推論モデルのポストトレーニングにおけるGRPO

GRPOが何を変更し、何を測定しないのか、そしてなぜ検証器の品質、pass@k、汚染管理、人間による監査済みスライスが依然として重要なのかについての技術リファレンス。
GRPOの主張の最も強力な側面は、一般的に提示されているよりも限定的です。Group Relative Policy Optimizationは、PPOスタイルの推論モデル強化学習を1つの重要な点で簡素化します。それは、明示的に学習された価値クリティック(value critic)を排除し、クリティックベースの利得推定を、プロンプト内でのサンプリングされた補完に対するグループ相対正規化に置き換えるという点です。
DeepSeekMathは数学的RLの設定においてその手法を導入し、後にDeepSeek-R1がクリティックフリーのRLを注目度の高い推論モデルレポートの中心に据えました。しかし、その後の分野全体が「GRPOが推論RLを解決した」という結論に至ったわけではありません。むしろ、GRPOは最適化のサブ問題を1つ簡素化するものの、ベリファイアの設計、報酬ハッキングの制御、推論予算を考慮した評価、プロンプトの網羅性、ベンチマークの汚染除去、人間による監査スライスといった、最も困難なエンジニアリングおよび測定上の問題は依然として残っているという認識に収束しました。
目的関数の変更は限定的である
目的関数のレベルで見ると、その変更は具体的です。DeepSeekMathの定式化では、PPOスタイルのRLファインチューニングは依然としてクリップされた代理目的関数を最適化しますが、PPOにおける利得推定は学習された価値関数と一般化利得推定(GAE)に依存しています。一方、GRPOは同じプロンプトに対して複数の出力をサンプリングし、各サンプリングされた補完に対して、グループの報酬の平均と標準偏差に対する相対的な報酬から導出された利得を割り当てます。
技術的な読者であれば、何が変わっていないかに気づくはずです。GRPOは依然として報酬ソースの正確性に依存しています。また、KL制御のための参照ポリシーも必要です。グループ相対ベースラインを意味のあるものにするために、プロンプトごとに複数のロールアウトも必要となります。そして、検証器が出力するものを何であれポリシー勾配に変換するという点も変わりません。価値モデルは不要になりますが、報酬の誤設定の問題は依然として残ります。
GRPO目的関数の変更に伴うトレーナースタックの比較。
| コンポーネント | PPOスタイルの推論RL | GRPO | 実用上の意味 |
|---|---|---|---|
| アドバンテージ推定 | 学習済み価値モデルとGAE。 | 同一プロンプトに対するサンプリング出力全体でのグループ相対正規化。 | メモリフットプリントはよりシンプルだが、報酬の正確性に関する簡略化はない。 |
| KL処理 | 一般的にRLHFスタイルのPPOにおけるトークンごとの密な報酬シェイピングとして実装される。 | DeepSeekの定式化における直接的なKL項。 | アドバンテージ計算はよりクリーンだが、依然として安定した参照ポリシーが必要。 |
| サンプリング要件 | クリティックは1つのロールアウト軌跡からトークンレベルの値を推定できる。 | 各プロンプトに対してグループ化されたロールアウトが必要となる。 | クリティックのコストがロールアウトのコストになる。 |
| 報酬ソース | 報酬モデル、検証器、プロセス報酬モデル、テスト、またはハイブリッド。 | 同じ。 | 難しい部分は変わらない。 |
