Direct Preference Optimization vs. PPO nach RLHF

Eine technische Referenz darüber, was DPO nach RLHF ändert, wo PPO und Online-Daten weiterhin von Bedeutung sind und warum die Präferenzmessung der schwierige Teil bleibt.
Direct Preference Optimization hat RLHF nicht vollständig ersetzt. Es ersetzte einen großen Teil dessen, was viele Teams mit RLHF in Verbindung brachten: das Training eines expliziten Reward-Modells und die anschließende Ausführung von PPO dagegen. Die stärkere Lesart ist enger und nützlicher. DPO vereinfacht die Optimierung weitaus mehr als die Messung.
Wenn Offline-Präferenzdaten eine schwache Abdeckung aufweisen, wenn Juroren voreingenommen sind, wenn Reward-Modelle falsch generalisieren oder wenn Labels verrauscht sind, ist die fehlende PPO-Schleife nicht das Kernproblem. Das Kernproblem ist, ob sich das gemessene Präferenzziel auf das Verhalten überträgt, das dem Team tatsächlich wichtig ist (DPO, InstructGPT, helpful-harmless RLHF).
Das Ziel ändert sich, aber die Beweislast nicht
RLHF im PPO-Stil und DPO sind unterschiedliche Optimierungsschnittstellen für verwandte Ziele des Präferenzlernens. Keines von beiden beweist, dass die zugrunde liegenden Daten oder der Evaluator-Stack gut genug sind.
Im klassischen PPO-basierten RLHF wird die Policy gegen einen erlernten Reward optimiert, während sie nahe an einer Referenz-Policy bleibt:
DPO optimiert stattdessen einen paarweisen Loss über ausgewählte und abgelehnte Antworten, wobei das Referenzmodell weiterhin als Anker vorhanden ist:
Diese Substitution ist real. Sie beseitigt das explizite Training von Reward-Modellen als Voraussetzung für die Policy-Optimierung, entfernt Reward-Abfragen zur Rollout-Zeit während des Fine-Tunings und vermeidet die separate Value-Function- und Policy-Gradient-Maschinerie von PPO. Sie beseitigt jedoch nicht die Abhängigkeit von paarweisen Präferenzdaten, dem Referenz-Policy-Anker oder der Transfer-Evaluierung.
DPO removes explicit reward-model-plus-PPO training work, but not calibrated data, judge diagnostics, or transfer evaluation.
| Layer | PPO-era RLHF | DPO-family approach | What still must be measured | Why it stays hard |
|---|---|---|---|---|
| Reward model | Train an explicit reward model before PPO. | Represent the reward relation implicitly in pairwise loss. | Preference-label validity. | Noisy or narrow labels still optimize the wrong signal. |
| Policy optimization | Run PPO with value and policy-gradient machinery. | Optimize a reference-anchored offline objective. | Transfer to deployment behavior. | Offline data may miss current-policy errors. |
| On-policy data | Can collect new preference data during iterations. | Often starts from fixed comparison data. | Coverage of target slices. | Static data cannot cover new behaviors by default. |
| Evaluator stack | Used for reward-model training and release evidence. | Often shifts more trust to judges or fixed data. | Judge bias and reliability. | Position, verbosity, and perturbation failures remain. |
| Holdout transfer | Benchmark and downstream checks after PPO. | Benchmark and downstream checks after DPO. | Unseen prompts and policy lineage. | Benchmark rank is useful but insufficient. |
Reward model
- PPO-era RLHF
- Train an explicit reward model before PPO.
- DPO-family approach
- Represent the reward relation implicitly in pairwise loss.
- What still must be measured
- Preference-label validity.
- Why it stays hard
- Noisy or narrow labels still optimize the wrong signal.
Policy optimization
- PPO-era RLHF
- Run PPO with value and policy-gradient machinery.
- DPO-family approach
- Optimize a reference-anchored offline objective.
- What still must be measured
- Transfer to deployment behavior.
- Why it stays hard
- Offline data may miss current-policy errors.
On-policy data
- PPO-era RLHF
- Can collect new preference data during iterations.
- DPO-family approach
- Often starts from fixed comparison data.
- What still must be measured
- Coverage of target slices.
- Why it stays hard
- Static data cannot cover new behaviors by default.
Evaluator stack
- PPO-era RLHF
- Used for reward-model training and release evidence.
