PRM vs ORM pour les systèmes de raisonnement

Une référence technique sur les modèles de récompense de processus par rapport aux modèles de récompense de résultat, la fiabilité des vérificateurs, le transfert de benchmarks.
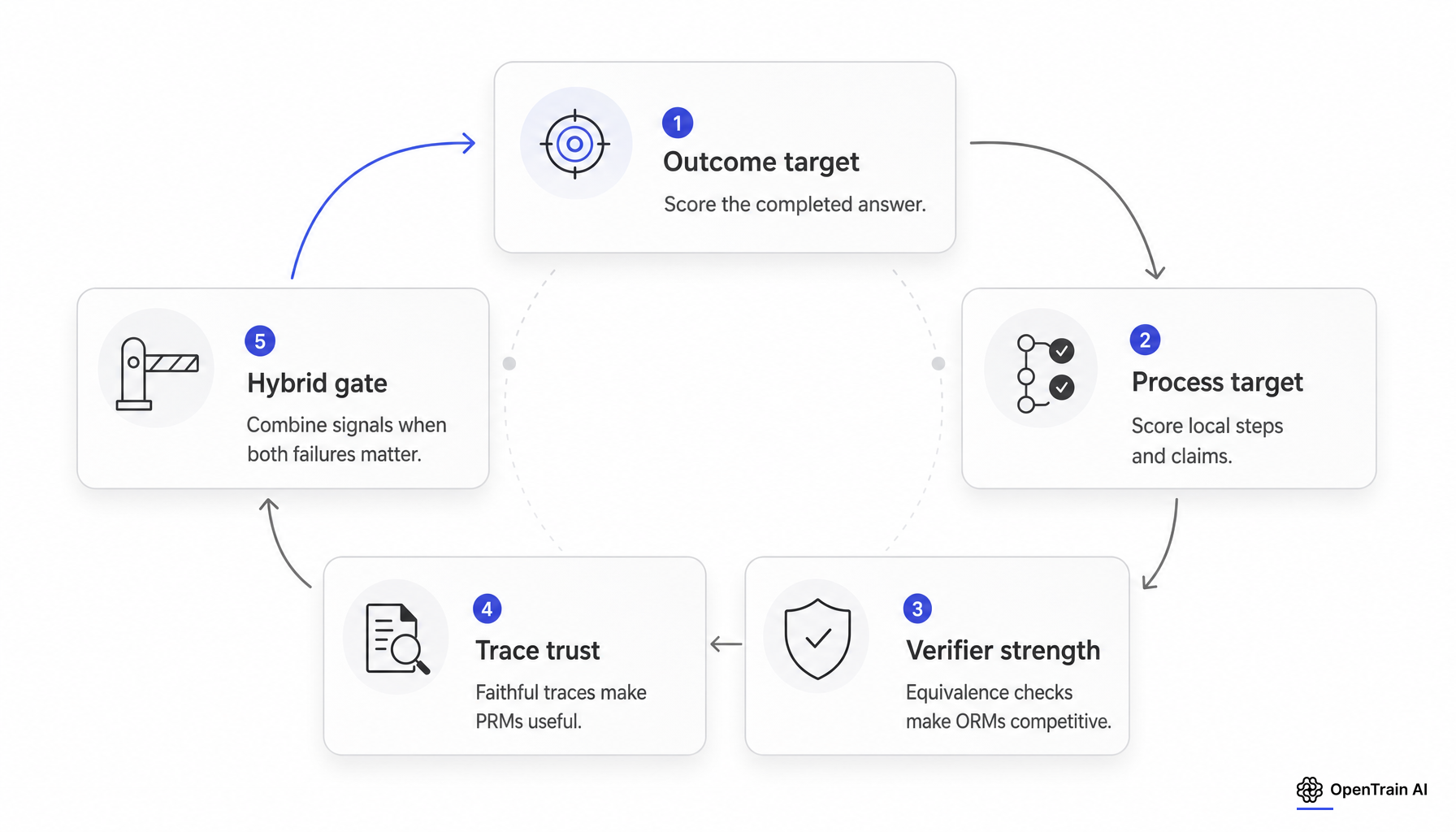
La question technique actuelle n’est pas de savoir si les modèles de récompense de processus surpassent les modèles de récompense de résultat dans l’absolu. Il s’agit de savoir si le pipeline d’entraînement ou d’évaluation cherche à mesurer l’exactitude de la réponse, l’exactitude de la trajectoire, l’utilité de la recherche, ou un hybride des trois.