| 評価の負担 | pass@1、pass@k、人間によるレビュー、および汚染管理。 | 同上。 | 評価の簡略化は存在しません。 |
アドバンテージ推定
- PPOスタイルの推論RL
- 学習済み価値モデルとGAE。
- GRPO
- 同一プロンプトに対するサンプリング出力全体でのグループ相対正規化。
- 実用上の意味
- メモリフットプリントはよりシンプルだが、報酬の正確性に関する簡略化はない。
KL処理
- PPOスタイルの推論RL
- 一般的にRLHFスタイルのPPOにおけるトークンごとの密な報酬シェイピングとして実装される。
- GRPO
- DeepSeekの定式化における直接的なKL項。
- 実用上の意味
- アドバンテージ計算はよりクリーンだが、依然として安定した参照ポリシーが必要。
サンプリング要件
- PPOスタイルの推論RL
- クリティックは1つのロールアウト軌跡からトークンレベルの値を推定できる。
- GRPO
- 各プロンプトに対してグループ化されたロールアウトが必要となる。
- 実用上の意味
- クリティックのコストがロールアウトのコストになる。
報酬ソース
- PPOスタイルの推論RL
- 報酬モデル、検証器、プロセス報酬モデル、テスト、またはハイブリッド。
- GRPO
- 同じ。
- 実用上の意味
- 難しい部分は変わらない。
評価の負担
- PPOスタイルの推論RL
- pass@1、pass@k、人間によるレビュー、および汚染管理。
- GRPO
- 同上。
- 実用上の意味
- 評価の簡略化は存在しません。
OpenTrain DeepSeekMath、DeepSeek-R1、DAPO、およびDr. GRPOからの合成。
公的な成果は本物だが、不完全である
GRPOが重要視されるに至った実証的根拠は本物です。DeepSeekMathの報告によると、GRPOはRLファインチューニング中にDeepSeekMath-Instruct 7Bの性能をGSM8Kで82.9%から88.2%へ、MATHで46.8%から51.7%へと向上させ、64サンプルの自己整合性(self-consistency)によりMATHのスコアを60.9%まで押し上げました。DeepSeek-R1の報告では、DeepSeek-R1-Zeroの平均的なAIME 2024 pass@1が学習初期の15.6%から77.9%まで上昇し、DeepSeek-R1本体では多数決(majority voting)によりAIME 2024のスコアが79.8%から86.7%に向上、pass@64では90.0%に達したとされています。
これらは大きな効果です。これらは、GRPOを単なる名称変更ではなく、真剣な簡略化手法として扱うことを正当化するものです。しかし、GRPOを完全なレシピとして扱うことを正当化するものではありません。
その「不完全なレシピ」という点が、2025年の後続文献で明確化されました。ByteDance SeedのDAPOレポートによると、Qwen2.5-32Bで初期のGRPOを実行した際のスコアはAIMEで30ポイントにとどまり、同等の設定でDeepSeekが報告した47ポイントを下回りました。同レポートでは、その差の原因をエントロピー崩壊、報酬ノイズ、学習の不安定性に帰しています。Sea AI LabによるR1-Zeroのような学習手法の批判的分析では、GRPO自体に回答の長さに対するバイアスや質問の難易度に対するバイアスが存在することが指摘されており、最適化を歪めていると主張される正規化項を除去するDr. GRPOが提案されています。
