Le Red Teaming de l'IA comme problème de données d'évaluation

Le Red Teaming de l'IA est utile lorsque les résultats contradictoires deviennent des données d'évaluation reproductibles : modèles de menaces, rubriques, arbitrage, contrôles.
Qu’est-ce que le red teaming en IA, vraiment ?
Si vous effectuez déjà des évaluations LLM, la réponse utile n’est pas « essayer de jailbreaker un modèle ». La réponse utile est une découverte contradictoire structurée qui produit des preuves. Le red teaming en IA est important lorsqu’il vous aide à concevoir de meilleures données d’évaluation, des tests de refus, des rubriques de dommages et des décisions de mise sur le marché. Il est moins important lorsqu’il devient une galerie de prompts viraux. [1]
La distinction est importante car le domaine utilise plusieurs termes apparentés de manière imprécise. Le red teaming cyber traditionnel consiste à émuler des adversaires face à la posture de sécurité d’une entreprise. Le red teaming pour l’IA est un effort structuré visant à identifier les failles et vulnérabilités des systèmes d’IA, souvent en collaboration avec les développeurs. Une évaluation est plus restreinte : fournir une entrée au système, appliquer une logique de notation et mesurer s’il a accompli la tâche souhaitée. Les tests de sécurité et les processus TEVV de pré-déploiement sont des cadres plus larges pouvant inclure le red teaming, les tests sur le terrain, les retours publics et les évaluations formelles. [1]
Comment le red teaming pour l'IA diffère du red teaming cyber et des évaluations standard.
| Pratique | Unité d'analyse | Objectif | Sortie typique | Inférence erronée à éviter |
|---|---|---|---|---|
| Équipe rouge cyber | Organisation, réseau, produit ou programme de sécurité. | Émulez des adversaires face à une posture de sécurité. | Chemin d'attaque, récit d'exploitation, liste de remédiation. | Un exercice de cybersécurité n'est pas automatiquement une évaluation d'IA. |
| Red teaming d'IA | Modèle d'IA, application, structure ou surface de déploiement. | Découvrez les failles, les vulnérabilités et les comportements nuisibles. | Résultats, prompts, transcriptions, notes de sévérité. | Un jailbreak viral ne constitue pas automatiquement une mesure fiable. |
| Évaluation de modèle | Entrée définie, configuration système, évaluateur et métrique. | Mesurez si un comportement cible se produit dans le cadre d'un harnais défini. | Scores, étiquettes, intervalles de confiance, tranches d'erreur. | Un score d'évaluation ne soutient que l'affirmation que son cadre de test peut supporter. |
| Tests de sécurité et TEVV | Cycle de vie complet des activités de preuve et d'assurance. | Combinez les tests, les preuves sur le terrain, les seuils de risque et l'examen. | Registre des risques, preuves d'acceptation, plan de surveillance. | Une session de red-teaming seule ne prouve pas qu'un système est sûr. |
Équipe rouge cyber
- Unité d'analyse
- Organisation, réseau, produit ou programme de sécurité.
- Objectif
- Émulez des adversaires face à une posture de sécurité.
- Sortie typique
- Chemin d'attaque, récit d'exploitation, liste de remédiation.
- Inférence erronée à éviter
- Un exercice de cybersécurité n'est pas automatiquement une évaluation d'IA.
Red teaming d'IA
- Unité d'analyse
- Modèle d'IA, application, structure ou surface de déploiement.
- Objectif
- Découvrez les failles, les vulnérabilités et les comportements nuisibles.
- Sortie typique
- Résultats, prompts, transcriptions, notes de sévérité.
- Inférence erronée à éviter
- Un jailbreak viral ne constitue pas automatiquement une mesure fiable.
Évaluation de modèle
- Unité d'analyse
- Entrée définie, configuration système, évaluateur et métrique.
- Objectif
- Mesurez si un comportement cible se produit dans le cadre d'un harnais défini.
- Sortie typique
- Scores, étiquettes, intervalles de confiance, tranches d'erreur.
- Inférence erronée à éviter
- Un score d'évaluation ne soutient que l'affirmation que son cadre de test peut supporter.
Tests de sécurité et TEVV
- Unité d'analyse
- Cycle de vie complet des activités de preuve et d'assurance.
- Objectif
- Combinez les tests, les preuves sur le terrain, les seuils de risque et l'examen.
- Sortie typique
- Registre des risques, preuves d'acceptation, plan de surveillance.
- Inférence erronée à éviter
- Une session de red-teaming seule ne prouve pas qu'un système est sûr.
Définitions synthétisées à partir du NIST et des conseils en matière d'évaluation de modèles.
