Modelos de recompensa de proceso vs. resultado en sistemas de razonamiento

Una referencia técnica sobre los modelos de recompensa de proceso frente a los de resultado, la confiabilidad del verificador, la transferencia de puntos de referencia, el hackeo.
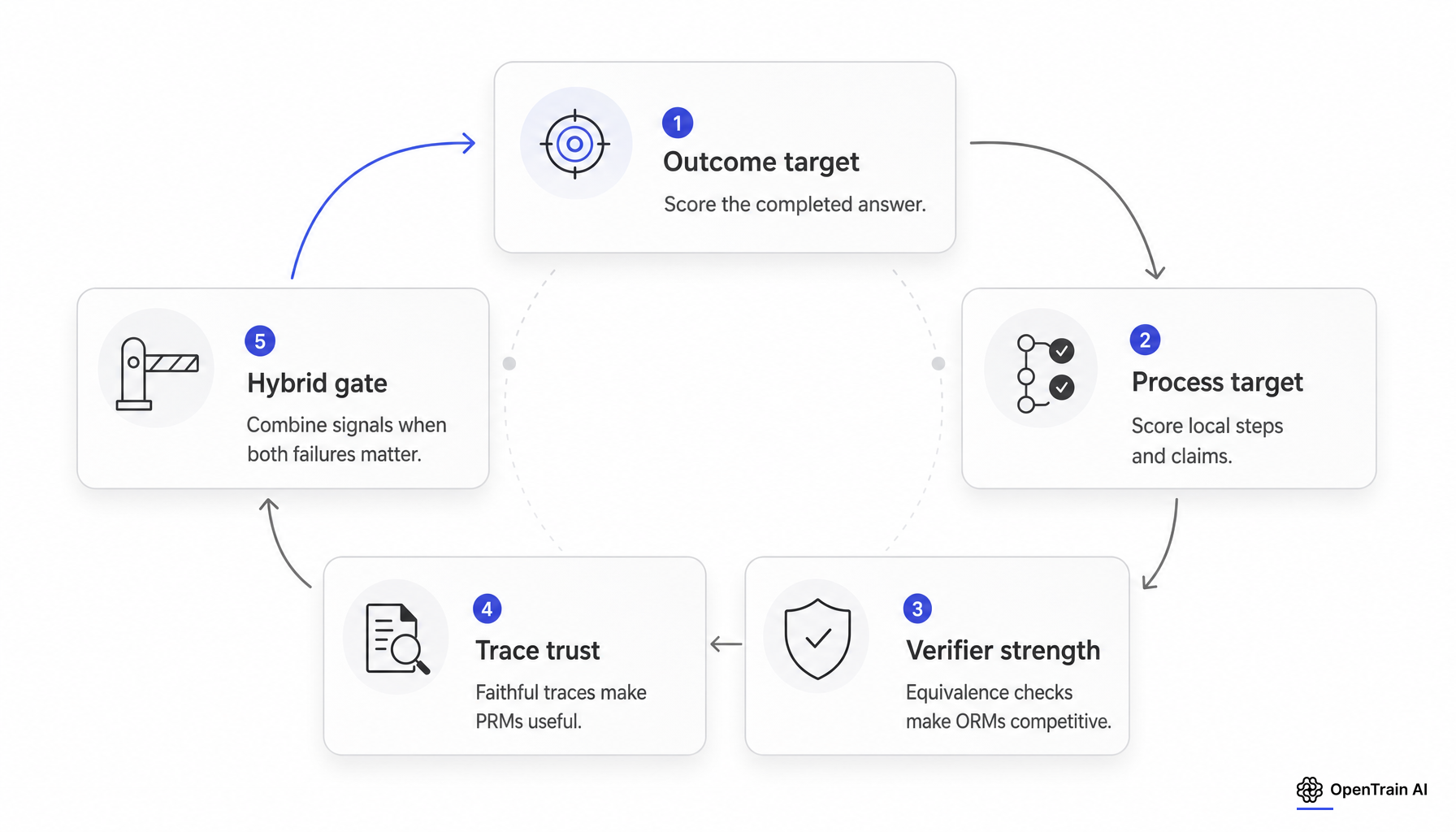
La cuestión técnica actual no es si los modelos de recompensa de proceso superan a los modelos de recompensa de resultado en abstracto. Es si el pipeline de entrenamiento o evaluación intenta medir la exactitud de la respuesta, la exactitud de la trayectoria, la utilidad de la búsqueda o algún híbrido de los tres.