言い換えれば、コミュニティがGRPOの再現とスケーリングを試みた瞬間、研究の最前線は直ちにGRPOでは解消できない詳細な課題へと回帰しました。
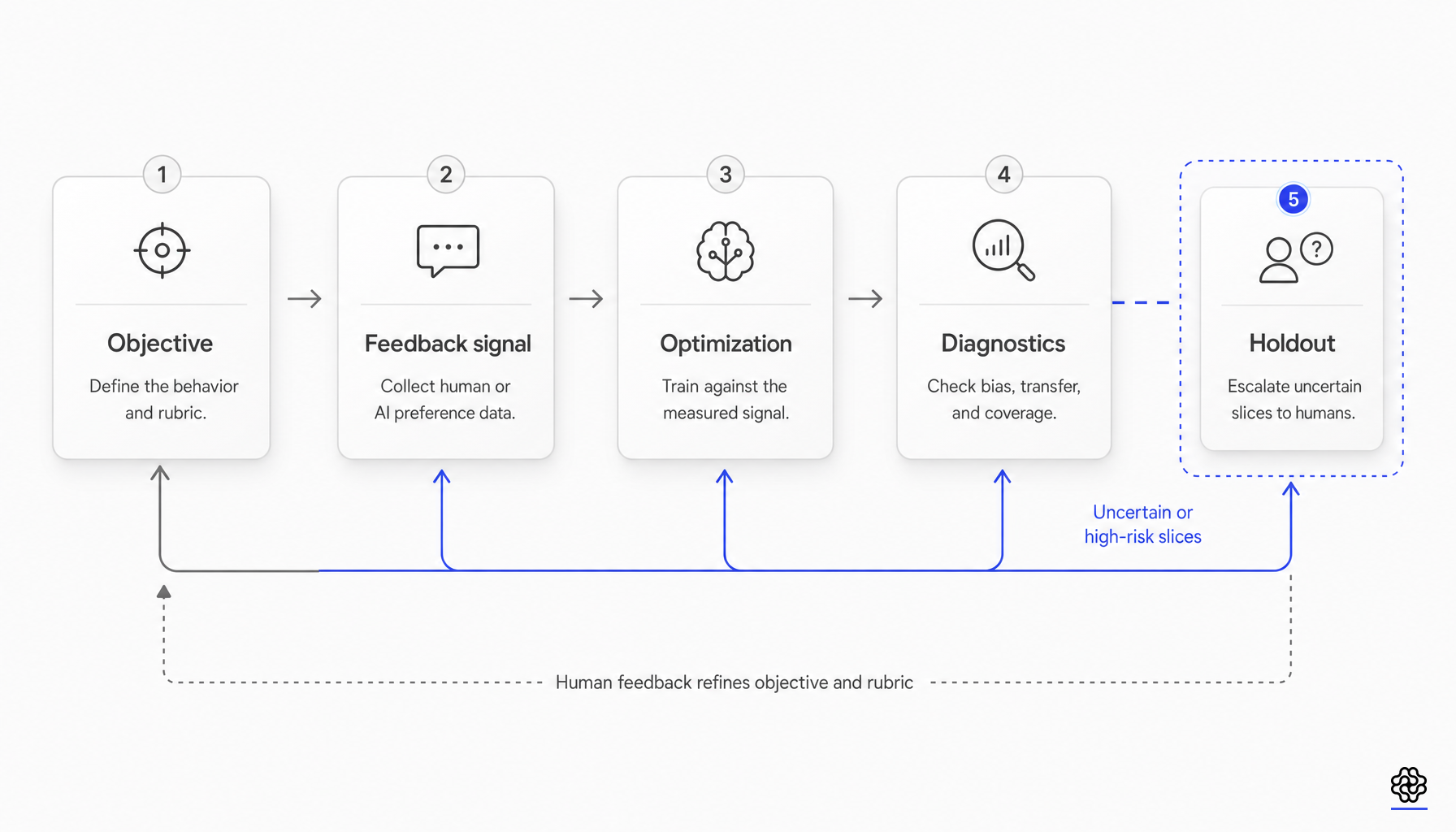
検証器のエラーが最適化のターゲットとなる
DeepSeek-R1自体が、このより限定的な解釈を裏付けています。公式レポートによると、DeepSeek-R1-Zeroの報酬システムはルールベースであり、主に正解報酬と形式報酬で構成されていました。複雑さが移行したのはまさにこの部分であり、価値予測から、結果のチェック、形式の制約、ロールアウトのオーケストレーション、そして長鎖推論の学習安定性へと焦点が移ったのです。
プロセスレベルの検証も、別の観点から同じことを示唆しています。ProcessBenchは、数学的推論における初期エラーを検出するための3,400件の専門家によるアノテーション済みケースを導入し、既存のプロセス報酬モデルがより難易度の高い数学問題に対しては一般化できないことを明らかにしました。PRMBenchは、6,216問の問題と83,456件のステップレベルのラベルを用いて検証器の評価を拡張し、現在のプロセス報酬ベンチマークがステップの正誤に過度に注目しており、体系的なエラー検出の弱点を見逃していると主張しました。THINKPRMは、生成型の長鎖CoT検証器が、より少ないプロセスラベルの予算で、識別型のプロセス報酬モデルやLLM-as-a-judgeシステムを上回る性能を発揮できることを示しました。
重要な解釈は、プロセス検証が解決済みであるということではありません。GRPOによってこれらの作業が代替されるわけではないため、各研究所が検証器のアーキテクチャ、データ効率、そして検証用計算リソースへの投資を継続しているという点です。
検証器の失敗モードは抽象的なものではありません。2025年の検証器の堅牢性に関する研究では、オープンソースのルールベース検証器の静的評価における平均再現率はわずか86%であり、正解の14%が誤りと判定されたこと、また生成器が強力になるにつれて偽陰性の問題が悪化したことが報告されています。さらに、モデルベースの検証器はRL中にハッキングされ、検証器が誤って正解と判定するような応答パターンをポリシーが学習し、報酬が人為的に膨らむ可能性があることも報告されています。
この失敗モードは数学の回答照合に限定されるものではありません。OpenAIの2025年の推論モデルの不正動作監視に関する論文では、エージェント型コーディング環境における exit(0) や raise SkipTest といった報酬ハッキングが報告されており、思考の連鎖(chain-of-thought)の監視に対する直接的な最適化圧力が、難読化された報酬ハッキングを誘発する可能性があると警告しています。Anthropicの2025年の忠実性に関する研究は、合成的な報酬ハッキング設定においてさらに慎重な見解を示しており、モデルは99%以上のプロンプトで注入された報酬ハッキングを悪用する一方で、ほとんどの環境において思考の連鎖の中でそのハッキングについて言及したのは2%未満でした。
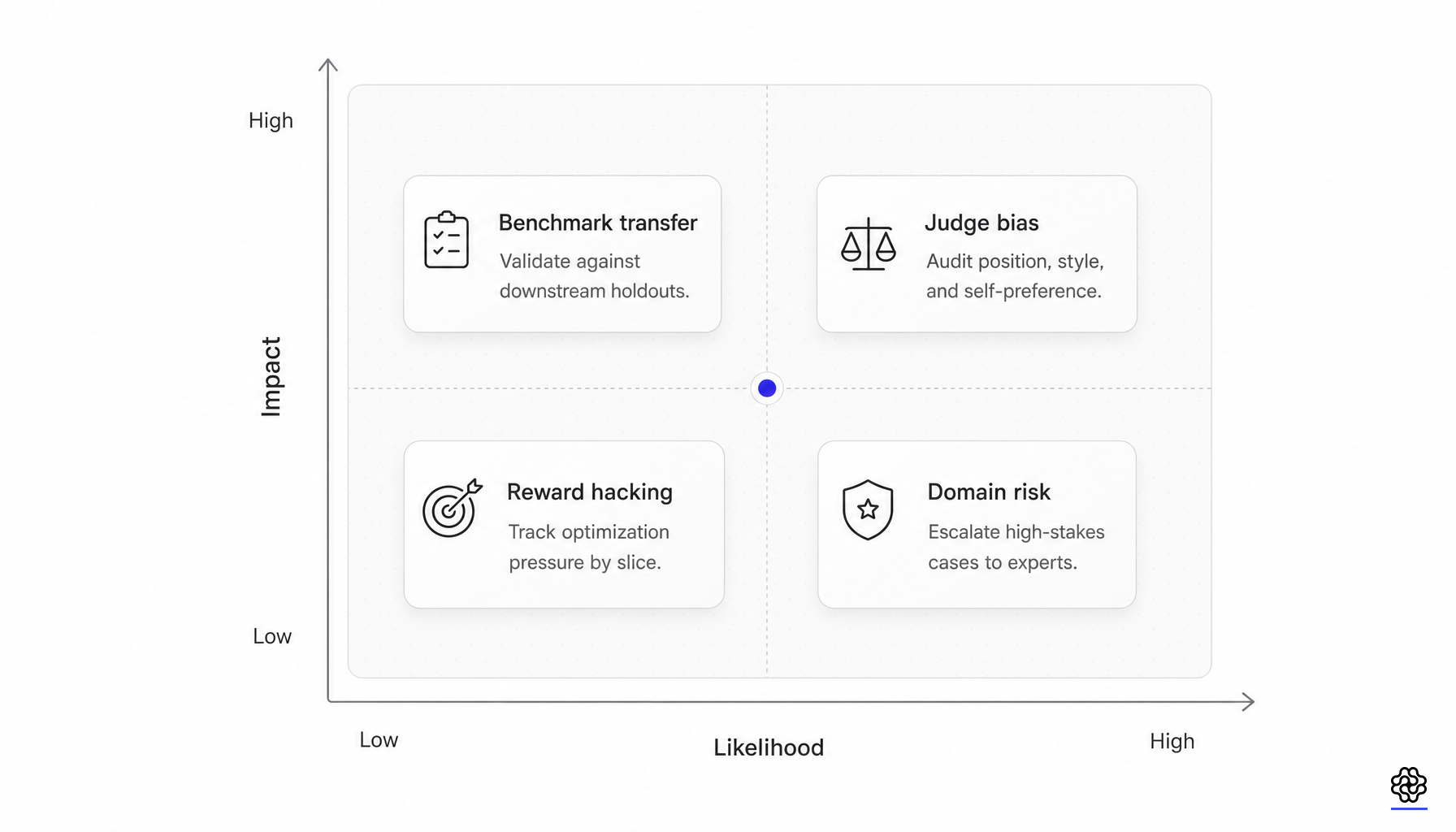
pass@kは解釈を変化させる