- DPO-family approach
- Often shifts more trust to judges or fixed data.
- What still must be measured
- Judge bias and reliability.
- Why it stays hard
- Position, verbosity, and perturbation failures remain.
Holdout transfer
- PPO-era RLHF
- Benchmark and downstream checks after PPO.
- DPO-family approach
- Benchmark and downstream checks after DPO.
- What still must be measured
- Unseen prompts and policy lineage.
- Why it stays hard
- Benchmark rank is useful but insufficient.
OpenTrain synthesis from DPO, InstructGPT, Anthropic RLHF, coverage theory, RewardBench 2, and public post-training recipes cited in this article.
Was DPO tatsächlich entfernt
DPO entfernt das explizite Training des Reward-Modells aus dem Pfad des Preference-Tunings und beseitigt die PPO-artige Online-Policy-Gradient-Optimierung aus dieser Phase. Aus technischer Sicht bedeutet das weniger bewegliche Teile, eine geringere Implementierungskomplexität, weniger Hyperparameter-Anfälligkeit und weniger Möglichkeiten, dass ein Kollaps des Reward-Modells oder PPO-Instabilität den Durchlauf dominieren.
Diese Vereinfachung erklärt, warum offene Post-Training-Stacks DPO schnell übernommen haben. Das ursprüngliche Paper betonte Stabilität und einen geringen Tuning-Aufwand, und öffentliche Rezepte wie die Zephyr-artigen Arbeiten und spätere Veröffentlichungen der Tulu-Familie machten DPO zu einer normalen Phase in offenen Alignment-Workflows.
Was DPO nicht beseitigt, ist die Abhängigkeit von vertrauenswürdigen Vergleichen. Der Optimierer erbt weiterhin die im Datensatz kodierte Präferenzrelation. Er hängt nach wie vor von der Wahl des Referenzmodells, der Beta-Skalierung, der Prompt-Verteilung und der Richtlinie zur Paarauswahl ab. Wenn die Labels verrauscht, in ihrer Verteilung eng, durch Annotationsartefakte verzerrt oder von einem fehleranfälligen Judge erstellt wurden, wird DPO dieses Problem effizient optimieren.