Cela fait des jailbreaks de démonstration une unité de gouvernance faible. Le NIST avertit que les tests de jailbreak et d’ingénierie de prompt peuvent ne pas évaluer systématiquement la validité ou la fiabilité. Microsoft présente le red teaming comme un moyen d’exposer les préjudices et de comprendre une surface de risque, et non comme un remplacement de la mesure systématique. L’AISI souligne le même point du côté de l’évaluateur : les tests exploratoires peuvent signaler des préoccupations, mais des affirmations plus solides nécessitent une meilleure élicitation, une meilleure notation et une meilleure cartographie entre les résultats et les seuils de risque. [2]
L’objectif pratique est simple : transformer la découverte en cas que vous pouvez rejouer, étiqueter, auditer et acheminer.
Modèle de menace d’abord, galerie de jailbreak ensuite
Si un programme de red-teaming commence par demander aux gens de « casser le modèle », il produira généralement des exemples colorés et une mesure faible. Inversez l’ordre. Commencez par énoncer l’affirmation que les preuves doivent étayer : élicitation des capacités, robustesse des garde-fous ou comparaison entre systèmes dans un cadre partagé. Définissez ensuite le harnais, les outils et le budget qui donnent du sens à cette affirmation.
Les directives d’évaluation tierces d’OpenAI sont directes sur ce point : les scores ne sont interprétables que si le rapport décrit quelle affirmation la configuration soutient, comment le système a été sollicité et quels contrôles de validité ont été effectués. [3]
Un modèle de menace pour le red teaming d’IA doit nommer l’acteur, le comportement cible, la surface d’attaque et les dommages en aval. L’AISI soutient que les évaluations doivent s’aligner sur des modèles de risque explicites et couvrir les chemins pertinents vers les dommages. Microsoft décrit une ontologie interne qui suit les acteurs, les tactiques, les faiblesses et les impacts en aval, car les résultats bruts sont trop désordonnés pour être analysés sans une structure partagée. [4]
Pour la plupart des équipes, la « surface d’attaque » ne doit pas s’arrêter à la zone de saisie des prompts. Si le système déployé intègre la récupération de données, des outils, un contexte long, des entrées multimodales, des connecteurs ou une architecture d’agents, ces surfaces doivent être incluses dans le périmètre. Le harnais modifie ce que le système peut faire. OpenAI souligne que les structures environnantes peuvent modifier considérablement les performances, en particulier pour les systèmes agents. Microsoft recommande également de tester à la fois le modèle de base et la couche applicative, idéalement via l’interface utilisateur de production lorsque cela est possible. [3][5]