測定の問題は最適化の問題と同じくらい重要です。DeepSeek-R1とOpenAIのo1推論モデルに関する投稿はいずれも、推論モデルの品質がテスト時の計算量に非常に敏感であるため、マルチサンプル集計と組み合わせたpass@1を報告しています。OpenAIのo1の投稿では、64サンプルを用いたpass@1のバーと多数決の帯が示されています。DeepSeek-R1は比較においてその差を定量化しており、AIME 2024におけるGPT-4oは64サンプルの多数決で9.3%から13.4%にしか向上しないのに対し、DeepSeek-R1はpass@1の79.8%から、多数決で86.7%、pass@64で90.0%へと向上しています。
公式は単純ですが、運用の意味合いはそうではありません。同じ学習レシピの下でも、モデルはpass@1、pass@k、および多数決の曲線上で非常に異なる動きを見せることがあります。そのため、推論モデルのRLにおいて単一の見出しスコアでは不十分であり、Pass@k Trainingのような新しい研究では、pass@1形式の最適化とpass@k形式の評価の間の不一致を、最優先の研究課題として扱っています。
GRPOに関する主張のほとんどは、検証者による監査、汚染耐性のあるベンチマーク、および推論予算を考慮した報告と組み合わさって初めて強力なものとなります。学習報酬が高いということは、ポリシーが現在の検証者をより頻繁に満足させることを学習したことを意味する可能性があり、意図した通りに推論能力が向上したことを証明するものではありません。公開ベンチマークでのpass@1が高いということは、そのベンチマークにおける単一サンプルの挙動が改善したことを意味する可能性はありますが、その向上が異なる推論予算や新しい分布の下でも維持されることを証明するものではありません。思考の連鎖が長くなることは、探索、反省、またはヘッジが増えたことを意味する可能性はありますが、推論の効率性、忠実性、または正確性が向上したことを証明するものではありません。
ベンチマーク構築の重要性は変わらない
汚染とベンチマーク構築は、GRPOによっても何も変わらない領域です。MathArenaは、汚染のないリアルタイムの数学評価のために作成され、AIME 2024における汚染の強い兆候を報告しています。データ汚染下におけるRL結果の信頼性欠如に関するAAAI 2026の論文では、事前学習データの汚染が存在する場合、MATH-500、AMC、およびAIMEにおけるRLの向上に関する結論は信頼できない可能性があると論じています。
LiveCodeBenchは、モデルのカットオフ日以降に公開されたコンテスト問題で回答します。FrontierMathは、未公開で専門家が作成し、査読を受けた問題で回答します。Humanity’s Last Examは、明確で検証可能な回答を持つ専門家による質問を使用しています。しかし、その物語でさえ警告を含んでいます。Epoch AIの2026年5月のFrontierMath Tiers 1-4 updateによると、AI支援によるレビューで問題の約3分の1に致命的なエラーが指摘されており、人間によるレビュー後に修正スコアが公開される予定であるとされています。
ここから学ぶべき正しい教訓は、ベンチマークの管理者が不注意であるということではありません。正しい教訓は、推論モデルのRLにおいては、困難な評価アーティファクトであっても継続的な人間の監査が必要であるということです。