Die DPO-Familie hat sich aus demselben Grund diversifiziert. KTO ändert die Form der Supervision von paarweisen Präferenzen zu Signalen für wünschenswert gegenüber unerwünscht. ORPO integriert das Preference-Learning in eine monolithische SFT-artige Phase. SimPO entfernt den Referenzmodell-Term und verzeichnete in seinen Setups Verbesserungen gegenüber DPO. Dies sind bedeutsame algorithmische Änderungen, aber keine davon beseitigt die Notwendigkeit zu wissen, ob Labels, Judges oder Benchmarks die nachgelagerte Qualität widerspiegeln (KTO, ORPO, SimPO).
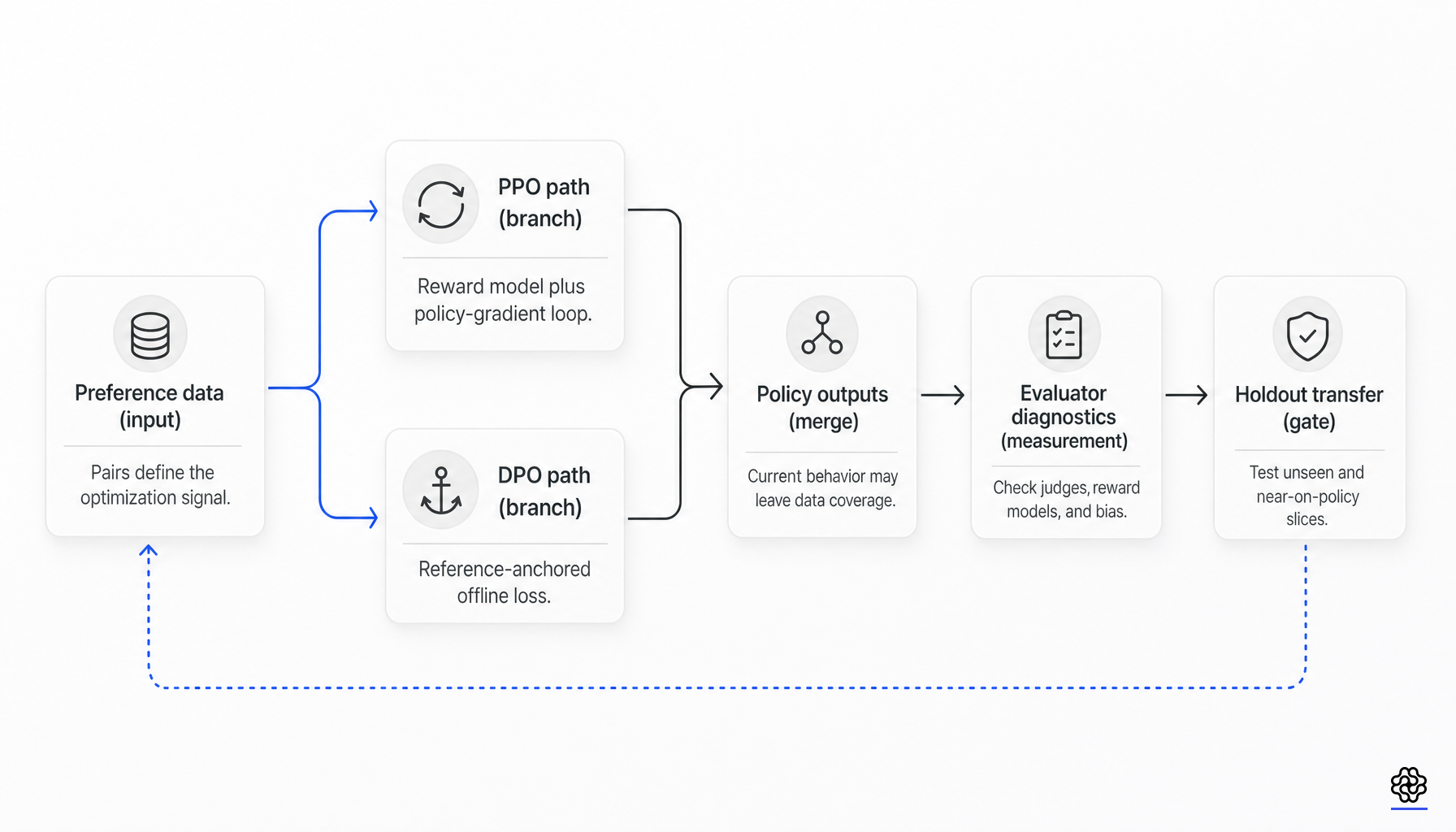
Was DPO nicht beseitigt
Die derzeit klarste Einschränkung stammt aus der Coverage-Literatur. Song et al. argumentieren, dass offline-kontrastive Methoden wie DPO eine stärkere globale Abdeckung benötigen, um zur optimalen Policy zu konvergieren, während Online-RL-Methoden auch bei schwächerer partieller Abdeckung erfolgreich sein können. Der operative Punkt ist einfach: Wenn der feste Präferenzdatensatz den Antwortraum, der zum Zeitpunkt der Evaluierung wichtig ist, nicht abdeckt, kann der Optimierer diese fehlenden Informationen nicht ableiten (Online-Daten und Abdeckung).
Tajwar et al. gelangen zu einem verwandten empirischen Punkt. Ihre Experimente legen nahe, dass On-Policy-Sampling und Präferenzziele im Stil negativer Gradienten rein Offline-Ziele übertreffen können, da sie Wahrscheinlichkeitsmasse schneller in bevorzugte Regionen umverteilen können. Das ist keine pauschale Verteidigung von PPO. Es ist eine Erinnerung daran, dass Online-Informationen von Bedeutung sein können, wenn die eigenen Fehler der aktuellen Policy nicht in statischen Daten abgebildet sind (On-Policy Preference Fine-Tuning).
An diesem Punkt bricht der DPO-gegen-PPO-Slogan normalerweise zusammen. Wenn das Zielverhalten stabil und in den Präferenzdaten gut repräsentiert ist, kann DPO den Großteil des praktischen Nutzens bei geringerer Komplexität erzielen. Wenn jedoch erwartet wird, dass das Modell nach dem Training in neue Verhaltensweisen, neue Prompt-Regime oder adversarielle Slices übergeht, benötigt das Team weiterhin On-Policy-Daten, Online-RL, Rejection-Sampling oder eine gezielte Datenaktualisierung.