C’est là que commence le théâtre des tests limités aux seuls prompts : tester le texte de l’utilisateur sur un point de terminaison de chat simplifié, puis traiter le résultat comme une preuve concernant un produit déployé. Cela peut occulter l’injection indirecte de prompts, l’utilisation dangereuse d’outils, l’escalade multi-tours avec état, les échecs liés à la récupération de données et les comportements spécifiques à l’environnement. Le problème n’est pas que les tests basés uniquement sur les prompts soient inutiles. Le problème est de les traiter comme s’ils mesuraient l’ensemble du système.
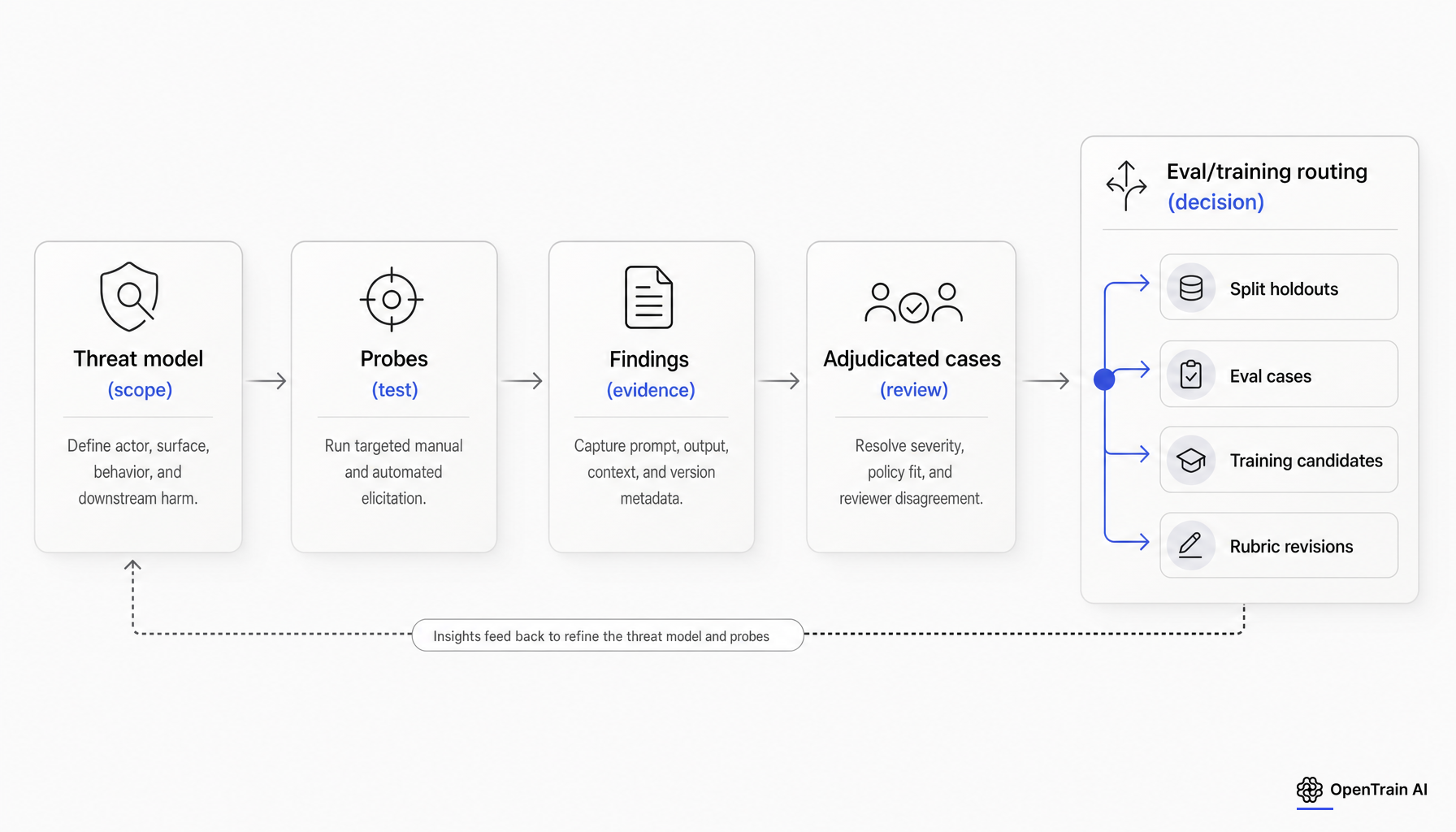
Échantillonnage, sévérité et adjudication
L’échantillonnage est l’étape où le red teaming devient une conception d’évaluation. Google recommande des entrées diverses et représentatives couvrant les politiques produit, les cas d’utilisation, les modes de défaillance, la variété lexicale et la variété sémantique. Microsoft recommande de commencer par des tests ouverts pour découvrir les préjudices, puis de passer à des cycles guidés basés sur une liste de préjudices évolutive. En pratique, un échantillon ne doit pas se limiter à une liste publique de jailbreak et à quelques prompts improvisés. Il doit s’agir d’une sélection planifiée couvrant les catégories de préjudices, les intentions des utilisateurs, les surfaces, les langues et les stratégies d’élicitation plausibles. [6]
La sévérité nécessite également une structure avant que le programme ne passe à l’échelle. Le NIST définit le risque comme une combinaison de probabilité et de conséquence. Pour l’étiquetage par red-teaming, il s’agit d’un point de départ, et non d’une grille d’évaluation définitive. La plupart des équipes ont également besoin de dimensions telles que le type de préjudice, l’actionnabilité, la reproductibilité, le réalisme et la persistance du comportement après l’application des garde-fous habituels. Cette grille est une synthèse éditoriale fondée sur le cadre de risque du NIST et les pratiques d’évaluation, et non une norme citée. [2]
L’arbitrage est l’étape où les équipes échouent souvent discrètement. Google note que les humains peuvent annoter les contenus problématiques de manières différentes et recommande des directives ou des modèles clairs pour les évaluateurs. OpenAI recommande des grilles d’évaluation claires, des exemples de niveaux de score, des seuils de réussite/échec et une agrégation par consensus lorsque plusieurs réviseurs sont utilisés. Pour les cas de haute sévérité ou aux politiques ambiguës, traitez le désaccord humain comme un signal concernant le système de mesure, et non simplement comme du bruit lié aux annotateurs. [6][7]
Une règle opérationnelle utile est la suivante : si une découverte est de haute gravité, ambiguë sur le plan des politiques ou spécialisée dans un domaine, faites-la passer d’un étiquetage à examen unique à une adjudication par des experts. Si les examinateurs ne sont pas d’accord sur le fait que le modèle a enfreint la politique, le cas devrait généralement conduire à une révision de la rubrique avant d’entraîner un post-entraînement. Cette recommandation est une synthèse, mais elle découle des conseils cités sur la clarté des rubriques, l’étalonnage et l’examen humain.