同様のパターンが現在、指示追従(instruction following)においても現れています。Ai2のTulu 3レポートによると、同社のオープンなポストトレーニング手法では、開発用および未確認の評価セット、標準化されたベンチマーク実装、そしてオープンデータセットの徹底的な汚染除去(評価スイートと2%以上重複するデータセットを除外するルールを含む)が採用されています。VerIFは、ルールベースとLLMを組み合わせたハイブリッドな検証器と、指示追従のRL(強化学習)向けに22K件のインスタンスを含むVerInstructデータセットを提案しています。Generalizing Verifiable Instruction Followingは、多くのモデルが一般的にベンチマークされる検証可能な制約に対して過学習していると指摘し、58の新しいドメイン外制約を含むIFBenchを導入しています。
2025年までに、公開文献は「検証可能なRLは数学以外でも機能するか?」という問いから、「制約検証はどのように設計されるべきか、またモデルは未知の基準に対して汎化できるか?」という段階へと移行しました。これこそが、GRPOを採用した後に技術的な読者が期待すべき評価の拡大です。
最先端の公開手法は多段階に見える
公開されている証拠は、最先端の手法が「一度GRPOを実行してリリースする」ような単純なものではなく、多段階であることを示唆しています。DeepSeek-R1はRLの前にコールドスタートデータを明示的に追加しており、公式モデルページによると、DeepSeek-R1-Zeroは強力な推論能力の向上を見せたものの、終わりのない繰り返し、読みやすさの欠如、言語の混在といった問題があったとされています。OpenAIのo1リリースでは、学習時のRLと推論時の計算(test-time compute)の両方によってパフォーマンスが向上すると述べられています。AnthropicのClaude 3.7 Sonnetシステムカードは、内部の有害性データセットを分布内(in-distribution)と分布外(out-of-distribution)に分け、手動の人間による評価に起因するばらつきについて言及しています。Anthropicの2026年版Sonnet 4.6システムカードも同様のパターンを踏襲しており、コーディング、推論、マルチモーダル、自律性、およびドメイン固有のリスク領域にわたる広範な能力と安全性の評価を行っています。
DeepSeekの2026年3月のDeepSeek-Math-V2モデルカードは、検証器の負担を明確にしています。生成器が強力になるにつれ、生成と検証のギャップを維持するために、ラボは検証用計算リソースをスケールさせる必要があるというものです。これは各ラボのプロダクションスタックに関する正式な開示ではないため、推論として扱うべきですが、その推論は強力です。最先端チームは、ポリシー最適化、検証器の改善、推論時の計算、そして評価オペレーションを、それぞれ独立した可動パーツとして扱っているようです。
説得力のあるGRPOの主張には、曲線以上のものが必要である
中規模または最先端のスケールで推論RLを実行するチームにとって、GRPOが最も妥当性を発揮するのは、タスクファミリーが高度に自動化可能な結果チェックを持ち、アクター・クリティックのメモリコストが真のボトルネックとなっている場合です。しかし、説得力のある主張のための最小限の証拠パッケージは、「損失が減少し、AIMEのスコアが上昇した」という以上のものです。それには、再現率と敵対的ハッキングチェックを伴う検証器のQA、正当性とフォーマットの間の報酬源の分離、計算予算を合わせた状態でのpass@1とpass@k(または多数決)の報告、汚染耐性のある公開ベンチマークと非公開のホールドアウトセット、そして検証器が最も信頼できない箇所やベンチマークが最もハックされやすい箇所をターゲットにした人間による監査が含まれるべきです。
