El Red Teaming de IA como un problema de datos de evaluación

El red teaming de IA es útil cuando los hallazgos adversarios se convierten en datos de evaluación reproducibles: modelos de amenazas, rúbricas, adjudicación, controles de fuga.
¿Qué es realmente el red teaming en IA?
Si ya realiza evaluaciones de LLM, la respuesta útil no es “intentar vulnerar un modelo”. La respuesta útil es el descubrimiento adversarial estructurado que genera evidencia. El red teaming de IA es importante cuando le ayuda a diseñar mejores datos de evaluación, pruebas de rechazo, rúbricas de daño y decisiones de lanzamiento. Es menos importante cuando se convierte en una galería de prompts virales. [1]
La distinción es importante porque el campo utiliza varios términos relacionados de manera imprecisa. El red teaming cibernético tradicional es la emulación de adversarios contra la postura de seguridad de una empresa. El red teaming de IA es un esfuerzo estructurado para encontrar fallas y vulnerabilidades en los sistemas de IA, a menudo con la colaboración de los desarrolladores. Una evaluación es más limitada: se le da al sistema una entrada, se aplica una lógica de calificación y se mide si hizo lo que a usted le interesa. Las pruebas de seguridad y las TEVV previas al despliegue son conceptos más amplios que pueden incluir red teaming, pruebas de campo, retroalimentación pública y evaluaciones formales. [1]
Cómo difiere el red teaming de IA del red teaming cibernético y de las evaluaciones estándar.
| Práctica | Unidad de análisis | Objetivo | Resultado típico | Inferencia incorrecta a evitar |
|---|---|---|---|---|
| Equipo rojo cibernético | Organización, red, producto o programa de seguridad. | Emule a los adversarios frente a una postura de seguridad. | Ruta de ataque, narrativa de explotación, lista de remediación. | Un ejercicio cibernético no es automáticamente una evaluación de IA. |
| Red teaming de IA | Modelo de IA, aplicación, estructura o superficie de despliegue. | Descubra fallas, vulnerabilidades y comportamientos dañinos. | Hallazgos, prompts, transcripciones, notas de severidad. | Un jailbreak viral no es automáticamente una medición confiable. |
| Evaluación del modelo | Entrada definida, configuración del sistema, evaluador y métrica. | Mida si un comportamiento objetivo ocurre bajo un arnés establecido. | Puntajes, etiquetas, intervalos de confianza, segmentos de error. | Una puntuación de evaluación solo respalda la afirmación que su arnés puede sustentar. |
| Pruebas de seguridad y TEVV | Ciclo de vida completo de las actividades de evidencia y aseguramiento. | Combine pruebas, evidencia de campo, umbrales de riesgo y revisión. | Registro de riesgos, evidencia de aceptación, plan de monitoreo. | Una ronda de red-teaming por sí sola no prueba que un sistema sea seguro. |
Equipo rojo cibernético
- Unidad de análisis
- Organización, red, producto o programa de seguridad.
- Objetivo
- Emule a los adversarios frente a una postura de seguridad.
- Resultado típico
- Ruta de ataque, narrativa de explotación, lista de remediación.
- Inferencia incorrecta a evitar
- Un ejercicio cibernético no es automáticamente una evaluación de IA.
Red teaming de IA
- Unidad de análisis
- Modelo de IA, aplicación, estructura o superficie de despliegue.
- Objetivo
- Descubra fallas, vulnerabilidades y comportamientos dañinos.
- Resultado típico
- Hallazgos, prompts, transcripciones, notas de severidad.
- Inferencia incorrecta a evitar
- Un jailbreak viral no es automáticamente una medición confiable.
Evaluación del modelo
- Unidad de análisis
- Entrada definida, configuración del sistema, evaluador y métrica.
- Objetivo
- Mida si un comportamiento objetivo ocurre bajo un arnés establecido.
- Resultado típico
- Puntajes, etiquetas, intervalos de confianza, segmentos de error.
- Inferencia incorrecta a evitar
- Una puntuación de evaluación solo respalda la afirmación que su arnés puede sustentar.
Pruebas de seguridad y TEVV
- Unidad de análisis
- Ciclo de vida completo de las actividades de evidencia y aseguramiento.
- Objetivo
- Combine pruebas, evidencia de campo, umbrales de riesgo y revisión.
- Resultado típico
- Registro de riesgos, evidencia de aceptación, plan de monitoreo.
- Inferencia incorrecta a evitar
- Una ronda de red-teaming por sí sola no prueba que un sistema sea seguro.
Definiciones sintetizadas a partir de las directrices del NIST y de evaluación de modelos.