Séparez délibérément le travail humain et automatisé
L’automatisation est plus utile lorsqu’il s’agit d’élargir le champ d’action, d’actualiser les données et de détecter les signaux faibles. Les travaux d’Anthropic sur les évaluations rédigées par des modèles ont montré que ces derniers peuvent aider à générer rapidement de nombreux éléments d’évaluation pertinents, avec un fort consensus des travailleurs de la foule sur les étiquettes dans ce contexte. L’AISI soutient que les évaluations automatisées des capacités sont suffisamment évolutives pour couvrir une grande partie de la surface des capacités préoccupantes. Google recommande également de commencer par des exemples de départ et de les étendre synthétiquement lorsque les jeux de données existants sont insuffisants. [8][4][6]
Les mêmes sources définissent également les limites. L’AISI affirme que les tests automatisés ne reflètent pas l’utilisation réelle et ne devraient pas, à eux seuls, étayer des conclusions solides. Google avertit que la précision des classificateurs peut être faible pour des concepts mal définis. OpenAI déclare que les évaluations ne se résument pas à des scores et recommande de calibrer la notation automatisée par rapport au jugement humain. [4][6][7]
Les sondes automatisées excellent dans trois domaines. Premièrement, elles améliorent la couverture en générant davantage de variantes lexicales et sémantiques qu’une petite équipe humaine ne pourrait le faire. Deuxièmement, elles rendent les tests de régression peu coûteux une fois qu’un cas devient une évaluation réutilisable. Troisièmement, elles permettent aux équipes d’attaquer un système à grande échelle grâce à un échantillonnage répété, ce qui est crucial car certaines classes de jailbreak s’améliorent avec davantage de tentatives. Les travaux d’Anthropic sur le many-shot sont un exemple de la façon dont un contexte long crée de nouveaux modes de défaillance. [9]
Les outils reflètent désormais cette division du travail. Microsoft PyRIT est un framework agnostique au modèle pour sonder les systèmes multimodaux et réutiliser des blocs de construction de red-teaming composables. AISI Inspect prend en charge le dialogue multi-tours, les structures d’agents, la notation par modèle et les journaux détaillés. Ces outils sont utiles car les résultats du red-teaming doivent devenir des artefacts d’évaluation analysables, et non des notes éparses. [10][11]
L’humain reste nécessaire lorsque la question n’est pas seulement « la politique a-t-elle échoué ? » mais « qu’est-ce qui compte vraiment ici ? ». Microsoft est direct : la médecine, la cybersécurité, les risques NRBC, les préjudices interculturels et les préjudices psychosociaux nécessitent un jugement d’expert. L’AISI décrit également le red teaming par des experts comme étant plus naturaliste et ouvert que les tests automatisés. [12][4]
LLM les juges ont besoin du même scepticisme. OpenAI recommande des formats par paires ou par réussite/échec, des rubriques claires et une validation par rapport aux étiquettes humaines, car les modèles juges peuvent être biaisés par l’ordre des réponses et la longueur de celles-ci. Utilisez les juges LLM comme des instruments de mesure : calibrez-les, vérifiez les dérives et auditez-les périodiquement. Ne leur donnez pas l’autorité finale sur les préjudices spécialisés ou les limites politiques ambiguës. [7]
Où l'automatisation aide, et où l'humain reste indispensable.
| Méthode | Meilleure utilisation | Avantage principal | Angle mort principal | Examen humain nécessaire ? |
|---|---|---|---|---|
| Sondes automatisées | Tentatives répétées et étendues selon des tactiques connues. | Étend la couverture et la cadence de rafraîchissement. | Peut manquer de contexte produit réaliste et de dommages liés au domaine. | Oui, pour les cas graves ou ambigus. |
| Variantes générées par le modèle | Expansion des exemples de base à travers la formulation et la sémantique. | Trouve rapidement des voisins lexicaux et sémantiques. | Peut faire du surapprentissage sur des variations simples. | Oui, pour l'étalonnage des étiquettes et les vérifications de nouveauté. |
| Classifieurs | Présélection de grands volumes de sortie. | Triage et surveillance à faible coût. | Faible précision sur les structures lâches. | Oui, pour les décisions de politique et de gravité. |
| Juges LLM | Notation par réussite/échec ou par paires avec des rubriques claires. | Notation rapide et réutilisable une fois calibrée. | Ordre, longueur, style et biais de domaine. | Oui, avec des audits humains périodiques. |
| Suites de régression scriptées | Réexécution de cas connus après des changements de modèle ou de politique. | Relecture stable et comparaison des différences. | Mesure les modes de défaillance d'hier. | Oui, lorsque les régressions présentent un risque élevé. |
| Experts humains du domaine | Médecine, sécurité, NRBC, culturel, juridique ou préjudices psychosociaux. | Jugement du contexte et des conséquences. | Débit limité et désaccord en l'absence de rubriques. | Ils constituent le parcours de révision. |
Sondes automatisées
- Meilleure utilisation
- Tentatives répétées et étendues selon des tactiques connues.
- Avantage principal
- Étend la couverture et la cadence de rafraîchissement.
- Angle mort principal
- Peut manquer de contexte produit réaliste et de dommages liés au domaine.
- Examen humain nécessaire ?