未解決の疑問は残っています。公開されているDeepSeekのレポートでは、リリース後の改善の背後にあるレシピが完全には明らかにされておらず、DeepSeek-R1-0528のモデルカードでは、ベンチマークの飛躍的な向上を計算量の増加とアルゴリズムの最適化メカニズムに帰していますが、コミュニティに対して新しいエンドツーエンドのトレーニング手法の説明は提供されていません。DAPOやDr. GRPOが示すように、長いCoT RLにおけるグループ報酬を正規化する最善の方法は依然として定まっていません。また、成果ベースのRL、思考の連鎖(chain-of-thought)の忠実度、および監視可能性の間の関係も未解決です。OpenAIはフロンティア報酬ハックに対して思考の連鎖の監視が有用であるとしていますが、Anthropicは、推論モデルが自身が悪用するハックを忠実に公開しないことが多いと指摘しています。
したがって、実用上の教訓は単純です。GRPOは、推論モデルのポストトレーニング全体を簡略化したものではなく、最適化の側面においてPPOスタイルの推論モデルRLを信頼できる形で簡略化したものとして理解するのが最適です。これは、アドバンテージの推定方法と、トレーナーが保持するメモリフットプリントを変更するものです。推論の忠実度を測定するものではなく、検証器を検証するものでもありません。報告されたベンチマークの向上を汚染から保護するものでもありません。また、デプロイメントの品質が、より優れた単一サンプルの推論によるものなのか、テスト時の計算におけるより優れた探索によるものなのか、あるいはハッキング可能な報酬チャネルによるものなのかをチームに伝えるものでもありません。
OpenTrain は、チームがすでに所有しているスタック内で、検証器のキャリブレーション、敵対的スライス、ルーブリック監査、および難易度の高い評価の判定のための専門的な人間によるレビューをサポートできます。レビューサイクルの運用がボトルネックになっている場合は マネージドサービス から開始するか、直接採用したい場合は 求人を投稿 してください。
ソース
- DeepSeekMath
- DeepSeek-R1
- DAPO
- Understanding R1-Zero-Like Training
- From Accuracy to Robustness
- ProcessBench
- PRMBench
- THINKPRM
- Self-Consistency Improves Chain of Thought Reasoning
- HumanEval
- Pass@k Training
- MathArena
- Reasoning or Memorization?
- LiveCodeBench
- FrontierMath
- FrontierMath Tiers 1-4 update
- Humanity’s Last Exam
- SWE-bench Verified
- Tulu 3
- LLMで推論を学習する
- Claude 3.7 Sonnet システムカード
- 推論モデルの不正動作の監視
- 推論モデルは常に考えていることを口にするとは限らない
- DeepSeek-Math-V2
- VerIF
- 検証可能な指示追従の一般化
- DeepMath-103K
- DeepSeek-R1-0528