Eso hace que los jailbreaks de demostración sean una unidad de gobernanza débil. NIST advierte que las pruebas de jailbreak y de ingeniería de prompts pueden no evaluar sistemáticamente la validez o la fiabilidad. Microsoft plantea el red teaming como una forma de exponer daños y comprender una superficie de riesgo, no como un reemplazo para la medición sistemática. AISI señala lo mismo desde el lado del evaluador: las pruebas exploratorias pueden indicar preocupaciones, pero las afirmaciones más sólidas requieren una mejor obtención, calificación y mapeo entre los resultados y los umbrales de riesgo. [2]
El objetivo práctico es simple: convertir el descubrimiento en casos que pueda reproducir, etiquetar, auditar y enrutar.
Primero el modelo de amenazas, al final la galería de jailbreaks
Si un programa de red-teaming comienza pidiendo a las personas que “vayan a romper el modelo”, generalmente producirá ejemplos llamativos pero una medición débil. Invierta el orden. Comience estableciendo la afirmación que la evidencia debe respaldar: obtención de capacidades, robustez de las salvaguardas o comparación entre sistemas bajo una configuración compartida. Luego, defina el arnés, las herramientas y el presupuesto que hacen que la afirmación sea significativa.
La guía de evaluación de terceros de OpenAI es directa en este punto: las puntuaciones solo son interpretables si el informe describe qué afirmación respalda la configuración, cómo se obtuvo la respuesta del sistema y qué comprobaciones de validez se realizaron. [3]
Un modelo de amenazas para el red teaming de IA debe nombrar al actor, el comportamiento objetivo, la superficie de ataque y el daño posterior. AISI sostiene que las evaluaciones deben alinearse con modelos de riesgo explícitos y cubrir las rutas relevantes hacia el daño. Microsoft describe una ontología interna que rastrea actores, tácticas, debilidades e impactos posteriores, ya que los hallazgos sin procesar son demasiado confusos para razonar sobre ellos sin una estructura compartida. [4]
Para la mayoría de los equipos, la “superficie de ataque” no debería limitarse al cuadro de texto del prompt. Si el sistema implementado cuenta con recuperación, herramientas, contexto largo, entradas multimodales, conectores o andamiaje de agentes, esas superficies deben incluirse en el alcance. El arnés cambia lo que el sistema puede hacer. OpenAI enfatiza que los andamiajes circundantes pueden cambiar materialmente el rendimiento, especialmente en sistemas agentes. Microsoft recomienda de manera similar probar tanto el modelo base como la capa de aplicación, idealmente a través de la interfaz de usuario de producción cuando sea posible. [3][5]