Empirische Kontraste hinter dem Slogan
Die richtige Interpretation der Beweise ist nicht „DPO hat verloren“ oder „PPO hat gewonnen“. Sie lautet, dass DPO den Optimierer stärker verändert hat als die Epistemologie. Bessere Präferenzdaten, Abdeckung der aktuellen Policy, Reward-Model-Transfer und die Zuverlässigkeit der Judges dominieren oft das Algorithmus-Branding.
Public evidence favors a conditional reading: DPO is often simpler and strong, while data quality, coverage, and evaluator validity still decide transfer.
| Study/report | Setup | Key result | Measurement implication |
|---|---|---|---|
| DPO paper | DPO vs PPO-based RLHF. | DPO matched or improved summarization and dialogue quality while being simpler to train. | Explains DPO adoption without proving measurement is solved. |
| Unpacking DPO and PPO | Controlled preference-learning recipes. | PPO beat DPO in some math and general regimes while data quality moved results more. | Algorithm choice can matter less than data validity. |
| On-policy preference fine-tuning | Offline contrastive methods vs online or negative-gradient methods. | On-policy sampling can outperform pure offline objectives. | Coverage failures can make online information valuable. |
| RewardBench 2 | Benchmark score vs downstream use. | Best-of-N correlation was strong, but PPO transfer depended on lineage and distribution. | Benchmark rank alone is not transfer evidence. |
| JudgeBench | LLM judge evaluation. | Strong judges struggled on hard objective response pairs. | Automated evaluation can become the bottleneck after optimization is simplified. |
DPO paper
- Setup
- DPO vs PPO-based RLHF.
- Key result
- DPO matched or improved summarization and dialogue quality while being simpler to train.
- Measurement implication
- Explains DPO adoption without proving measurement is solved.
Unpacking DPO and PPO
- Setup
- Controlled preference-learning recipes.
- Key result
- PPO beat DPO in some math and general regimes while data quality moved results more.
- Measurement implication
- Algorithm choice can matter less than data validity.
On-policy preference fine-tuning
- Setup
- Offline contrastive methods vs online or negative-gradient methods.
- Key result
- On-policy sampling can outperform pure offline objectives.
- Measurement implication
- Coverage failures can make online information valuable.
RewardBench 2
- Setup
- Benchmark score vs downstream use.
- Key result
- Best-of-N correlation was strong, but PPO transfer depended on lineage and distribution.
- Measurement implication
- Benchmark rank alone is not transfer evidence.
JudgeBench
- Setup
- LLM judge evaluation.
- Key result
- Strong judges struggled on hard objective response pairs.
- Measurement implication
- Automated evaluation can become the bottleneck after optimization is simplified.
OpenTrain synthesis from the cited DPO, PPO, RewardBench 2, data-selection, and judge-evaluation sources.
Ivison et al. fanden PPO-Vorteile in einigen kontrollierten Regimen, zeigten aber auch, dass die Qualität der Präferenzdaten die Befolgung von Anweisungen und die Wahrhaftigkeit stärker beeinflussen konnte als der Wechsel des Optimierers selbst (Unpacking DPO and PPO). Datenzentrierte Arbeiten kommen zur gleichen praktischen Schlussfolgerung. Filtered DPO, Less is More und Datensätze im HelpSteer-Stil weisen alle auf dieselbe Einschränkung hin: Die gewählte Datenverteilung und das Label-Protokoll können die reine Datensatzgröße oder den Namen des Optimierers dominieren (Filtered DPO, Less is More, HelpSteer3-Preference).
Wo die Messung zuerst versagt
Der nützlichste Fehlermodus ist nicht abstraktes Reward-Hacking. Es ist ein falsch vorhergesagter Transfer: Das Offline-Präferenzziel sieht bei einer auf das Training abgestimmten Metrik gut aus, aber das nachgelagerte System versagt bei dem Verhalten, das dem Team eigentlich wichtig ist.
RewardBench 2 ist ein klares öffentliches Beispiel. Es wurde um ungesehene menschliche Prompts und ein schwierigeres best-of-4-Format herum aufgebaut. Die Scores waren im Durchschnitt etwa 20 Punkte niedriger als beim ursprünglichen RewardBench. Der Benchmark korrelierte stark mit der nachgelagerten best-of-N-Nutzung, mit einer Pearson-Korrelation von 0.87, aber er war nur ein hilfreiches Signal, kein ausreichender Transferbeweis für PPO. In den PPO-Experimenten des Papers erreichte ein Off-Policy-Reward-Model mit einem RewardBench 2-Score von 72.9 einen PPO-Score von 54.5, während ein On-Policy-Reward-Model mit einem RewardBench 2-Score von 68.7 einen PPO-Score von 59.8 erreichte (RewardBench 2).