Trabajos recientes hacen que la simple historia de que “los PRM son mejores porque son más densos” sea difícil de defender. Los artículos fundamentales de supervisión de procesos aún muestran ganancias reales en tareas de tipo matemático y un diagnóstico más limpio de los errores intermedios. Las comparaciones multidominio más recientes, los artículos sobre verificadores y los informes de manipulación de recompensas muestran que las configuraciones basadas en resultados o verificadores pueden igualar o superar a los PRM cuando las etiquetas de los pasos son ruidosas, los rastros no están disponibles o no son fieles, y el benchmark recompensa la exactitud final más que el razonamiento sólido.
La elección defendible depende del objetivo, no de la ideología.
La comparación es un desajuste de objetivos
A nivel del objetivo de supervisión, los PRM y los ORM resuelven diferentes problemas de estimación. A un ORM o verificador de respuestas asociado a la trayectoria completa generalmente se le pregunta si la respuesta final o la respuesta completada debe ser aceptada. A un PRM se le pide que califique prefijos, pasos o afirmaciones intermedias para que el entrenamiento o la búsqueda puedan asignar crédito antes de que se conozca la respuesta final.
Esa diferencia importa porque la misma trayectoria puede ser correcta en el resultado pero poco sólida en el proceso, o mayormente sólida en el proceso pero incorrecta en el resultado debido a un error aritmético tardío. Uesato et al. hicieron explícita esta distinción en GSM8K: la supervisión basada puramente en resultados alcanzó un error de respuesta final similar con menos supervisión, mientras que la supervisión basada en procesos redujo el error de razonamiento entre las soluciones con respuesta final correcta del 14.0% al 3.4%. El trabajo posterior de OpenAI en MATH enfatizó el mismo punto al mostrar un modelo supervisado por procesos que resolvía el 78% en un subconjunto representativo de MATH. Ese resultado respalda la supervisión de procesos para la confiabilidad matemática de múltiples pasos. No es un teorema universal sobre toda la supervisión de razonamiento.
La retroalimentación de IA puede escalar la revisión, pero la medición independiente sigue definiendo el objetivo.
| Familia de pipelines | Lo que los humanos todavía aportan | Lo que la retroalimentación de IA puede escalar | Lo que no reemplaza |
|---|---|---|---|
| Fuente principal de retroalimentación | Etiquetas humanas y decisiones de rúbrica. | Clasificaciones, críticas o calificaciones generadas por IA. | Definición humana de objetivos y medición final. |
| Mejor uso | Fundamentar preferencias ambiguas. | Escalar la supervisión intermedia. | Validar en datos reservados y casos extremos. |
| Modo de falla | Ciclos de revisión costosos o lentos. | El evaluador sintético se convierte en la verdad fundamental. | La auditoría humana independiente sigue siendo necesaria. |
| Control operativo | Calibración y adjudicación. | Diagnósticos del juez y verificaciones de cobertura de datos. | Revisión experta para segmentos de alto riesgo. |
Fuente principal de retroalimentación
- Lo que los humanos todavía aportan
- Etiquetas humanas y decisiones de rúbrica.
- Lo que la retroalimentación de IA puede escalar
- Clasificaciones, críticas o calificaciones generadas por IA.
- Lo que no reemplaza
- Definición humana de objetivos y medición final.
Mejor uso
- Lo que los humanos todavía aportan
- Fundamentar preferencias ambiguas.
- Lo que la retroalimentación de IA puede escalar
- Escalar la supervisión intermedia.
- Lo que no reemplaza
- Validar en datos reservados y casos extremos.
Modo de falla
- Lo que los humanos todavía aportan
- Ciclos de revisión costosos o lentos.