Aquí es donde comienza el teatro de solo prompts: probar el texto del usuario contra un endpoint de chat simplificado y luego tratar el resultado como evidencia sobre un producto implementado. Eso puede pasar por alto la inyección indirecta de prompts, el uso inseguro de herramientas, la escalada con estado de múltiples turnos, los fallos dependientes de la recuperación y el comportamiento específico del entorno. El problema no es que las pruebas de solo prompts sean inútiles. El problema es tratarlas como si midieran el sistema completo.
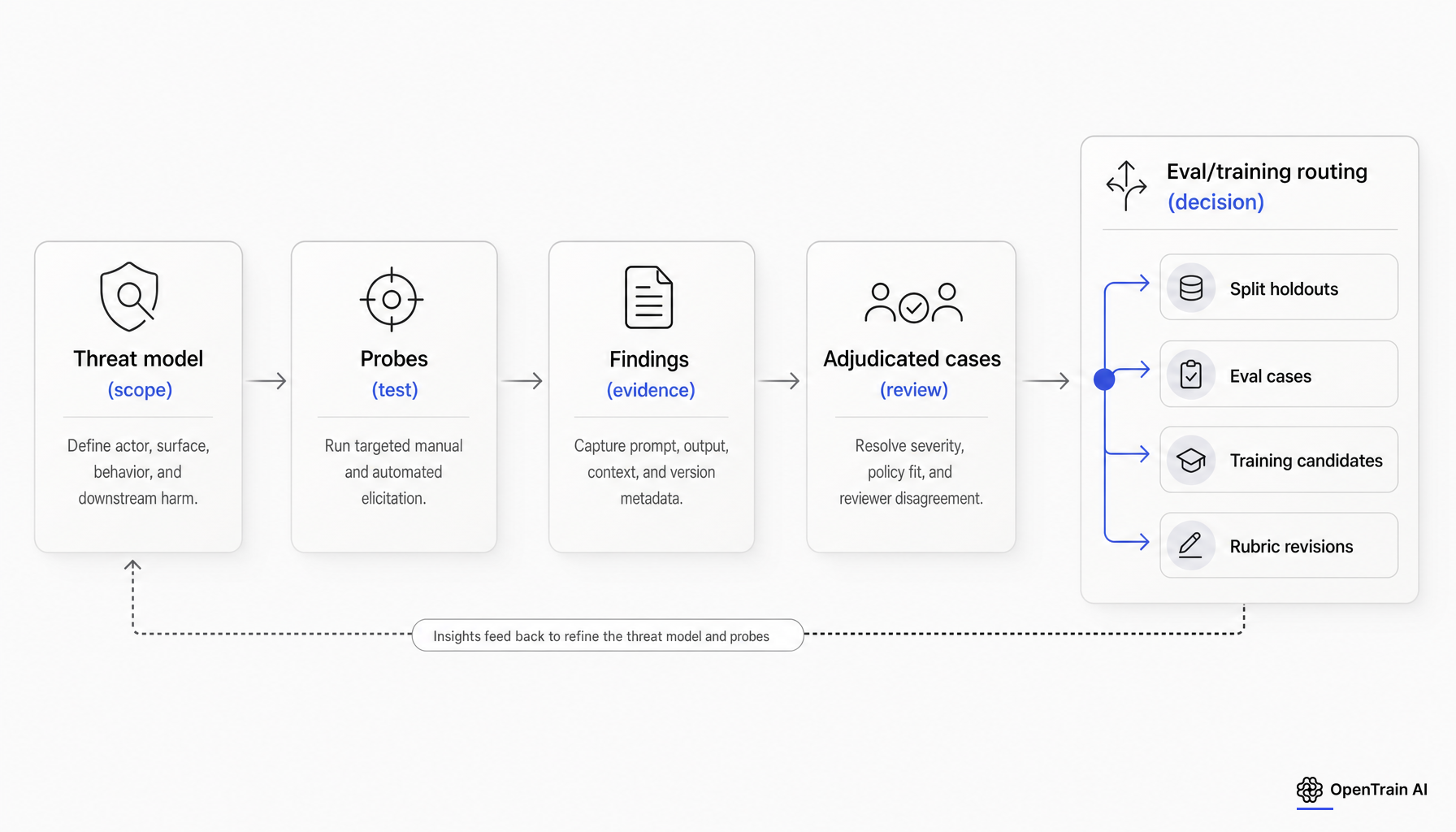
Muestreo, severidad y adjudicación
El muestreo es donde el red teaming se convierte en diseño de evaluación. Google recomienda entradas diversas y representativas a través de políticas de producto, casos de uso, modos de falla, variedad léxica y variedad semántica. Microsoft recomienda comenzar con pruebas abiertas para descubrir daños y luego pasar a rondas guiadas basadas en una lista de daños en evolución. En la práctica, una muestra no debería ser una lista pública de jailbreak más algunos prompts improvisados. Debería ser una porción planificada a través de categorías de daño, intenciones del usuario, superficies, idiomas y estrategias de obtención plausibles. [6]
La gravedad también necesita estructura antes de que el programa escale. El NIST define el riesgo como una combinación de probabilidad y consecuencia. Para el etiquetado de red-teaming, ese es un punto de partida, no una rúbrica terminada. La mayoría de los equipos también necesitan dimensiones como el tipo de daño, la capacidad de acción, la reproducibilidad, el realismo y si el comportamiento persiste después de las salvaguardas habituales. Esta rúbrica es una síntesis editorial basada en el marco de riesgo del NIST y en la práctica de evaluación, no un estándar citado. [2]
La adjudicación es donde los equipos a menudo fallan silenciosamente. Google señala que los humanos pueden anotar contenido problemático de manera diferente y recomienda directrices o plantillas claras para los evaluadores. OpenAI recomienda rúbricas claras, niveles de puntuación de ejemplo, umbrales de aprobación/fallo y agregación de consenso cuando se utilizan múltiples revisores. Para casos de alta gravedad o con políticas ambiguas, trate el desacuerdo humano como una señal sobre el sistema de medición, no solo como ruido del etiquetador. [6][7]
Una regla operativa útil es la siguiente: si un hallazgo es de alta gravedad, tiene una política ambigua o está especializado en un dominio, escálelo de un etiquetado de revisión única a una adjudicación experta. Si los revisores no están de acuerdo sobre si el modelo violó la política, el caso generalmente debería impulsar la revisión de la rúbrica antes de impulsar el post-training. Esa recomendación es una síntesis, pero se deriva de la guía citada sobre la claridad de la rúbrica, la calibración y la revisión humana.