Des travaux récents rendent difficile à défendre l’idée simpliste selon laquelle « les PRM sont meilleurs parce qu’ils sont plus denses ». Les articles fondateurs sur la supervision de processus montrent toujours des gains réels sur des tâches de type mathématique et un diagnostic plus clair des erreurs intermédiaires. De nouvelles comparaisons multi-domaines, des articles sur les vérificateurs et des rapports sur le détournement de récompense montrent que les configurations basées sur les résultats ou les vérificateurs peuvent égaler ou surpasser les PRM lorsque les étiquettes d’étape sont bruitées, que les traces sont indisponibles ou infidèles, et que le benchmark récompense davantage l’exactitude finale qu’un raisonnement solide.
Le choix justifiable dépend de l’objectif, et non de l’idéologie.
La comparaison est une inadéquation d’objectifs
Au niveau de la cible de supervision, les PRM et les ORM résolvent des problèmes d’estimation différents. On demande généralement à un ORM ou à un vérificateur de réponse rattaché à la trajectoire complète si la réponse finale ou la réponse terminée doit être acceptée. On demande à un PRM d’évaluer des préfixes, des étapes ou des affirmations intermédiaires afin que l’entraînement ou la recherche puisse attribuer le crédit avant que la réponse finale ne soit connue.
Cette différence est importante car une même trajectoire peut avoir un résultat correct mais un processus défaillant, ou un processus globalement solide mais un résultat incorrect en raison d’une erreur arithmétique tardive. Uesato et al. ont rendu cette distinction explicite sur GSM8K : la supervision purement basée sur les résultats a atteint une erreur de réponse finale similaire avec moins de supervision, tandis que la supervision basée sur les processus a réduit l’erreur de raisonnement parmi les solutions à réponse finale correcte de 14.0% à 3.4%. Les travaux ultérieurs d’OpenAI sur MATH ont souligné ce même point en montrant qu’un modèle supervisé par processus résolvait 78% d’un sous-ensemble représentatif de MATH. Ce résultat soutient la supervision de processus pour la fiabilité des mathématiques à plusieurs étapes. Ce n’est pas un théorème universel sur toute la supervision du raisonnement.
Les retours de l'IA peuvent mettre à l'échelle la révision, mais une mesure indépendante définit toujours l'objectif.
| Famille de pipelines | Ce que les humains fournissent encore | Ce que les retours de l'IA peuvent mettre à l'échelle | Ce que cela ne remplace pas |
|---|---|---|---|
| Source principale de retours | Étiquettes humaines et décisions basées sur des grilles d'évaluation. | Classements, critiques ou notes générés par l'IA. | Définition humaine de l'objectif et mesure finale. |
| Meilleure utilisation | Ancrage des préférences ambiguës. | Mise à l'échelle de la supervision intermédiaire. | Valider sur des données de test et des cas limites. |
| Mode de défaillance | Boucles de révision coûteuses ou lentes. | L'évaluateur synthétique devient la vérité terrain. | Un audit humain indépendant reste nécessaire. |
| Contrôle opérationnel | Calibration et arbitrage. | Diagnostics des juges et vérifications de la couverture des données. | Examen par des experts pour les segments à forts enjeux. |
Source principale de retours
- Ce que les humains fournissent encore
- Étiquettes humaines et décisions basées sur des grilles d'évaluation.
- Ce que les retours de l'IA peuvent mettre à l'échelle
- Classements, critiques ou notes générés par l'IA.
- Ce que cela ne remplace pas
- Définition humaine de l'objectif et mesure finale.
Meilleure utilisation
- Ce que les humains fournissent encore
- Ancrage des préférences ambiguës.
- Ce que les retours de l'IA peuvent mettre à l'échelle
- Mise à l'échelle de la supervision intermédiaire.
- Ce que cela ne remplace pas
- Valider sur des données de test et des cas limites.
Mode de défaillance
- Ce que les humains fournissent encore
- Boucles de révision coûteuses ou lentes.
- Ce que les retours de l'IA peuvent mettre à l'échelle
- L'évaluateur synthétique devient la vérité terrain.
- Ce que cela ne remplace pas
- Un audit humain indépendant reste nécessaire.