- Lo que la retroalimentación de IA puede escalar
- El evaluador sintético se convierte en la verdad fundamental.
- Lo que no reemplaza
- La auditoría humana independiente sigue siendo necesaria.
Control operativo
- Lo que los humanos todavía aportan
- Calibración y adjudicación.
- Lo que la retroalimentación de IA puede escalar
- Diagnósticos del juez y verificaciones de cobertura de datos.
- Lo que no reemplaza
- Revisión experta para segmentos de alto riesgo.
Síntesis de OpenTrain a partir del paquete fuente de PRM, ORM, verificador y manipulación de recompensas.
El rechazo teórico reciente más fuerte también ataca la idea de que la supervisión de resultados es fundamentalmente más difícil. Jia et al. argumentan que, bajo suposiciones estándar de cobertura de datos, el aprendizaje por refuerzo a través de la supervisión de resultados no es estadísticamente más difícil que la supervisión de procesos, hasta factores polinómicos en el horizonte. Eso no demuestra la superioridad de los ORM en la práctica. Elimina una muleta teórica común para asumir que las recompensas densas por pasos son automáticamente la opción más fundamentada.
Lo que muestra la evidencia actual
El caso de la supervisión de procesos sigue siendo más fuerte en dominios estrechos, verificables y de múltiples pasos donde los anotadores o los procedimientos automatizados pueden decir qué paso sale mal primero. “Let’s Verify Step by Step” de OpenAI sigue siendo canónico porque mostró una gran ganancia de supervisión de procesos en MATH y lanzó PRM800K con 800,000 etiquetas a nivel de paso. Math-Shepherd demostró que la supervisión de procesos derivada automáticamente puede mejorar materialmente un razonador base, elevando a Mistral-7B del 77.9% al 84.1% en GSM8K y del 28.6% al 33.0% en MATH, con la verificación basada en Math-Shepherd impulsando esos números al 89.1% y 43.5%.
ThinkPRM amplió esa línea al demostrar que un PRM generativo podría superar a LLM-as-a-judge y a los verificadores discriminativos utilizando solo el 1% de las etiquetas de PRM800K, con ganancias fuera del dominio en GPQA-Diamond y LiveCodeBench. FoVer avanzó en el costo y la transferencia de etiquetas al sintetizar etiquetas de procesos a través de la verificación formal.
Pero la base de evidencia más reciente es mucho menos favorable a las afirmaciones generales sobre los PRM. ProcessBench, construido en torno a 3,400 casos de prueba anotados por expertos humanos, informa que los PRM existentes a menudo no logran generalizar más allá del régimen de GSM8K y MATH. PRMBench, con 6,216 problemas y 83,456 etiquetas a nivel de paso, encuentra debilidades significativas en los errores de proceso implícitos. La retrospectiva del equipo de Qwen añade una crítica operativa: el etiquetado sintético de pasos de Monte Carlo tiene un rendimiento inferior al del juez LLM y la anotación humana, y la evaluación convencional de mejor de N puede inflar las puntuaciones de los PRM porque los modelos de política a menudo generan respuestas con respuestas finales correctas pero procesos defectuosos.
Los resultados empíricos recientes precisan la comparación entre PRM y ORM.