Divida el trabajo humano y automatizado a propósito
La automatización ayuda más cuando el trabajo consiste en amplitud, actualización y detección de señales débiles. El trabajo de Anthropic sobre evaluaciones escritas por modelos demostró que estos pueden ayudar a generar muchos elementos de evaluación relevantes rápidamente, con un alto nivel de acuerdo entre los trabajadores de la multitud sobre las etiquetas en ese entorno. AISI argumenta que las evaluaciones de capacidad automatizadas son lo suficientemente escalables como para cubrir una gran parte de una superficie de capacidad preocupante. Google también recomienda comenzar con ejemplos semilla y expandirlos sintéticamente cuando los conjuntos de datos existentes sean insuficientes. [8][4][6]
Las mismas fuentes también definen los límites. AISI afirma que las pruebas automatizadas no reflejan el uso en el mundo real y no deberían, por sí solas, respaldar conclusiones sólidas. Google advierte que la precisión del clasificador puede ser baja para constructos definidos de manera imprecisa. OpenAI dice que las evaluaciones son más que simples puntajes y recomienda calibrar la puntuación automatizada frente al juicio humano. [4][6][7]
Las pruebas automatizadas son fuertes en tres aspectos. Primero, mejoran la cobertura al generar más variantes léxicas y semánticas de las que un equipo humano pequeño puede producir. Segundo, hacen que las pruebas de regresión sean económicas una vez que un caso se convierte en una evaluación reutilizable. Tercero, permiten a los equipos atacar un sistema a escala con muestreos repetidos, lo cual es importante porque algunas clases de jailbreak mejoran con más intentos. El trabajo de many-shot de Anthropic es un ejemplo de cómo el contexto largo crea nuevos modos de falla. [9]
Las herramientas ahora reflejan esta división del trabajo. Microsoft PyRIT es un marco de trabajo agnóstico al modelo para probar sistemas multimodales y reutilizar bloques de construcción de red-team componibles. AISI Inspect admite diálogos de múltiples turnos, estructuras de agentes, calificación de modelos y registros detallados. Esas herramientas son útiles porque los hallazgos del red-team deben convertirse en artefactos de evaluación analizables, no en notas sueltas. [10][11]
Los humanos siguen siendo necesarios cuando la pregunta no es solo “¿falló la política?” sino “¿qué es lo que realmente importa aquí?”. Microsoft es directo: la medicina, la ciberseguridad, los riesgos CBRN, los daños interculturales y los daños psicosociales requieren un juicio basado en la materia. AISI describe de manera similar el red teaming de expertos como más naturalista y abierto que las pruebas automatizadas. [12][4]
Los jueces LLM necesitan el mismo escepticismo. OpenAI recomienda formatos de comparación por pares o de aprobado/reprobado, rúbricas claras y validación frente a etiquetas humanas, ya que los modelos de jueces pueden verse sesgados por el orden de las respuestas y su longitud. Utilice jueces LLM como instrumentos de medición: calíbrelos, verifique si hay desviaciones y audítelos periódicamente. No les otorgue autoridad final sobre daños especializados o límites de políticas ambiguos. [7]
Donde la automatización ayuda y donde los humanos siguen siendo importantes.
| Método | Mejor uso | Ventaja principal | Punto ciego principal | ¿Se requiere revisión humana? |
|---|---|---|---|---|
| Sondas automatizadas | Intentos repetidos y amplios a través de tácticas conocidas. | Escala la cobertura y la frecuencia de actualización. | Puede pasar por alto el contexto realista del producto y el daño al dominio. | Sí, para casos graves o ambiguos. |
| Variantes generadas por el modelo | Ampliación de ejemplos semilla a través de la redacción y la semántica. | Encuentra vecinos léxicos y semánticos rápidamente. | Puede sobreajustarse a variaciones sencillas. | Sí, para la calibración de etiquetas y comprobaciones de novedad. |
| Clasificadores | Preselección de grandes volúmenes de resultados. | Triaje y monitoreo económico. | Baja precisión en construcciones imprecisas. | Sí, para decisiones de política y gravedad. |
| jueces de LLM | Calificación de aprobado/reprobado o por pares con rúbricas claras. | Puntuación rápida y reutilizable cuando está calibrada. | Sesgo de orden, longitud, estilo y dominio. | Sí, con auditorías humanas periódicas. |
| Conjuntos de regresión programados | Volver a ejecutar casos conocidos después de cambios en el modelo o en la política. | Reproducción estable y comparación de diferencias. | Mide los modos de falla de ayer. | Sí, cuando las regresiones son de alto riesgo. |
| Expertos en dominios humanos | Medicina, seguridad, NBQR, cultural, legal o daños psicosociales. | Juicio de contexto y consecuencia. | Rendimiento limitado y desacuerdo sin rúbricas. | Ellos son la ruta de revisión. |
Sondas automatizadas
- Mejor uso
- Intentos repetidos y amplios a través de tácticas conocidas.
- Ventaja principal
- Escala la cobertura y la frecuencia de actualización.
- Punto ciego principal
- Puede pasar por alto el contexto realista del producto y el daño al dominio.
- ¿Se requiere revisión humana?
- Sí, para casos graves o ambiguos.