- Oui, pour les cas graves ou ambigus.
Variantes générées par le modèle
- Meilleure utilisation
- Expansion des exemples de base à travers la formulation et la sémantique.
- Avantage principal
- Trouve rapidement des voisins lexicaux et sémantiques.
- Angle mort principal
- Peut faire du surapprentissage sur des variations simples.
- Examen humain nécessaire ?
- Oui, pour l'étalonnage des étiquettes et les vérifications de nouveauté.
Classifieurs
- Meilleure utilisation
- Présélection de grands volumes de sortie.
- Avantage principal
- Triage et surveillance à faible coût.
- Angle mort principal
- Faible précision sur les structures lâches.
- Examen humain nécessaire ?
- Oui, pour les décisions de politique et de gravité.
Juges LLM
- Meilleure utilisation
- Notation par réussite/échec ou par paires avec des rubriques claires.
- Avantage principal
- Notation rapide et réutilisable une fois calibrée.
- Angle mort principal
- Ordre, longueur, style et biais de domaine.
- Examen humain nécessaire ?
- Oui, avec des audits humains périodiques.
Suites de régression scriptées
- Meilleure utilisation
- Réexécution de cas connus après des changements de modèle ou de politique.
- Avantage principal
- Relecture stable et comparaison des différences.
- Angle mort principal
- Mesure les modes de défaillance d'hier.
- Examen humain nécessaire ?
- Oui, lorsque les régressions présentent un risque élevé.
Experts humains du domaine
- Meilleure utilisation
- Médecine, sécurité, NRBC, culturel, juridique ou préjudices psychosociaux.
- Avantage principal
- Jugement du contexte et des conséquences.
- Angle mort principal
- Débit limité et désaccord en l'absence de rubriques.
- Examen humain nécessaire ?
- Ils constituent le parcours de révision.
Basé sur le classement de l'AISI, les tests contradictoires de Google, les pratiques d'évaluation d'OpenAI, les évaluations rédigées par les modèles d'Anthropic et les leçons de red teaming de Microsoft.
Une bonne répartition opérationnelle est simple. Laissez l’automatisation générer des attaques candidates, étendre les ensembles de départ, pré-étiqueter les cas évidents, regrouper les doublons et relancer les régressions. Laissez les humains définir la liste des préjudices, examiner les cas incertains ou graves, auditer la qualité du jugement et interpréter ce que la défaillance du système signifie pour le produit ou le modèle. Cette division est une synthèse fondée sur les sources ci-dessus.
Traitez les résultats comme des objets de données, pas comme des anecdotes
Si les résultats de l’équipe de red-teaming doivent devenir des données d’évaluation réutilisables, capturez bien plus que le prompt et la réponse finale. Microsoft recommande d’enregistrer au moins la date d’apparition, l’identifiant unique, le prompt d’entrée et les détails de la sortie. Google recommande d’annoter les sorties en fonction des modes de défaillance et des préjudices. Le modèle de journal d’Inspect montre ce qu’une représentation plus mature peut préserver : entrée, métadonnées de l’échantillon, scores, erreurs, messages et traces d’événements à plusieurs niveaux de granularité. [5][6][11]
Pour les équipes appliquées, le schéma minimal utile est généralement plus vaste. En plus de l’invite et de la réponse, conservez la version du modèle, la version ou le hash de l’invite système, la configuration des outils, le contexte ou les références de récupération, la méthode d’attaque, la catégorie de politique, le statut de refus, l’étiquette de l’évaluateur, l’étiquette de sévérité, la justification, le statut d’arbitrage, le regroupement de cas et le statut de routage. Cette liste de champs exacte est une synthèse, mais il s’agit d’une extension pratique des conseils actuels sur la capture structurée, les métadonnées et la notation.
La gestion des doublons est plus importante que ce que la plupart des équipes imaginent. Google recommande d’éviter les doublons et les exemples multi-étiquettes bruyants lors de la génération de jeux de données adverses. Sans déduplication, les « principaux modes de défaillance » se résument souvent à quelques modèles d’attaque viraux, qui biaisent alors à la fois le travail d’atténuation et les données d’entraînement. Conservez une notion de cas canonique par rapport au cluster de paraphrase, et rapportez à la fois le nombre brut et le nombre unique de familles d’attaques. La recommandation canonique-versus-cluster est une synthèse, mais le besoin d’unicité et de composition minutieuse provient directement des conseils de Google. [6]
Un schéma de cas de red-teaming réutilisable pour l'évaluation et les boucles de post-entraînement.