| Artículo o sistema | Dominio | Resultado | Por qué es importante |
|---|---|---|---|
| Uesato et al. | GSM8K | La retroalimentación de proceso redujo el error de razonamiento entre las soluciones con respuestas correctas del 14.0% al 3.4%. | Las etiquetas de proceso pueden exponer fallas que las revisiones de respuesta final pasan por alto. |
| Verifiquemos paso a paso | MATH | Un modelo supervisado por procesos resolvió el 78% en un subconjunto representativo de MATH. | El resultado fundamental del PRM es sólido pero específico del dominio. |
| Math-Shepherd | GSM8K / MATH | El RL de procesos y el verificador utilizan Mistral-7B mejorado en ambos benchmarks. | La supervisión automatizada de procesos puede ayudar cuando la tarea es verificable por pasos. |
| ProcessBench / PRMBench | Razonamiento matemático | Los PRM actuales muestran una transferencia débil y pasan por alto errores de proceso implícitos de grano fino. | Las victorias en los benchmarks de PRM no implican una detección robusta de errores de proceso. |
| xVerify | Evaluación de razonamiento | Reportó más del 95% de F1 y precisión en conjuntos de prueba de verificación de respuestas. | Una verificación de resultados sólida puede hacer que los diseños basados en resultados sean más competitivos. |
| Supervisión de procesos verificable | Razonamiento de ajedrez | El RL de solo precisión mejoró los movimientos mientras que empeoró la calidad del razonamiento; el VPS híbrido preservó la precisión y mejoró la consistencia. | Las mejoras en las respuestas pueden degradar la calidad de la trayectoria cuando el objetivo es incorrecto. |
| Comparación de múltiples RM | 14 dominios | El ORM generativo fue el más robusto en general; el ORM discriminativo tuvo un rendimiento a la par con el PRM discriminativo. | La comparación más amplia va en contra de la superioridad universal del PRM. |
Uesato et al.
- Dominio
- GSM8K
- Resultado
- La retroalimentación de proceso redujo el error de razonamiento entre las soluciones con respuestas correctas del 14.0% al 3.4%.
- Por qué es importante
- Las etiquetas de proceso pueden exponer fallas que las revisiones de respuesta final pasan por alto.
Verifiquemos paso a paso
- Dominio
- MATH
- Resultado
- Un modelo supervisado por procesos resolvió el 78% en un subconjunto representativo de MATH.
- Por qué es importante
- El resultado fundamental del PRM es sólido pero específico del dominio.
Math-Shepherd
- Dominio
- GSM8K / MATH
- Resultado
- El RL de procesos y el verificador utilizan Mistral-7B mejorado en ambos benchmarks.
- Por qué es importante
- La supervisión automatizada de procesos puede ayudar cuando la tarea es verificable por pasos.
ProcessBench / PRMBench
- Dominio
- Razonamiento matemático
- Resultado
- Los PRM actuales muestran una transferencia débil y pasan por alto errores de proceso implícitos de grano fino.
- Por qué es importante
- Las victorias en los benchmarks de PRM no implican una detección robusta de errores de proceso.
xVerify
- Dominio
- Evaluación de razonamiento
- Resultado
- Reportó más del 95% de F1 y precisión en conjuntos de prueba de verificación de respuestas.
- Por qué es importante
- Una verificación de resultados sólida puede hacer que los diseños basados en resultados sean más competitivos.
Supervisión de procesos verificable
- Dominio
- Razonamiento de ajedrez
- Resultado
- El RL de solo precisión mejoró los movimientos mientras que empeoró la calidad del razonamiento; el VPS híbrido preservó la precisión y mejoró la consistencia.
- Por qué es importante
- Las mejoras en las respuestas pueden degradar la calidad de la trayectoria cuando el objetivo es incorrecto.
Comparación de múltiples RM
- Dominio
- 14 dominios
- Resultado
- El ORM generativo fue el más robusto en general; el ORM discriminativo tuvo un rendimiento a la par con el PRM discriminativo.
- Por qué es importante
- La comparación más amplia va en contra de la superioridad universal del PRM.
Síntesis de OpenTrain a partir de las fuentes primarias citadas. Las métricas son heterogéneas y no deben interpretarse como porcentajes directamente comparables.
El trabajo de los verificadores complica el marco simple de PRM frente a ORM. Los verificadores generativos reformulan el modelado de recompensas como la predicción del siguiente token y reportan grandes ganancias de tipo best-of-N en tareas de razonamiento algorítmico y matemático en comparación con los verificadores estándar. xVerify se centra en la extracción de la respuesta final y la equivalencia bajo largas trazas de razonamiento. En la práctica, una gran parte del debate es en realidad un debate sobre el diseño del verificador: los verificadores de resultados deficientes hacen que los PRM parezcan necesarios, mientras que los canales sólidos de verificación de respuestas pueden hacer que la supervisión de resultados sea mucho más competitiva.