Variantes generadas por el modelo
- Mejor uso
- Ampliación de ejemplos semilla a través de la redacción y la semántica.
- Ventaja principal
- Encuentra vecinos léxicos y semánticos rápidamente.
- Punto ciego principal
- Puede sobreajustarse a variaciones sencillas.
- ¿Se requiere revisión humana?
- Sí, para la calibración de etiquetas y comprobaciones de novedad.
Clasificadores
- Mejor uso
- Preselección de grandes volúmenes de resultados.
- Ventaja principal
- Triaje y monitoreo económico.
- Punto ciego principal
- Baja precisión en construcciones imprecisas.
- ¿Se requiere revisión humana?
- Sí, para decisiones de política y gravedad.
jueces de LLM
- Mejor uso
- Calificación de aprobado/reprobado o por pares con rúbricas claras.
- Ventaja principal
- Puntuación rápida y reutilizable cuando está calibrada.
- Punto ciego principal
- Sesgo de orden, longitud, estilo y dominio.
- ¿Se requiere revisión humana?
- Sí, con auditorías humanas periódicas.
Conjuntos de regresión programados
- Mejor uso
- Volver a ejecutar casos conocidos después de cambios en el modelo o en la política.
- Ventaja principal
- Reproducción estable y comparación de diferencias.
- Punto ciego principal
- Mide los modos de falla de ayer.
- ¿Se requiere revisión humana?
- Sí, cuando las regresiones son de alto riesgo.
Expertos en dominios humanos
- Mejor uso
- Medicina, seguridad, NBQR, cultural, legal o daños psicosociales.
- Ventaja principal
- Juicio de contexto y consecuencia.
- Punto ciego principal
- Rendimiento limitado y desacuerdo sin rúbricas.
- ¿Se requiere revisión humana?
- Ellos son la ruta de revisión.
Basado en la clasificación de AISI, las pruebas adversarias de Google, las prácticas de evaluación de OpenAI, las evaluaciones escritas por modelos de Anthropic y las lecciones de red teaming de Microsoft.
Una buena división operativa es sencilla. Deje que la automatización genere ataques candidatos, amplíe los conjuntos semilla, etiquete previamente los casos obvios, agrupe los duplicados y vuelva a ejecutar las regresiones. Deje que los humanos definan la lista de daños, revisen los casos inciertos o graves, auditen la calidad del juicio e interpreten lo que significa el fallo del sistema para el producto o modelo. Esa división es una síntesis basada en las fuentes anteriores.
Trate los hallazgos como objetos de datos, no como anécdotas
Si los resultados del red-teaming deben convertirse en datos de evaluación reutilizables, capture más que solo el prompt y la respuesta final. Microsoft recomienda registrar al menos la fecha en que se detectó, el identificador único, el prompt de entrada y los detalles de salida. Google recomienda anotar las salidas en modos de falla y daños. El modelo de registro de Inspect muestra lo que una representación más madura puede preservar: entrada, metadatos de muestra, puntuaciones, errores, mensajes y seguimientos de eventos en múltiples niveles de granularidad. [5][6][11]
Para los equipos aplicados, el esquema mínimo útil suele ser más amplio. Además del prompt y la respuesta, conserve la versión del modelo, la versión o hash del system prompt, la configuración de herramientas, el contexto o las referencias de recuperación, el método de ataque, la categoría de política, el estado de rechazo, la etiqueta del revisor, la etiqueta de severidad, la justificación, el estado de adjudicación, el clúster de casos y el estado de enrutamiento. Esta lista exacta de campos es una síntesis, pero es una extensión práctica de la orientación actual sobre captura estructurada, metadatos y puntuación.
El manejo de duplicados es más importante de lo que la mayoría de los equipos espera. Google recomienda evitar la duplicación y los ejemplos ruidosos con etiquetas múltiples al generar conjuntos de datos adversarios. Sin la deduplicación, los “modos de falla principales” a menudo colapsan en unas pocas plantillas de ataque virales, lo que luego sesga tanto el trabajo de mitigación como los datos de entrenamiento. Mantenga una noción de caso canónico frente a clúster de paráfrasis, e informe tanto el recuento bruto como el recuento único de familias de ataque. La recomendación de canónico frente a clúster es una síntesis, pero la necesidad de singularidad y composición cuidadosa proviene directamente de la orientación de Google. [6]
Un esquema de casos de red-teaming reutilizable para evaluación y bucles de post-entrenamiento.