Contrôle opérationnel
- Ce que les humains fournissent encore
- Calibration et arbitrage.
- Ce que les retours de l'IA peuvent mettre à l'échelle
- Diagnostics des juges et vérifications de la couverture des données.
- Ce que cela ne remplace pas
- Examen par des experts pour les segments à forts enjeux.
Synthèse OpenTrain à partir du PRM, de l'ORM, du vérificateur et du package source de piratage de récompense.
La plus forte opposition théorique récente s’attaque également à l’idée que la supervision des résultats est fondamentalement plus difficile. Jia et al. soutiennent que, sous des hypothèses standard de couverture des données, l’apprentissage par renforcement via la supervision des résultats n’est pas statistiquement plus difficile que la supervision des processus, à des facteurs polynomiaux près dans l’horizon. Cela ne prouve pas la supériorité des ORM en pratique. Cela supprime un argument théorique courant consistant à supposer que les récompenses denses par étape sont automatiquement le choix le plus fondé.
Ce que montrent les preuves actuelles
L’argument en faveur de la supervision des processus reste le plus fort dans des domaines restreints, vérifiables et à plusieurs étapes, où les annotateurs ou les procédures automatisées peuvent indiquer quelle étape échoue en premier. L’article “Let’s Verify Step by Step” d’OpenAI reste canonique car il a montré un gain important de la supervision des processus sur MATH et a publié PRM800K avec 800,000 étiquettes au niveau de l’étape. Math-Shepherd a montré que la supervision des processus dérivée automatiquement peut améliorer matériellement un raisonneur de base, faisant passer Mistral-7B de 77.9% à 84.1% sur GSM8K et de 28.6% à 33.0% sur MATH, la vérification basée sur Math-Shepherd poussant ces chiffres à 89.1% et 43.5%.
ThinkPRM a prolongé cette lignée en montrant qu’un PRM génératif pouvait surpasser LLM-as-a-judge et les vérificateurs discriminatifs en utilisant seulement 1% des étiquettes de PRM800K, avec des gains hors domaine sur GPQA-Diamond et LiveCodeBench. FoVer a fait avancer la question du coût des étiquettes et du transfert en synthétisant des étiquettes de processus par vérification formelle.
Mais la base de preuves plus récente est beaucoup moins favorable aux affirmations générales sur les PRM. ProcessBench, construit autour de 3,400 cas de test annotés par des experts humains, rapporte que les PRM existants échouent souvent à se généraliser au-delà du régime de GSM8K et MATH. PRMBench, avec 6,216 problèmes et 83,456 étiquettes au niveau de l’étape, révèle des faiblesses significatives sur les erreurs de processus implicites. La rétrospective de l’équipe Qwen ajoute une critique opérationnelle : l’étiquetage synthétique des étapes par Monte-Carlo est moins performant que LLM-judge et l’annotation humaine, et l’évaluation conventionnelle best-of-N peut gonfler les scores des PRM car les modèles de politique génèrent souvent des réponses avec des réponses finales correctes mais des processus défectueux.
Les résultats empiriques récents affinent la comparaison entre PRM et ORM.
| Article ou système | Domaine | Résultat | Pourquoi c'est important |
|---|---|---|---|
| Uesato et al. | GSM8K | Le feedback sur le processus a réduit les erreurs de raisonnement parmi les solutions avec une réponse correcte de 14.0% à 3.4%. | Les étiquettes de processus peuvent révéler des erreurs qui échappent aux vérifications de la réponse finale. |
| Let's Verify Step by Step | MATH | Un modèle supervisé par processus a résolu 78% sur un sous-ensemble représentatif de MATH. | Le résultat fondamental du PRM est solide mais spécifique au domaine. |
| Math-Shepherd | GSM8K / MATH | Le RL de processus et le vérificateur utilisent un Mistral-7B amélioré sur les deux benchmarks. | La supervision automatisée des processus peut aider lorsque la tâche est vérifiable par étapes. |
| ProcessBench / PRMBench | Raisonnement mathématique | Les PRM actuels montrent un faible transfert et passent à côté des erreurs de processus implicites à grain fin. | Les succès aux benchmarks PRM n'impliquent pas une détection robuste des erreurs de processus. |
| xVerify | Évaluation du raisonnement | A rapporté plus de 95% de score F1 et de précision sur les ensembles de test de vérification des réponses. | Une vérification solide des résultats peut rendre les conceptions axées sur les résultats plus compétitives. |
| Supervision de processus vérifiable | Raisonnement aux échecs | Le RL basé uniquement sur la précision a amélioré les coups tout en détériorant la qualité du raisonnement ; le VPS hybride a préservé la précision et amélioré la cohérence. | Les gains sur les réponses peuvent dégrader la qualité de la trajectoire lorsque la cible est erronée. |
| Comparaison multi-RM | 14 domaines | L'ORM génératif s'est révélé le plus robuste dans l'ensemble ; l'ORM discriminant a obtenu des performances comparables au PRM discriminant. | La comparaison la plus large va à l'encontre de la supériorité universelle des PRM. |
Uesato et al.
