファを維持します。 |
| QA | 評価基準が毎日変わらなくなるまで、ラベルの大部分をレビューします。 | サンプリングレビュー、ゴールドアイテム、不一致ダッシュボード、および定期的な評価基準の更新へ移行します。 |
| タイムライン | 仕様策定、キャリブレーション、パイロット、評価、および最初の更新判断をゲートとします。 | 週次またはリリースベースの更新、評価の回帰チェック、およびキューの健全性メトリクスをゲートとします。 |
| ソーシングモデル | チームがキャリブレーションと判定を実行できる場合は直接雇用してください。キューの運用がボトルネックとなっている場合はマネージドサービスを利用してください。 | 安定した人材プールを維持し、モデルや製品の表面的な変更が必要な場合にのみ専門家を追加し、調達手数料と人件費を分けて管理してください。 |
| 成功の成果物 | 利用可能なルーブリック、ミスを含む評価セット、および評価者のキャパシティモデル。 | 既知のスループット、既知の意見不一致の範囲、および明確なエスカレーションパスを備えた、再現可能な運用リズム。 |
データターゲット
- 最初の RLHF プログラム
- 評価基準の不一致、タスクの摩擦、報酬モデルの明らかな失敗モードを明らかにする最小限のキューでパイロット運用を行う。
- 2回目または成熟したプログラム
- 観測されたモデルのドリフト、新しい製品サーフェス、ハードネガティブマイニングに基づいて、毎週の更新バッチサイズを決定する。
評価者プール
- 最初の RLHF プログラム
- 少数の調整済みグループから開始し、判定ノートに過剰なほど投資する。
- 2回目または成熟したプログラム
- ドメイン言語のセル、バックアップ体制、レビュアーの昇格パス、および離職バッファを維持します。
QA
- 最初の RLHF プログラム
- 評価基準が毎日変わらなくなるまで、ラベルの大部分をレビューします。
- 2回目または成熟したプログラム
- サンプリングレビュー、ゴールドアイテム、不一致ダッシュボード、および定期的な評価基準の更新へ移行します。
タイムライン
- 最初の RLHF プログラム
- 仕様策定、キャリブレーション、パイロット、評価、および最初の更新判断をゲートとします。
- 2回目または成熟したプログラム
- 週次またはリリースベースの更新、評価の回帰チェック、およびキューの健全性メトリクスをゲートとします。
ソーシングモデル
- 最初の RLHF プログラム
- チームがキャリブレーションと判定を実行できる場合は直接雇用してください。キューの運用がボトルネックとなっている場合はマネージドサービスを利用してください。
- 2回目または成熟したプログラム
- 安定した人材プールを維持し、モデルや製品の表面的な変更が必要な場合にのみ専門家を追加し、調達手数料と人件費を分けて管理してください。
成功の成果物
- 最初の RLHF プログラム
- 利用可能なルーブリック、ミスを含む評価セット、および評価者のキャパシティモデル。
- 2回目または成熟したプログラム
- 既知のスループット、既知の意見不一致の範囲、および明確なエスカレーションパスを備えた、再現可能な運用リズム。
OpenTrain スコーピングモデル。
プログラムは通常どこで失敗するのか?
品質に関する失敗のほとんどは、測定の失敗です。RewardBenchの報告によると、一部の困難なサブセットは報酬モデルにとって依然として難しく、人間の意見の不一致がベンチマークの信頼性に上限を設ける可能性があるとされています(RewardBench)。内部評価がすぐに飽和してしまう場合、それはおそらく次のモデル更新を管理するには簡単すぎることを意味します。
事実関係やポリシーに敏感な作業については、評価者の判断を容易にしてください。Sparrowは事実の主張に証拠を添付し、敵対的プロービングの下でルール違反を評価しました(DeepMind Sparrow blog、Sparrow paper)。本番環境のプログラムでは、これを早期にLLM evaluationと結びつけてください。評価セットには、パイロットが成功したことを証明する例だけでなく、モデルが依然としてミスをする例を含める必要があります。
システムが高リスクである場合、または本番環境向けである場合、ガバナンスはスコープに含まれます。NISTのAI RMFおよびGenAI Profileは、リスク、測定手法、フィードバックの利用を文書化するための有用な運用リファレンスです。また、EU AI法では、高リスクAIシステムに対して技術文書、ログ記録、人間の監視、堅牢性などのガバナンス慣行を義務付けています(NIST AI RMF 1.0、NIST GenAI Profile、EU AI Act overview)。これは法的助言ではありません。スコープ設定に関する注意喚起です。RLHFパイプラインが高リスクなワークフローに供給される場合、第1週から文書化を開始してください。
最初のプログラムで何を残すべきか?
優れた最初のRLHFプログラムは、以下の3つの再利用可能な資産を残します。
- 繰り返される判定を吸収したルーブリック。
- モデルが依然として取りこぼしている例を含む評価セット。
- チームが運用を再学習することなく毎週実行できる、評価者のキャパシティモデル。
これらの成果物が存在すれば、次のプログラムのスコープ設定はより安価になります。存在しなければ、チームはラベルを購入しただけで、オペレーティングシステムを購入しなかったことになります。
次にすべきこと
引用文献
- OpenAI — Learning from human preferences
- Training language models to follow instructions with human feedback
- Learning to summarize from human feedback
- Anthropic HH-RLHF データセットカード
- Training a Helpful and Harmless Assistant with RLHF
- Sparrow: ターゲットを絞った人間の判断による対話エージェントの調整の改善
- DeepMind — より安全な対話エージェントの構築
- Let’s Verify Step by Step
- RewardBench
- NIST AI RMF 1.0
- NIST 生成AIプロファイル
- EU AI法概要
- OpenTrain の料金