| Campo | Por qué es importante | ¿Seguro para entrenamiento? | ¿Seguro para conjunto de prueba? | Notas |
|---|---|---|---|---|
| ID de caso | Mantiene la revisión, las nuevas ejecuciones y la corrección rastreables. | Sí | Sí | Los ID estables deben sobrevivir a la agrupación de paráfrasis. |
| Prompt/entrada | Define el artefacto de obtención. | A veces | Sí | Los prompts de validación exactos no deben convertirse posteriormente en ejemplos de entrenamiento. |
| Salida del modelo | Captura el comportamiento observado. | A veces | Sí | Incluya rechazos, completados parciales y resultados de herramientas. |
| Versión del modelo | Evita comparaciones falsas entre sistemas cambiantes. | Sí | Sí | Registre el modelo, el punto de control y el canal de lanzamiento correspondiente. |
| Hash del prompt del sistema | Vincula el comportamiento a las instrucciones sin exponer secretos. | Sí | Sí | Utilice hashes o referencias controladas cuando los prompts sean confidenciales. |
| Contexto de herramienta/recuperación | Muestra lo que el arnés implementado puso a disposición. | A veces | Sí | Crítico para RAG, uso de herramientas, contexto largo y pruebas de agentes. |
| Método de ataque | Admite cobertura y deduplicación. | Sí | Sí | Los ejemplos incluyen jailbreak directo, inyección indirecta, juego de roles o escalada de múltiples turnos. |
| Categoría de política | Conecta el hallazgo con la rúbrica. | Sí | Sí | Revise las categorías cuando la adjudicación exponga ambigüedad. |
| Estado de rechazo | Separa el cumplimiento inseguro de la negativa excesiva. | Sí | Sí | No agrupe todas las negativas como éxitos. |
| Etiqueta del revisor | Define la decisión del juez humano o calibrado. | Sí | Sí | Realice un seguimiento del tipo de revisor y del estado de calibración. |
| Gravedad | Prioriza la remediación y las puertas de lanzamiento. | Sí | Sí | Las dimensiones de severidad son una síntesis, no un estándar universal. |
| Justificación | Hace posibles las auditorías posteriores. | Sí | Sí | Las justificaciones breves son mejores que las etiquetas de clase opacas. |
| Estado de adjudicación | Separa las etiquetas de revisión única de los casos resueltos. | Sí | Sí | Los casos de alta gravedad y en disputa requieren escalamiento. |
| ID de clúster | Evita que los prompts duplicados dominen los informes. | Sí | Sí | Informe el recuento bruto y el recuento único de familias de ataques por separado. |
| Estado de enrutamiento | Evita la fuga entre el entrenamiento y la medición. | Sí, cuando se dirige al entrenamiento | Sí, cuando está bloqueado como conjunto de prueba | Los estados posibles incluyen candidato de entrenamiento, caso de evaluación, conjunto de prueba bloqueado, revisión de rúbrica o evidencia de lanzamiento. |
ID de caso
- Por qué es importante
- Mantiene la revisión, las nuevas ejecuciones y la corrección rastreables.
- ¿Seguro para entrenamiento?
- Sí
- ¿Seguro para conjunto de prueba?
- Sí
- Notas
- Los ID estables deben sobrevivir a la agrupación de paráfrasis.
Prompt/entrada
- Por qué es importante
- Define el artefacto de obtención.
- ¿Seguro para entrenamiento?
- A veces
- ¿Seguro para conjunto de prueba?
- Sí
- Notas
- Los prompts de validación exactos no deben convertirse posteriormente en ejemplos de entrenamiento.
Salida del modelo
- Por qué es importante
- Captura el comportamiento observado.
- ¿Seguro para entrenamiento?
- A veces
- ¿Seguro para conjunto de prueba?
- Sí
- Notas
- Incluya rechazos, completados parciales y resultados de herramientas.
Versión del modelo
- Por qué es importante
- Evita comparaciones falsas entre sistemas cambiantes.
- ¿Seguro para entrenamiento?
- Sí
- ¿Seguro para conjunto de prueba?
- Sí
- Notas
- Registre el modelo, el punto de control y el canal de lanzamiento correspondiente.
Hash del prompt del sistema
- Por qué es importante
- Vincula el comportamiento a las instrucciones sin exponer secretos.
- ¿Seguro para entrenamiento?
- Sí
- ¿Seguro para conjunto de prueba?
- Sí
- Notas
- Utilice hashes o referencias controladas cuando los prompts sean confidenciales.
Contexto de herramienta/recuperación
- Por qué es importante
- Muestra lo que el arnés implementado puso a disposición.
- ¿Seguro para entrenamiento?
- A veces
- ¿Seguro para conjunto de prueba?
- Sí
- Notas
- Crítico para RAG, uso de herramientas, contexto largo y pruebas de agentes.
Método de ataque
- Por qué es importante
- Admite cobertura y deduplicación.
- ¿Seguro para entrenamiento?
- Sí
- ¿Seguro para conjunto de prueba?