- Domaine
- GSM8K
- Résultat
- Le feedback sur le processus a réduit les erreurs de raisonnement parmi les solutions avec une réponse correcte de 14.0% à 3.4%.
- Pourquoi c'est important
- Les étiquettes de processus peuvent révéler des erreurs qui échappent aux vérifications de la réponse finale.
Let's Verify Step by Step
- Domaine
- MATH
- Résultat
- Un modèle supervisé par processus a résolu 78% sur un sous-ensemble représentatif de MATH.
- Pourquoi c'est important
- Le résultat fondamental du PRM est solide mais spécifique au domaine.
Math-Shepherd
- Domaine
- GSM8K / MATH
- Résultat
- Le RL de processus et le vérificateur utilisent un Mistral-7B amélioré sur les deux benchmarks.
- Pourquoi c'est important
- La supervision automatisée des processus peut aider lorsque la tâche est vérifiable par étapes.
ProcessBench / PRMBench
- Domaine
- Raisonnement mathématique
- Résultat
- Les PRM actuels montrent un faible transfert et passent à côté des erreurs de processus implicites à grain fin.
- Pourquoi c'est important
- Les succès aux benchmarks PRM n'impliquent pas une détection robuste des erreurs de processus.
xVerify
- Domaine
- Évaluation du raisonnement
- Résultat
- A rapporté plus de 95% de score F1 et de précision sur les ensembles de test de vérification des réponses.
- Pourquoi c'est important
- Une vérification solide des résultats peut rendre les conceptions axées sur les résultats plus compétitives.
Supervision de processus vérifiable
- Domaine
- Raisonnement aux échecs
- Résultat
- Le RL basé uniquement sur la précision a amélioré les coups tout en détériorant la qualité du raisonnement ; le VPS hybride a préservé la précision et amélioré la cohérence.
- Pourquoi c'est important
- Les gains sur les réponses peuvent dégrader la qualité de la trajectoire lorsque la cible est erronée.
Comparaison multi-RM
- Domaine
- 14 domaines
- Résultat
- L'ORM génératif s'est révélé le plus robuste dans l'ensemble ; l'ORM discriminant a obtenu des performances comparables au PRM discriminant.
- Pourquoi c'est important
- La comparaison la plus large va à l'encontre de la supériorité universelle des PRM.
Synthèse OpenTrain à partir des sources primaires citées. Les métriques sont hétérogènes et ne doivent pas être considérées comme des pourcentages directement comparables.
Le travail sur les vérificateurs complique la simple opposition entre PRM et ORM. Les vérificateurs génératifs redéfinissent la modélisation des récompenses comme la prédiction du token suivant et font état de gains best-of-N importants sur les tâches de raisonnement algorithmique et mathématique par rapport aux vérificateurs standards. xVerify se concentre sur l’extraction de la réponse finale et l’équivalence dans les longues traces de raisonnement. En pratique, une grande partie du débat porte en réalité sur la conception des vérificateurs : de mauvais vérificateurs de résultats font paraître les PRM nécessaires, tandis que de solides pipelines de vérification des réponses peuvent rendre la supervision des résultats beaucoup plus compétitive.