Arbeiten zur Evaluierung von Reward-Models in Bezug auf Überoptimierung weisen in die gleiche Richtung. Wenn der Benchmark den Optimierungsdruck, den die Policy erfahren wird, nicht annähert, sagt ein hoher Benchmark-Score dem Team möglicherweise weniger, als es denkt (reward model evaluation, reward overoptimization).
Eine dritte Version zeigt sich im menschlichen Feedback selbst. Eine Studie aus dem Jahr 2024 zu Anthropic-HH fand erhebliche Segmente mit geringer oder keiner Übereinstimmung im Vergleich zu einem Komitee von Reward-Models, und ihr Modell mit bereinigten Daten verbesserte das nachgelagerte DPO-Verhalten unter dem Evaluierungs-Setup des Papers. Dies ist kein Beweis dafür, dass ein Reward-Model-Komitee der Ground Truth entspricht. Es ist ein Beweis dafür, dass feste Präferenzdaten kein Monolith sind (human feedback reliability).
Judges und Reward-Modelle benötigen weiterhin Diagnostik
Sobald Teams aufhören, ein explizites Reward-Modell für PPO zu trainieren, verlagern sie oft mehr Vertrauen auf LLM-Judges oder statische Präferenz-Sets. Das kann denselben Messfehler hinter einem saubereren Optimierer verbergen.
JudgeBench zeigte, dass starke Judges wie GPT-4o bei schwierigen, objektiven Antwortpaaren in den Bereichen Wissen, logisches Denken, Mathematik und Programmierung nur geringfügig besser abschnitten als reines Raten. Das Judge Reliability Harness von RAND aus dem Jahr 2026 erweiterte diesen Punkt: Kein von ihnen getesteter Judge war über alle Benchmarks hinweg einheitlich zuverlässig, und Störungen wie Formatierungsänderungen, Paraphrasen, Verschiebungen der Ausführlichkeit und Label-Flips verursachten signifikante Schwankungen in der Zuverlässigkeit (JudgeBench, Judge Reliability Harness).
Die Literatur zu Bias macht dies noch deutlicher. LLM-Evaluatoren können ihre eigenen Generierungen erkennen und bevorzugen. Paarweise Judges können Positions-Bias, Aufgabenabhängigkeit und stark umstrittene, schwierige Teilbereiche aufweisen. Length-Controlled AlpacaEval ist ein gutes Beispiel dafür, wie das Feld ein Messartefakt korrigiert, anstatt lediglich einen Optimierer zu verbessern (self-preference, position bias, Length-Controlled AlpacaEval).
Die Lektion zur Schadensbegrenzung lautet nicht, dass automatisierte Judges unbrauchbar sind. Sie lautet, dass ein Judge ein Instrument ist. Es benötigt Instrumentenprüfungen: Positionstausch, Paraphrasen-Invarianz, Ausführlichkeitskontrollen, wiederholtes Sampling und Anker-Elemente mit bekannten Labels.
Öffentliche Produktions-Stacks bleiben mehrstufig
Öffentliche Belege von führenden Modellherstellern deuten in dieselbe Richtung. Metas Post-Training-Bericht zu Llama 3.1 besagt, dass jede Alignment-Runde SFT, Rejection Sampling und DPO umfasste. Qwen2.5 berichtet von groß angelegtem SFT und mehrstufigem Reinforcement Learning. DeepSeek-R1 beschreibt zwei RL-Phasen, Cold-Start-Daten, Rejection Sampling und eine spätere Erweiterung der Supervision. Tulu 3 kombiniert SFT, kuratierte On-Policy-Präferenzdaten für DPO, Reward-Modeling, RL mit verifizierbaren Rewards, Dekontamination sowie getrennte Entwicklungs- gegenüber ungesehenen Evaluierungs-Suites (Llama 3.1, Qwen2.5, DeepSeek-R1, Tulu 3).