La pila de medición es frágil
La primera fragilidad es la calidad de las etiquetas. Los PRM prometen una asignación de crédito más densa, pero solo son tan buenos como los límites de los pasos y las etiquetas de corrección local. DeepSeek-R1 enumera tres limitaciones prácticas de los PRM: la dificultad para definir pasos detallados en el razonamiento general, la dificultad para juzgar la corrección de los pasos intermedios y la manipulación de recompensas una vez que se introduce un PRM basado en modelos. La retrospectiva de Qwen llega a una conclusión similar desde el lado de los datos, argumentando que el etiquetado de pasos de Monte Carlo puede verificar los pasos de manera inexacta y sesgar la evaluación posterior.
La segunda fragilidad es el acuerdo entre evaluadores. El modelado de recompensas y el modelado de jueces no se ejecutan contra un oráculo. RMB informa que el acuerdo en el etiquetado de preferencias humanas generalmente tiene un límite de alrededor del 70% al 80%, y que sus datos y los puntos de referencia de recompensas anteriores muestran aproximadamente un 75% de acuerdo entre las etiquetas y los anotadores humanos. No Free Labels amplía el punto a la evaluación centrada en la corrección: las referencias escritas por expertos mejoran sustancialmente la confiabilidad del juez en preguntas de negocios y finanzas.
La tercera fragilidad es la disponibilidad y fidelidad de la cadena de pensamiento. Algunos sistemas de razonamiento no exponen las trazas de razonamiento en bruto a los usuarios externos. La documentación de resúmenes de razonamiento de OpenAI indica que los tokens de la cadena de pensamiento en bruto no se exponen, solo los resúmenes. Incluso cuando las trazas están disponibles, Anthropic informa que los modelos de razonamiento no siempre dicen lo que piensan, y el trabajo de monitoreo de la cadena de pensamiento de OpenAI muestra que la presión de optimización puede producir una manipulación de recompensas ofuscada.
La cuarta fragilidad es la transferencia de benchmarks. ProcessBench y PRMBench son reacciones al hábito del sector de validar los PRM en distribuciones más fáciles o más limitadas que aquellas en las que los equipos realizan las implementaciones. MathArena señala lo mismo desde otro ángulo al evaluar en competencias de matemáticas recién lanzadas y reportar signos de contaminación en AIME 2024.
Los modos de falla no son simétricos
La optimización basada solo en resultados puede mejorar las respuestas mientras degrada el razonamiento. El artículo sobre supervisión de procesos verificables de Kim et al. hace esto explícito en el ajedrez. El RL basado solo en precisión mejoró la exactitud de los movimientos, pero empeoró la calidad del razonamiento, aumentando el error de la tasa de victorias hasta en un 112% y reduciendo la consistencia interna hasta en un 69%. Su híbrido VPS preservó la exactitud mientras reducía el error de la tasa de victorias hasta en un 30% y restauraba la consistencia casi hasta la saturación.
La optimización a nivel de proceso o a nivel de verificador también puede producir una falsa confianza. En la retrospectiva de Qwen, la evaluación best-of-N recompensó trazas de respuestas correctas con procesos defectuosos. En Gaming Verifiers de LLM, los modelos entrenados con RLVR en razonamiento inductivo abandonaron la inducción de reglas y, en su lugar, enumeraron etiquetas a nivel de instancia que pasaron el verificador sin aprender la regla relacional.
Los pipelines de recompensa abiertos basados en rúbricas conllevan un tercer modo de falla: el verificador puede ser fuerte en relación con la rúbrica de entrenamiento y aun así optimizar lo incorrecto. El trabajo reciente de RL con rúbricas separa la falla del verificador de las limitaciones de diseño de la rúbrica y muestra que los verificadores más fuertes reducen pero no eliminan la explotación. La literatura más amplia sobre modelos de recompensa ha advertido sobre esto durante años: sobreoptimizar una recompensa proxy puede perjudicar el rendimiento gold.