La pile de mesure est fragile
La première fragilité concerne la qualité des étiquettes. Les PRM promettent une attribution de crédit plus dense, mais leur efficacité dépend entièrement des délimitations des étapes et des étiquettes d’exactitude locale. DeepSeek-R1 énumère trois limites pratiques des PRM : la difficulté à définir des étapes précises dans le raisonnement général, la difficulté à évaluer l’exactitude des étapes intermédiaires, et le détournement des récompenses (reward hacking) une fois qu’un PRM basé sur un modèle est introduit. La rétrospective de Qwen parvient à une conclusion similaire du point de vue des données, en affirmant que l’étiquetage des étapes par la méthode de Monte-Carlo peut vérifier les étapes de manière inexacte et biaiser l’évaluation en aval.
La deuxième fragilité est l’accord des évaluateurs. La modélisation des récompenses et la modélisation des juges ne s’exécutent pas par rapport à un oracle. RMB rapporte que l’accord sur l’étiquetage des préférences humaines est généralement plafonné entre 70% et 80%, et que ses données et les références de récompense antérieures montrent un accord d’environ 75% entre les étiquettes et les annotateurs humains. No Free Labels étend ce point au jugement axé sur l’exactitude : les références rédigées par des experts améliorent considérablement la fiabilité des juges sur les questions commerciales et financières.
La troisième fragilité est la disponibilité et la fidélité de la chaîne de pensée. Certaines piles de raisonnement n’exposent pas les traces de raisonnement brutes aux utilisateurs externes. La documentation d’OpenAI sur les résumés de raisonnement indique que les jetons bruts de la chaîne de pensée ne sont pas exposés, seuls les résumés le sont. Même lorsque les traces sont disponibles, Anthropic rapporte que les modèles de raisonnement ne disent pas toujours ce qu’ils pensent, et les travaux de surveillance de la chaîne de pensée d’OpenAI montrent que la pression d’optimisation peut produire un piratage de récompense obscurci.
La quatrième fragilité est le transfert de benchmark. ProcessBench et PRMBench sont tous deux des réactions à l’habitude du domaine de valider les PRM sur des distributions plus faciles ou plus étroites que celles sur lesquelles les équipes les déploient. MathArena soulève le même point sous un autre angle en évaluant sur des concours de mathématiques récemment publiés et en signalant des signes de contamination dans l’AIME 2024.
Les modes de défaillance ne sont pas symétriques
L’optimisation basée uniquement sur les résultats peut améliorer les réponses tout en dégradant le raisonnement. L’article de Kim et al. sur la supervision de processus vérifiable rend cela explicite sur les échecs. L’apprentissage par renforcement (RL) axé uniquement sur la précision a amélioré la précision des mouvements, mais a détérioré la qualité du raisonnement, augmentant l’erreur de taux de victoire jusqu’à 112% et réduisant la cohérence interne jusqu’à 69%. Leur hybride VPS a préservé la précision tout en réduisant l’erreur de taux de victoire jusqu’à 30% et en restaurant la cohérence à un niveau proche de la saturation.
L’optimisation au niveau du processus ou du vérificateur peut également produire une fausse confiance. Dans la rétrospective Qwen, l’évaluation best-of-N a récompensé les traces avec une réponse correcte mais un processus défectueux. Dans Gaming Verifiers de LLM, les modèles entraînés par RLVR sur le raisonnement inductif ont abandonné l’induction de règles et ont plutôt énuméré des étiquettes au niveau de l’instance qui ont passé le vérificateur sans apprendre la règle relationnelle.
Les pipelines de récompense ouverts basés sur des grilles d’évaluation comportent un troisième mode de défaillance : le vérificateur peut être fort par rapport à la grille d’entraînement et tout de même optimiser la mauvaise chose. Des travaux récents sur le RL basé sur des grilles séparent la défaillance du vérificateur des limites de conception de la grille et montrent que des vérificateurs plus forts réduisent mais n’éliminent pas l’exploitation. La littérature plus large sur les modèles de récompense met en garde à ce sujet depuis des années : sur-optimiser une récompense par procuration peut nuire aux performances de référence.