- Sí
- Notas
- Los ejemplos incluyen jailbreak directo, inyección indirecta, juego de roles o escalada de múltiples turnos.
Categoría de política
- Por qué es importante
- Conecta el hallazgo con la rúbrica.
- ¿Seguro para entrenamiento?
- Sí
- ¿Seguro para conjunto de prueba?
- Sí
- Notas
- Revise las categorías cuando la adjudicación exponga ambigüedad.
Estado de rechazo
- Por qué es importante
- Separa el cumplimiento inseguro de la negativa excesiva.
- ¿Seguro para entrenamiento?
- Sí
- ¿Seguro para conjunto de prueba?
- Sí
- Notas
- No agrupe todas las negativas como éxitos.
Etiqueta del revisor
- Por qué es importante
- Define la decisión del juez humano o calibrado.
- ¿Seguro para entrenamiento?
- Sí
- ¿Seguro para conjunto de prueba?
- Sí
- Notas
- Realice un seguimiento del tipo de revisor y del estado de calibración.
Gravedad
- Por qué es importante
- Prioriza la remediación y las puertas de lanzamiento.
- ¿Seguro para entrenamiento?
- Sí
- ¿Seguro para conjunto de prueba?
- Sí
- Notas
- Las dimensiones de severidad son una síntesis, no un estándar universal.
Justificación
- Por qué es importante
- Hace posibles las auditorías posteriores.
- ¿Seguro para entrenamiento?
- Sí
- ¿Seguro para conjunto de prueba?
- Sí
- Notas
- Las justificaciones breves son mejores que las etiquetas de clase opacas.
Estado de adjudicación
- Por qué es importante
- Separa las etiquetas de revisión única de los casos resueltos.
- ¿Seguro para entrenamiento?
- Sí
- ¿Seguro para conjunto de prueba?
- Sí
- Notas
- Los casos de alta gravedad y en disputa requieren escalamiento.
ID de clúster
- Por qué es importante
- Evita que los prompts duplicados dominen los informes.
- ¿Seguro para entrenamiento?
- Sí
- ¿Seguro para conjunto de prueba?
- Sí
- Notas
- Informe el recuento bruto y el recuento único de familias de ataques por separado.
Estado de enrutamiento
- Por qué es importante
- Evita la fuga entre el entrenamiento y la medición.
- ¿Seguro para entrenamiento?
- Sí, cuando se dirige al entrenamiento
- ¿Seguro para conjunto de prueba?
- Sí, cuando está bloqueado como conjunto de prueba
- Notas
- Los estados posibles incluyen candidato de entrenamiento, caso de evaluación, conjunto de prueba bloqueado, revisión de rúbrica o evidencia de lanzamiento.
La lista de campos combina documentación de herramientas y orientación operativa; el enrutamiento de entrenamiento/holdout es una síntesis editorial.
Decida en qué se convierte cada hallazgo antes de entrenar con él
Esta es la pregunta operativa fundamental, y la respuesta debe quedar por escrito antes de la primera reunión de post-entrenamiento.
Un caso de red-teaming puede convertirse en al menos cinco cosas distintas: un ejemplo de entrenamiento, un caso de evaluación reutilizable, un conjunto de exclusión bloqueado, una revisión de políticas o rúbricas, o evidencia para la aprobación de lanzamiento. Las fuentes principales actuales respaldan la necesidad de estas vías separadas, aunque no las agrupen en un flujo de trabajo estándar. OpenAI advierte sobre no filtrar datos de evaluación en el ajuste fino por refuerzo, describe evaluaciones derivadas de la producción que se actualizan periódicamente y enfatiza riesgos de validez como la contaminación y el hackeo de recompensas. AISI argumenta de manera similar a favor de umbrales predefinidos y pruebas repetidas a lo largo del ciclo de vida del modelo. [13][14][3][4]
Un caso es un candidato de entrenamiento razonable cuando la etiqueta es estable, el fallo es representativo de un uso realista, el límite de la política es claro y el ejemplo no está reservado para mediciones futuras. El trabajo previo de red-teaming de Anthropic descubrió que utilizar datos de red-teaming en métodos de seguridad reducía la susceptibilidad al corpus de ataques estudiado. Es por eso que los equipos se sienten tentados a entrenar con todo. También es la razón por la que el control de fugas es importante: si esos mismos casos se utilizan más tarde como evidencia de progreso, la medición queda comprometida. [15]
Mantenga un caso fuera del entrenamiento cuando sea necesario como conjunto de prueba, cuando se parezca a un benchmark público o a un posible benchmark futuro, cuando la etiqueta sea objeto de disputa, o cuando el exploit sea tan específico que entrenar con él enseñaría al modelo principalmente a memorizar un parche. La nota de contaminación de BrowseComp de Anthropic muestra cómo la fuga de datos públicos puede inflar los resultados, y el análisis de SWE-bench Verified de OpenAI muestra el mismo patrón de fallo a escala de benchmark. En ambos casos, la lección es la misma: el mismo artefacto no puede ser material de entrenamiento y evidencia de medición honesta al mismo tiempo. [16][17]
Regla de enrutamiento práctica: si un caso expuso un modo de falla novedoso, bloquéelo primero en un grupo de retención. Solo después de actualizar el grupo de retención y probar la solución en casos nuevos debería considerar mover variantes de ese patrón de falla al entrenamiento. Esa regla es una síntesis, pero respeta la guía actual sobre fugas de datos de fuentes de proveedores y evaluadores.