| Domaine | Pourquoi c'est important | Sûr pour l'entraînement ? | Sûr pour la validation ? | Notes |
|---|---|---|---|---|
| ID de cas | Assure la traçabilité des révisions, des réexécutions et de la remédiation. | Oui | Oui | Les identifiants stables doivent survivre au regroupement par paraphrase. |
| Invite/entrée | Définit l'artefact d'élicitation. | Parfois | Oui | Les prompts de test exacts ne doivent pas devenir ultérieurement des exemples d'entraînement. |
| Sortie du modèle | Capture le comportement observé. | Parfois | Oui | Inclure les refus, les achèvements partiels et les sorties d'outils. |
| Version du modèle | Empêche les comparaisons erronées entre des systèmes en évolution. | Oui | Oui | Enregistrez le modèle, le point de contrôle et le canal de publication pertinent. |
| Hachage du prompt système | Associe le comportement aux instructions sans exposer de secrets. | Oui | Oui | Utilisez des hachages ou des références contrôlées lorsque les prompts sont sensibles. |
| Contexte de l'outil/récupération | Indique ce que le harnais déployé a rendu disponible. | Parfois | Oui | Essentiel pour le RAG, l'utilisation d'outils, les contextes longs et les tests d'agents. |
| Méthode d'attaque | Prend en charge la couverture et la déduplication. | Oui | Oui | Les exemples incluent le jailbreak direct, l'injection indirecte, le jeu de rôle ou l'escalade multi-tours. |
| Catégorie de politique | Relie la découverte à la rubrique. | Oui | Oui | Réviser les catégories lorsque l'arbitrage révèle une ambiguïté. |
| Statut de refus | Sépare la conformité non sécurisée du refus excessif. | Oui | Oui | Ne regroupez pas tous les refus en succès. |
| Étiquette de l'évaluateur | Définit la décision humaine ou celle de l'évaluateur calibré. | Oui | Oui | Suivre le type de réviseur et l'état de calibration. |
| Sévérité | Priorise la remédiation et les portes de mise en production. | Oui | Oui | Les dimensions de sévérité sont une synthèse, pas une norme universelle. |
| Justification | Rend les audits ultérieurs possibles. | Oui | Oui | Les justifications courtes sont préférables aux étiquettes de classe opaques. |
| Statut d'adjudication | Sépare les étiquettes de révision unique des cas résolus. | Oui | Oui | Les cas de haute gravité et les cas contestés nécessitent une escalade. |
| ID de cluster | Empêche les prompts en double de dominer les rapports. | Oui | Oui | Rapporter séparément le nombre brut et le nombre de familles d'attaques uniques. |
| Statut de routage | Empêche les fuites entre l'entraînement et la mesure. | Oui, lorsqu'il est acheminé vers l'entraînement | Oui, lorsqu'il est bloqué en tant que données de test (holdout) | Les états possibles incluent candidat à l'entraînement, cas d'évaluation, holdout bloqué, révision de rubrique ou preuve de mise en production. |
ID de cas
- Pourquoi c'est important
- Assure la traçabilité des révisions, des réexécutions et de la remédiation.
- Sûr pour l'entraînement ?
- Oui
- Sûr pour la validation ?
- Oui
- Notes
- Les identifiants stables doivent survivre au regroupement par paraphrase.
Invite/entrée
- Pourquoi c'est important
- Définit l'artefact d'élicitation.
- Sûr pour l'entraînement ?
- Parfois
- Sûr pour la validation ?
- Oui
- Notes
- Les prompts de test exacts ne doivent pas devenir ultérieurement des exemples d'entraînement.
Sortie du modèle
- Pourquoi c'est important
- Capture le comportement observé.
- Sûr pour l'entraînement ?
- Parfois
- Sûr pour la validation ?
- Oui
- Notes
- Inclure les refus, les achèvements partiels et les sorties d'outils.
Version du modèle
- Pourquoi c'est important
- Empêche les comparaisons erronées entre des systèmes en évolution.
- Sûr pour l'entraînement ?
- Oui
- Sûr pour la validation ?
- Oui
- Notes
- Enregistrez le modèle, le point de contrôle et le canal de publication pertinent.
Hachage du prompt système
- Pourquoi c'est important
- Associe le comportement aux instructions sans exposer de secrets.
- Sûr pour l'entraînement ?
- Oui
- Sûr pour la validation ?
- Oui
- Notes
- Utilisez des hachages ou des références contrôlées lorsque les prompts sont sensibles.
Contexte de l'outil/récupération
- Pourquoi c'est important
- Indique ce que le harnais déployé a rendu disponible.
- Sûr pour l'entraînement ?
- Parfois
- Sûr pour la validation ?
- Oui
- Notes
- Essentiel pour le RAG, l'utilisation d'outils, les contextes longs et les tests d'agents.
Méthode d'attaque
- Pourquoi c'est important
- Prend en charge la couverture et la déduplication.
- Sûr pour l'entraînement ?
- Oui
- Sûr pour la validation ?
- Oui
- Notes
- Les exemples incluent le jailbreak direct, l'injection indirecte, le jeu de rôle ou l'escalade multi-tours.
Catégorie de politique
- Pourquoi c'est important
- Relie la découverte à la rubrique.