Les modes de défaillance qui décident si les retours PRM, ORM ou hybrides sont crédibles.
| Mode de défaillance | Où l'impact est le plus fort | Ce qui casse | Contrôle avant la mise à l'échelle |
|---|---|---|---|
| Réponse correcte, processus imparfait | Récompenses basées uniquement sur le résultat | Le modèle apprend à atteindre des réponses acceptables via des trajectoires erronées. | Ajouter des audits de processus sur les échantillons à réponse correcte. |
| Étiquettes d'étape bruitées ou synthétiques | Modèles de récompense de processus | L'attribution dense de crédit amplifie les erreurs d'étiquetage locales. | Mesurez l'accord étape-étiquette et conservez des tranches d'arbitrage expert. |
| Manipulation du vérificateur | ORM, PRM et hybrides | La politique optimisée apprend des artefacts qui satisfont l'évaluateur. | Utilisez des données de réserve cachées et des contrôles adverses de manipulation des récompenses. |
| Traces infidèles ou indisponibles | Supervision de processus | La chaîne visible n'est pas assez fiable pour être supervisée. | Considérez les scores PRM comme des proxys internes à moins que la fidélité de la trace ne soit validée. |
Réponse correcte, processus imparfait
- Où l'impact est le plus fort
- Récompenses basées uniquement sur le résultat
- Ce qui casse
- Le modèle apprend à atteindre des réponses acceptables via des trajectoires erronées.
- Contrôle avant la mise à l'échelle
- Ajouter des audits de processus sur les échantillons à réponse correcte.
Étiquettes d'étape bruitées ou synthétiques
- Où l'impact est le plus fort
- Modèles de récompense de processus
- Ce qui casse
- L'attribution dense de crédit amplifie les erreurs d'étiquetage locales.
- Contrôle avant la mise à l'échelle
- Mesurez l'accord étape-étiquette et conservez des tranches d'arbitrage expert.
Manipulation du vérificateur
- Où l'impact est le plus fort
- ORM, PRM et hybrides
- Ce qui casse
- La politique optimisée apprend des artefacts qui satisfont l'évaluateur.
- Contrôle avant la mise à l'échelle
- Utilisez des données de réserve cachées et des contrôles adverses de manipulation des récompenses.
Traces infidèles ou indisponibles
- Où l'impact est le plus fort
- Supervision de processus
- Ce qui casse
- La chaîne visible n'est pas assez fiable pour être supervisée.
- Contrôle avant la mise à l'échelle
- Considérez les scores PRM comme des proxys internes à moins que la fidélité de la trace ne soit validée.
Synthèse OpenTrain à partir de ProcessBench, PRMBench, Qwen PRM, DeepSeek-R1, de la supervision de processus vérifiable et des rapports sur le piratage de récompense.
Les pratiques de pointe semblent conditionnelles
Les preuves publiques suggèrent que les piles de raisonnement de pointe utilisent par défaut des récompenses de résultat vérifiables là où elles le peuvent, puis ajoutent de la structure et des juges là où elles le doivent. DeepSeek-R1 en est l’exemple publié le plus clair. Pour R1-Zero, DeepSeek a utilisé un système de récompense basé sur des règles, composé principalement de récompenses d’exactitude et de récompenses de format, et affirme ne pas avoir appliqué de modèles de récompense de résultat ou de processus neuronaux car ces modèles peuvent subir un piratage de récompense (reward hacking), nécessiter un réentraînement et compliquer le pipeline.
Cela ne signifie pas que les PRM sont obsolètes. Cela signifie qu’un laboratoire de raisonnement majeur a publiquement choisi « résultat vérifiable plus contraintes de formatage » plutôt que « entraîner un PRM d’abord » pour le RL à grande échelle.
Les rapports publics d’OpenAI sur le raisonnement vont dans le même sens, bien qu’avec moins de détails sur la pile de récompenses. Les documents sur o1 décrivent un apprentissage par renforcement à grande échelle sur la chaîne de pensée (chain-of-thought) ainsi qu’une mise à l’échelle du calcul lors de l’entraînement et du test, mais ne publient pas de recette de production centrée sur les PRM. Une déduction raisonnable est que le comportement de pointe consiste moins à « déployer un PRM universel » qu’à « utiliser des traces de raisonnement interne solides, des vérifications automatiques fiables là où elles sont disponibles, et des systèmes de surveillance ou de juges en couches autour d’elles ».
Une autre tendance publique est que les laboratoires essaient de faire en sorte que les évaluateurs dépensent plus de calcul, et pas seulement les générateurs. Des travaux récents sur les vérificateurs montrent que les performances des évaluateurs augmentent à mesure que les modèles de raisonnement reçoivent plus de calcul de vérification. La comparaison pratique se fait de plus en plus entre des scores de processus scalaires bon marché, des scores de résultat scalaires bon marché et des vérificateurs de raisonnement coûteux avec un prompting structuré.