Un modelo operativo de equipo pequeño que no pretende garantizar la seguridad
Para un equipo de IA pequeño, el objetivo no es “cubrirlo todo”. El objetivo es crear un ciclo que produzca evidencia en la que usted seguirá confiando después de que el modelo cambie.
Comience con un modelo de amenaza concreto y relevante para la implementación, una superficie de producto limitada y una ronda de descubrimiento manual. Utilice evaluadores diversos si es posible, pero como mínimo incluya a alguien que comprenda el daño en el dominio y a alguien que pueda pensar de forma adversaria sobre la interfaz del sistema. Microsoft recomienda evaluadores diversos y asignaciones explícitas a daños o funciones; Google recomienda comenzar con ejemplos semilla y expandirlos cuidadosamente; OpenAI recomienda crear evaluaciones desde el principio, registrar todo y calibrar la automatización con etiquetas humanas. [5][6][7]
Luego, congele el primer tramo de hallazgos de alta confianza en un conjunto de evaluación adversarial reservado. No realice ajustes (fine-tuning) en esos casos exactos. Cree ejecuciones de regresión simples en torno a ellos, incluso si el evaluador es de tipo aprobado/reprobado con auditoría humana. Una vez que eso funcione, añada una segunda línea para los candidatos de entrenamiento y mantenga la división limpia. La guía de evaluación de OpenAI enfatiza repetidamente los datos reservados, la no superposición y los conjuntos de entrenamiento separados para los bucles de post-entrenamiento. [13][7]
Después de eso, la automatización vale la pena. Utilice expansiones generadas por modelos, clasificadores o jueces LLM para ampliar la cobertura y reducir el costo de revisión, pero solo en áreas donde haya establecido qué significa una etiqueta correcta. El enfoque escalonado de AISI es una plantilla útil: deje que las pruebas automatizadas más ligeras encuentren preocupaciones rápidamente, luego escale a la obtención personalizada y a la revisión de expertos cuando la señal sea importante. [4]
Nada de esto demuestra que un sistema sea seguro. Esa es la promesa equivocada. Un buen ciclo de red-teaming le proporciona casos que puede reproducir, etiquetas que puede defender, datos de prueba con los que no entrenó y suficiente estructura para determinar si una mitigación cambió el modelo o solo parcheó un prompt de demostración.
OpenTrain puede ayudar a los equipos a contratar expertos en red-teaming, revisores de dominio y especialistas en evaluación para ese trabajo. Utilice la referencia de confiabilidad del juez LLM para la calibración de evaluadores, la guía de RLAIF frente a RLHF para los límites de la automatización, la referencia de PRM frente a ORM para el diseño de objetivos de medición y la guía de alcance de RLHF para la planificación del ciclo de revisión. Cuando el cuello de botella sea la dotación de personal para el ciclo de revisión, publique un trabajo.
Fuentes
- Glosario del NIST: red team; Glosario del NIST: red-teaming de inteligencia artificial; Perfil de IA generativa del RMF de IA del NIST
- Perfil de IA Generativa del NIST AI RMF
- OpenAI: Fundamentos de evaluaciones de terceros confiables
- AISI: Primeras lecciones de la evaluación de sistemas de IA de frontera
- Microsoft Learn: Planificación de red teaming para LLMs
- Google: Pruebas adversarias para IA generativa
- OpenAI: Mejores prácticas de evaluación
- Anthropic: Descubriendo comportamientos de modelos de lenguaje con evaluaciones escritas por modelos
- Anthropic: Many-shot jailbreaking
- PyRIT: Un marco para la identificación de riesgos de seguridad y red teaming en sistemas de IA generativa
- Documentación de Inspect AI
- Microsoft Research: Lecciones del Red Teaming de 100 productos de IA generativa; Resumen del blog de seguridad de Microsoft
- OpenAI cookbook: Diseño de sistemas basado en evaluaciones
- OpenAI: Evaluaciones de producción
- Anthropic: Red Teaming de LLM para reducir daños
- Anthropic: Eval awareness and BrowseComp
- OpenAI: Why we no longer evaluate on SWE-bench Verified