- Sûr pour l'entraînement ?
- Oui
- Sûr pour la validation ?
- Oui
- Notes
- Réviser les catégories lorsque l'arbitrage révèle une ambiguïté.
Statut de refus
- Pourquoi c'est important
- Sépare la conformité non sécurisée du refus excessif.
- Sûr pour l'entraînement ?
- Oui
- Sûr pour la validation ?
- Oui
- Notes
- Ne regroupez pas tous les refus en succès.
Étiquette de l'évaluateur
- Pourquoi c'est important
- Définit la décision humaine ou celle de l'évaluateur calibré.
- Sûr pour l'entraînement ?
- Oui
- Sûr pour la validation ?
- Oui
- Notes
- Suivre le type de réviseur et l'état de calibration.
Sévérité
- Pourquoi c'est important
- Priorise la remédiation et les portes de mise en production.
- Sûr pour l'entraînement ?
- Oui
- Sûr pour la validation ?
- Oui
- Notes
- Les dimensions de sévérité sont une synthèse, pas une norme universelle.
Justification
- Pourquoi c'est important
- Rend les audits ultérieurs possibles.
- Sûr pour l'entraînement ?
- Oui
- Sûr pour la validation ?
- Oui
- Notes
- Les justifications courtes sont préférables aux étiquettes de classe opaques.
Statut d'adjudication
- Pourquoi c'est important
- Sépare les étiquettes de révision unique des cas résolus.
- Sûr pour l'entraînement ?
- Oui
- Sûr pour la validation ?
- Oui
- Notes
- Les cas de haute gravité et les cas contestés nécessitent une escalade.
ID de cluster
- Pourquoi c'est important
- Empêche les prompts en double de dominer les rapports.
- Sûr pour l'entraînement ?
- Oui
- Sûr pour la validation ?
- Oui
- Notes
- Rapporter séparément le nombre brut et le nombre de familles d'attaques uniques.
Statut de routage
- Pourquoi c'est important
- Empêche les fuites entre l'entraînement et la mesure.
- Sûr pour l'entraînement ?
- Oui, lorsqu'il est acheminé vers l'entraînement
- Sûr pour la validation ?
- Oui, lorsqu'il est bloqué en tant que données de test (holdout)
- Notes
- Les états possibles incluent candidat à l'entraînement, cas d'évaluation, holdout bloqué, révision de rubrique ou preuve de mise en production.
La liste des champs combine la documentation des outils et les conseils opérationnels ; le routage entraînement/holdout est une synthèse éditoriale.
Décidez de ce que devient chaque résultat avant de vous en servir pour l’entraînement
Il s’agit de la question opérationnelle centrale, et la réponse doit être consignée par écrit avant la première réunion post-entraînement.
Un cas de red-teaming peut devenir au moins cinq choses différentes : un exemple d’entraînement, un cas d’évaluation réutilisable, un élément de test mis de côté, une révision de politique ou de rubrique, ou une preuve pour le contrôle de mise en production. Les sources principales actuelles soutiennent la nécessité de ces voies distinctes, même si elles ne les regroupent pas dans un flux de travail standard unique. OpenAI met en garde contre la fuite de données d’évaluation dans le réglage fin par renforcement (RLHF), décrit des évaluations dérivées de la production qui sont actualisées périodiquement, et souligne les risques de validité tels que la contamination et le piratage de récompense. L’AISI plaide de même pour des seuils prédéfinis et des tests répétés tout au long du cycle de vie du modèle. [13][14][3][4]
Un cas est un candidat raisonnable à l’entraînement lorsque l’étiquette est stable, que l’échec est représentatif d’une utilisation réaliste, que la limite de la politique est claire et que l’exemple n’est pas réservé à une mesure future. Les travaux antérieurs d’Anthropic sur le red-teaming ont montré que l’utilisation de données de red-teaming dans les méthodes de sécurité réduisait la vulnérabilité au corpus d’attaques étudié. C’est pourquoi les équipes sont tentées de s’entraîner sur tout. C’est aussi pourquoi le contrôle des fuites est important : si ces mêmes cas sont utilisés plus tard comme preuve de progrès, la mesure est compromise. [15]
Gardez un cas hors de l’entraînement lorsqu’il est nécessaire en tant qu’ensemble de test, lorsqu’il ressemble à un benchmark public ou à un futur benchmark probable, lorsque l’étiquette est contestée, ou lorsque l’exploit est si spécifique à un cas que l’entraînement sur celui-ci apprendrait principalement au modèle à mémoriser un correctif. La note sur la contamination BrowseComp d’Anthropic montre comment une fuite publique peut gonfler les résultats, et l’analyse SWE-bench Verified d’OpenAI montre le même schéma d’échec à l’échelle d’un benchmark. Dans les deux cas, la leçon est la même : le même artefact ne peut pas être à la fois un matériel d’entraînement et une preuve de mesure honnête. [16][17]
Règle de routage pratique : si un cas a révélé un nouveau mode de défaillance, placez-le d’abord dans un compartiment de réserve (holdout). Ce n’est qu’après avoir actualisé la réserve et prouvé la correction sur de nouveaux cas que vous devriez envisager d’intégrer des variantes de ce modèle de défaillance à l’entraînement. Cette règle est une synthèse, mais elle respecte les directives actuelles sur les fuites provenant des sources des fournisseurs et des évaluateurs.