Die angemessene Formulierung ist eine Schlussfolgerung aus öffentlichen Belegen, keine universelle Tatsache über jeden geschlossenen Frontier-Stack. Aber die Schlussfolgerung ist stark: Leistungsstarke öffentliche Stacks betrachten DPO nicht als Grund, nicht mehr in Evaluierung, On-Policy-Datenaktualisierung, Rejection Sampling oder gezielte RL-Phasen zu investieren. Sie nutzen DPO als eine Phase in einem umfassenderen Post-Training-System.
Ein praktisches Implementierungsmuster
Ein technisch vertretbares Post-Training-Muster im Jahr 2026 sieht weniger wie „DPO oder PPO wählen“ aus und mehr wie ein gestuftes Messdesign.
Erstens benötigen Teams einen Präferenzdatensatz, der für den Zielanwendungsfall kalibriert und nicht einfach nur groß ist. Wenn die Datenquelle heterogen ist, sollte sie nach Evaluatoren-Quelle, Prompt-Familie, Aufgabentyp und wahrscheinlichem Rauschregime unterteilt werden, bevor Aussagen über das Training getroffen werden.
Zweitens benötigen Teams Diagnostik für Evaluatoren, bevor sie ein Reward-Modell oder einen LLM-Judge als Trainer oder Assessor einsetzen. Das bedeutet mindestens Positionswechsel-Prüfungen, Prüfungen auf Paraphrasen- und Formatierungsinvarianz, Prüfungen auf Verbositäts-Bias, Stabilität bei wiederholtem Sampling und ein kleines, von Menschen verifiziertes Anker-Set.
Drittens benötigen Teams eine echte Transfer-Evaluierung. Der Holdout-Datensatz besteht nicht nur aus zurückgehaltenen Präferenzpaaren. Er sollte ungesehene Prompts, adversarielle Slices, Judge-Stress-Slices und, wo möglich, einen On-Policy- oder Near-On-Policy-Slice umfassen, der vom aktuellen Modell erzeugt wurde.
Viertens sollten Teams durch die Diagnose der Abdeckung und nicht aus ideologischen Gründen entscheiden, ob Online-Daten erforderlich sind. Wenn sich Evaluierungsfehler bei Current-Policy-Ausgaben häufen oder wenn sich das Modell in Reasoning- oder Sicherheitsbereiche bewegt, die im Datensatz nicht vertreten sind, können Online-Datenerfassung, Rejection Sampling oder RL immer noch der kostengünstigere Weg sein, um zuverlässige Verbesserungen zu erzielen.
Die praktische Erkenntnis ist spezifisch, aber gewichtig. DPO sollte als Ersatz für den Optimierer behandelt werden, nicht als Ersatz für die Evaluierung. Es beseitigt oft teure Online-Optimierungsmechanismen. Es beseitigt jedoch nicht die Notwendigkeit zu wissen, ob sich das gewählte Präferenzziel, der Labeling-Prozess, das Reward-Modell oder der Judge tatsächlich übertragen lassen.
OpenTrain kann spezialisierte Evaluatoren und Operatoren für Präferenzdaten innerhalb des Stacks beschaffen, den ein Team bereits verwendet. Nutzen Sie die LLM-Referenz zur Judge-Zuverlässigkeit für den Kontext der Evaluatoren-Kalibrierung, den RLHF-Scoping-Leitfaden für die Planung von Präferenzdaten und veröffentlichen Sie einen Job, wenn der Engpass in der personellen Besetzung der Review-Schleife liegt.
Quellen
- Direct Preference Optimization
- Training language models to follow instructions with human feedback
- Training a Helpful and Harmless Assistant with RLHF
- Unpacking DPO and PPO
- Preference fine-tuning with suboptimal on-policy data
- The Importance of Online Data
- RewardBench 2
- Evaluierung von Belohnungsmodellen
- Belohnungs-Überoptimierung
- JudgeBench
- Judge Reliability Harness
- LLM-Evaluatoren erkennen und bevorzugen ihre eigenen Generierungen
- Beurteilung der Evaluatoren
- Gefilterte Direct Preference Optimization
- Weniger ist mehr
- HelpSteer3-Preference
- Llama 3.1
- Qwen2.5 technischer Bericht
- Tulu 3
- DeepSeek-R1
- KTO
- ORPO
- SimPO
- Length-Controlled AlpacaEval