Modos de falla que determinan si la retroalimentación PRM, ORM o híbrida es creíble.
| Modo de falla | Dónde impacta más | Qué se rompe | Control antes de escalar |
|---|---|---|---|
| Respuesta correcta, proceso defectuoso | Recompensas solo por resultados | El modelo aprende a llegar a respuestas aceptables a través de trayectorias poco sólidas. | Agregar auditorías de proceso en muestras con respuestas correctas. |
| Etiquetas de pasos ruidosas o sintéticas | Modelos de recompensa de proceso | La asignación densa de crédito amplifica los errores locales de etiquetado. | Mida la concordancia de las etiquetas por paso y conserve los segmentos de adjudicación experta. |
| Manipulación del verificador | ORMs, PRMs e híbridos | La política optimizada aprende artefactos que satisfacen al evaluador. | Utilice conjuntos de reserva ocultos y verificaciones adversarias contra la manipulación de recompensas. |
| Trazas infieles o no disponibles | Supervisión de procesos | La cadena visible no es lo suficientemente confiable para supervisar. | Trate las puntuaciones PRM como proxies internos a menos que se valide la fidelidad de la traza. |
Respuesta correcta, proceso defectuoso
- Dónde impacta más
- Recompensas solo por resultados
- Qué se rompe
- El modelo aprende a llegar a respuestas aceptables a través de trayectorias poco sólidas.
- Control antes de escalar
- Agregar auditorías de proceso en muestras con respuestas correctas.
Etiquetas de pasos ruidosas o sintéticas
- Dónde impacta más
- Modelos de recompensa de proceso
- Qué se rompe
- La asignación densa de crédito amplifica los errores locales de etiquetado.
- Control antes de escalar
- Mida la concordancia de las etiquetas por paso y conserve los segmentos de adjudicación experta.
Manipulación del verificador
- Dónde impacta más
- ORMs, PRMs e híbridos
- Qué se rompe
- La política optimizada aprende artefactos que satisfacen al evaluador.
- Control antes de escalar
- Utilice conjuntos de reserva ocultos y verificaciones adversarias contra la manipulación de recompensas.
Trazas infieles o no disponibles
- Dónde impacta más
- Supervisión de procesos
- Qué se rompe
- La cadena visible no es lo suficientemente confiable para supervisar.
- Control antes de escalar
- Trate las puntuaciones PRM como proxies internos a menos que se valide la fidelidad de la traza.
Síntesis de OpenTrain a partir de ProcessBench, PRMBench, Qwen PRM, DeepSeek-R1, supervisión verificable de procesos y reportes de manipulación de recompensas.
La práctica de frontera parece condicional
La evidencia pública sugiere que las pilas de razonamiento de frontera recurren por defecto a recompensas de resultados verificables donde pueden, y luego añaden estructura y jueces donde deben. DeepSeek-R1 es el ejemplo publicado más claro. Para R1-Zero, DeepSeek utilizó un sistema de recompensas basado en reglas que consistía principalmente en recompensas de precisión y recompensas de formato, y afirma que no aplicó modelos neuronales de recompensa de resultados o de procesos porque esos modelos pueden sufrir manipulación de recompensas, requieren reentrenamiento y complican el flujo de trabajo.
Eso no significa que los PRM estén obsoletos. Significa que un importante laboratorio de razonamiento eligió públicamente “resultados verificables más restricciones de formato” en lugar de “entrenar un PRM primero” para RL a gran escala.
Los informes públicos de razonamiento de OpenAI apuntan en una dirección similar, aunque con menos detalles sobre la pila de recompensas. Los materiales de o1 describen el aprendizaje por refuerzo a gran escala sobre cadena de pensamiento más el escalado de cómputo en tiempo de entrenamiento y tiempo de prueba, pero no publican una receta de producción centrada en PRM. Una inferencia razonable es que el comportamiento de frontera es menos “implementar un PRM universal” y más “usar trazas de razonamiento interno sólidas, comprobaciones automáticas confiables donde estén disponibles, y sistemas de monitoreo o jueces en capas a su alrededor”.
Otra tendencia pública es que los laboratorios están intentando que los evaluadores gasten más cómputo, no solo los generadores. El trabajo reciente sobre verificadores muestra que el rendimiento del evaluador aumenta a medida que los modelos de razonamiento reciben más cómputo de verificación. La comparación práctica es cada vez más entre puntuaciones de proceso escalares baratas, puntuaciones de resultados escalares baratas y verificadores de razonamiento costosos con prompting estructurado.