Un modèle opérationnel pour petites équipes qui ne prétend pas garantir la sécurité
Pour une petite équipe d’IA, l’objectif n’est pas de « tout couvrir ». L’objectif est de créer une boucle qui produit des preuves auxquelles vous pourrez toujours vous fier après les changements apportés au modèle.
Commencez par un modèle de menace concret et pertinent pour le déploiement, une surface de produit étroite et un cycle de découverte manuelle. Utilisez des testeurs diversifiés si possible, mais incluez au minimum une personne qui comprend les risques liés au domaine et une personne capable de réfléchir de manière contradictoire à l’interface du système. Microsoft recommande des testeurs diversifiés et des affectations explicites aux risques ou aux fonctionnalités ; Google recommande de partir d’exemples de base et de les développer avec précaution ; OpenAI recommande de créer des évaluations tôt, de tout consigner et de calibrer l’automatisation avec des étiquettes humaines. [5][6][7]
Ensuite, gelez la première tranche de résultats à haute confiance dans un ensemble d’évaluation contradictoire mis de côté. Ne procédez pas à un fine-tuning sur ces cas précis. Construisez des exécutions de régression simples autour d’eux, même si le système de notation est binaire avec un audit humain. Une fois que cela fonctionne, ajoutez une seconde voie pour les candidats à l’entraînement et maintenez une séparation nette. Les conseils d’évaluation d’OpenAI insistent à plusieurs reprises sur les données mises de côté, l’absence de chevauchement et des ensembles d’entraînement distincts pour les boucles de post-entraînement. [13][7]
Après cela, l’automatisation vaut l’effort. Utilisez des expansions générées par modèle, des classificateurs ou des juges LLM pour élargir la couverture et réduire les coûts de revue, mais uniquement dans les domaines où vous avez établi ce qu’une étiquette correcte signifie. L’approche par paliers de l’AISI est un modèle utile : laissez des tests automatisés plus légers identifier rapidement les préoccupations, puis passez à une élicitation sur mesure et à une revue experte lorsque le signal est important. [4]
Rien de tout cela ne prouve qu’un système est sûr. C’est une mauvaise promesse. Une bonne boucle de red-teaming vous fournit des cas que vous pouvez rejouer, des étiquettes que vous pouvez défendre, des données de test sur lesquelles vous n’avez pas entraîné le modèle, et suffisamment de structure pour déterminer si une mesure d’atténuation a réellement modifié le modèle ou a simplement corrigé une invite de démonstration.
OpenTrain peut aider les équipes à recruter des red-teamers, des réviseurs spécialisés et des experts en évaluation pour ce travail. Utilisez la référence de fiabilité du juge LLM pour le calibrage des évaluateurs, le guide RLAIF vs RLHF pour les limites de l’automatisation, la référence PRM vs ORM pour la conception des objectifs de mesure, et le guide de cadrage RLHF pour la planification des boucles de révision. Lorsque le goulot d’étranglement est le personnel de la boucle de révision, publiez une offre d’emploi.
Sources
- Glossaire NIST : red team ; Glossaire NIST : red-teaming en intelligence artificielle ; Profil NIST AI RMF pour l’IA générative
- Profil NIST AI RMF pour l’IA générative
- OpenAI : Fondations pour des évaluations tierces fiables
- AISI : Premières leçons tirées de l’évaluation des systèmes d’IA de pointe
- Microsoft Learn : Planification du red teaming pour les LLM
- Google : Tests contradictoires pour l’IA générative
- OpenAI : Bonnes pratiques d’évaluation
- Anthropic : Découvrir les comportements des LLM avec des évaluations rédigées par des modèles
- Anthropic : Jailbreak à plusieurs tentatives
- PyRIT : un framework pour l’identification des risques de sécurité et le red teaming dans les systèmes d’IA générative
- Documentation d’Inspect AI
- Microsoft Research : Leçons tirées du red teaming de 100 produits d’IA générative ; Résumé du blog de sécurité Microsoft
- OpenAI cookbook : Conception de systèmes basée sur l’évaluation
- OpenAI : Évaluations en production
- Anthropic : Red Teaming de modèles de langage pour réduire les risques
- Anthropic : Évaluation de la sensibilisation et BrowseComp
- OpenAI : Pourquoi nous n’évaluons plus sur SWE-bench Verified