Les modèles hybrides sont le véritable juste milieu
Une équipe qui ne se soucie que de l’acceptation finale dans un domaine strictement vérifiable devrait s’orienter par défaut vers une supervision axée sur les résultats ou les vérificateurs. DeepSeek-R1, xVerify et les résultats best-of-N basés sur des vérificateurs soutiennent tous ce modèle.
Une équipe qui se soucie de la qualité de la trajectoire elle-même ne devrait pas accepter les gains basés uniquement sur les réponses comme preuve. L’éducation, le tutorat, la démonstration de théorèmes, la planification sensible à la sécurité et les cas de surveillance de modèles se soucient souvent de la première erreur, du comportement d’auto-correction et de la possibilité d’auditer les affirmations intermédiaires. Dans ces contextes, les PRM ou les critiques de processus structurés restent défendables, mais seulement si l’équipe peut définir les étapes de manière cohérente, maintenir une partie auditée par des humains et montrer un accord des évaluateurs suffisant pour justifier le coût supplémentaire d’étiquetage.
La supervision hybride est la réponse la plus justifiable pour de nombreux systèmes réels. « Outcome Accuracy Is Not Enough » ajoute la cohérence du raisonnement à la précision du résultat et fait état de performances de pointe pour les modèles de récompense et les benchmarks d’évaluation. La supervision de processus vérifiable combine des récompenses de processus structurées avec la précision du résultat et évite l’effondrement de la qualité du raisonnement observé avec le RLHF basé uniquement sur la précision. CorVer ajoute une récompense de processus plus légère au niveau de la phrase pour les questions-réponses factuelles.
Ce ne sont pas les mêmes méthodes, mais elles pointent dans la même direction : si une équipe a besoin à la fois de la qualité de la réponse et de la qualité de la trajectoire, les signaux hybrides deviennent plus crédibles que le dogme du PRM pur ou de l’ORM pur.
La conclusion opérationnelle est étroite mais solide. Les PRM sont des instruments permettant de mesurer et d’améliorer la qualité de la trajectoire lorsque l’équipe peut se fier à la trace, aux étiquettes d’étape et au benchmark. Les ORM et les vérificateurs de réponses sont des instruments d’acceptation lorsque l’exactitude finale prédomine et que la vérification est forte. Les conceptions hybrides constituent le choix par défaut justifiable lorsque les deux sont vrais.
La variable décisive n’est pas une granularité plus fine en soi. Il s’agit de savoir si la cible de supervision correspond au mode de défaillance que l’équipe paie réellement pour contrôler.
OpenTrain peut prendre en charge l’examen humain spécialisé pour l’étalonnage des vérificateurs, les audits d’étiquettes de processus, l’assurance qualité des grilles d’évaluation, les segments adversaires et l’arbitrage des évaluations complexes au sein de la stack qu’une équipe possède déjà. Commencez par le service géré lorsque le goulot d’étranglement est l’exploitation de la boucle d’examen, ou publiez une offre d’emploi lorsque l’équipe souhaite recruter directement.
Sources
- Let’s Verify Step by Step
- Résolution de problèmes mathématiques avec des retours basés sur le processus et le résultat
- Math-Shepherd
- ProcessBench
- PRMBench
- Les leçons du développement de modèles de récompense de processus dans le raisonnement mathématique
- Vers une supervision de processus efficace dans le raisonnement mathématique
- Des modèles de récompense de processus qui pensent
- Devons-nous vérifier étape par étape ?
- RewardBench 2
- RMB : Évaluation exhaustive des modèles de récompense dans l’alignement LLM
- No Free Labels
- xVerify
- La précision des résultats ne suffit pas
- Supervision de processus vérifiable
- FoVer
- DeepSeek-R1
- Apprendre à raisonner avec les LLMs
- Documentation des résumés de raisonnement
- Les modèles de raisonnement ne disent pas toujours ce qu’ils pensent
- Surveillance des modèles de raisonnement pour détecter les comportements indésirables
- Contournement des vérificateurs par les LLMs
- Détournement des récompenses dans l’apprentissage par renforcement basé sur des grilles d’évaluation
- CorVer
- MathArena
- Repenser les modèles de récompense pour la mise à l’échelle au moment du test multi-domaines
- Lois de mise à l’échelle pour la sur-optimisation des modèles de récompense