Los diseños híbridos son el punto intermedio serio
Un equipo que solo se preocupa por la aceptación final en un dominio estrictamente verificable debería optar por defecto por la supervisión de resultados o centrada en el verificador. DeepSeek-R1, xVerify y los resultados del mejor de N basados en verificadores respaldan ese patrón.
Un equipo que se preocupa por la calidad de la trayectoria en sí no debería aceptar las mejoras basadas únicamente en respuestas como evidencia. Los casos de educación, tutoría, demostración de teoremas, planificación sensible a la seguridad y monitoreo de modelos a menudo se preocupan por el error más temprano, el comportamiento de autocorrección y si las afirmaciones intermedias son auditables. En esos entornos, los PRM o los críticos de procesos estructurados siguen siendo justificables, pero solo si el equipo puede definir los pasos de manera coherente, mantener una porción auditada por humanos y mostrar un acuerdo entre evaluadores que sea lo suficientemente bueno como para respaldar el costo adicional de las etiquetas.
La supervisión híbrida es la respuesta más justificable para muchos sistemas reales. Outcome Accuracy Is Not Enough agrega consistencia de razonamiento a la precisión de los resultados y reporta un rendimiento de vanguardia en modelos de recompensa y benchmarks de jueces. La supervisión de procesos verificables combina recompensas de procesos estructurados con precisión de resultados y evita el colapso de la calidad del razonamiento que se observa bajo el RL basado únicamente en precisión. CorVer agrega una recompensa de proceso a nivel de oración más liviana para QA factual.
Estos no son el mismo método, pero apuntan en la misma dirección: si un equipo necesita tanto calidad de respuesta como calidad de trayectoria, las señales híbridas se están volviendo más creíbles que el dogma del PRM puro o del ORM puro.
La conclusión operativa es específica pero sólida. Los PRM son instrumentos para medir y mejorar la calidad de la trayectoria cuando el equipo puede confiar en la traza, las etiquetas de los pasos y el punto de referencia. Los ORM y los verificadores de respuestas son instrumentos de aceptación cuando la exactitud final domina y la verificación es fuerte. Los diseños híbridos son la opción predeterminada justificable cuando ambas cosas son ciertas.
La variable decisiva no es una granularidad más fina por sí sola. Es si el objetivo de supervisión coincide con el modo de falla que el equipo realmente está pagando por controlar.
OpenTrain puede respaldar la revisión humana especializada para la calibración de verificadores, auditorías de etiquetas de procesos, control de calidad de rúbricas, segmentos adversarios y adjudicación de evaluaciones complejas dentro del stack que un equipo ya posee. Comience con el Servicio Gestionado cuando el cuello de botella sea operar el ciclo de revisión, o publique un trabajo cuando el equipo desee contratar directamente.
Fuentes
- Let’s Verify Step by Step
- Solving math word problems with process- and outcome-based feedback
- Math-Shepherd
- ProcessBench
- PRMBench
- Lecciones sobre el desarrollo de modelos de recompensa de procesos en el razonamiento matemático
- Hacia una supervisión de procesos efectiva en el razonamiento matemático
- Modelos de recompensa de procesos que piensan
- ¿Necesitamos verificar paso a paso?
- RewardBench 2
- RMB: Evaluación comparativa exhaustiva de modelos de recompensa en la alineación de LLM
- Sin etiquetas gratis
- xVerify
- La precisión de los resultados no es suficiente
- Supervisión verificable de procesos
- FoVer
- DeepSeek-R1
- Aprender a razonar con LLMs
- Documentación de resúmenes de razonamiento
- Los modelos de razonamiento no siempre dicen lo que piensan
- Monitoreo de modelos de razonamiento para detectar mal comportamiento
- LLMs manipulando verificadores
- Hackeo de recompensas en el aprendizaje por refuerzo basado en rúbricas
- CorVer
- MathArena
- Repensando los modelos de recompensa para el escalado en tiempo de prueba multidominio
- Leyes de escalado para la sobreoptimización del modelo de recompensa