LLM-Judges sind Messsysteme, keine Orakel

Evidenzbasierte technische Referenz dazu, wann LLM-Judges zuverlässig genug für Produktions-Evals und Post-Training sind und wie man sie kalibriert, prüft und zulässt.
LLM-Judges sind in der Produktion einsetzbar, jedoch nur als Messsysteme, die versioniert, kalibriert und auditiert werden. Die zentrale Spannung besteht darin, dass der meistzitierte Erfolgsfall der Branche, bei dem GPT-4 eine Übereinstimmung von über 80% mit menschlichen Präferenzen bei MT-Bench und Chatbot Arena erreicht, nun neben neueren Erkenntnissen steht, die drastische Transferausfälle zeigen, sobald sich der Aufgabenmix, die Benchmark-Konstruktion, die Metrik oder die Judge-Familie ändert (MT-Bench and Chatbot Arena, Arena-Hard, JUDGE-BENCH, JudgeBench).
Diese Ergebnisse sind nicht widersprüchlich. Sie beschreiben, was passiert, wenn ein Judge als portable Wahrheitsquelle anstatt als kalibriertes Instrument behandelt wird.
Frühe Übereinstimmungsergebnisse waren Benchmark-lokal, nicht universell
Die frühen positiven Ergebnisse waren real. MT-Bench und Chatbot Arena haben etabliert, dass starke paarweise Judges menschliche Präferenzurteile bei breiten Vergleichen im Chat-Stil annähern können. G-Eval zeigte, dass strukturiertes GPT-4-Judging ältere automatische Metriken bei der Zusammenfassung übertreffen konnte, warnte jedoch vor einem Evaluator-Bias zugunsten von LLM-generiertem Text (G-Eval). Prometheus 2 zeigte später, dass offene Evaluator-Modelle als dedizierte Judge-Modelle mit benutzerdefinierten Kriterien erheblich verbessert werden können (Prometheus 2).
Diese Kombination ist entscheidend. Sie bedeutet, dass die Branche nicht abstrakt bewiesen hat, dass „ein LLM-Judge funktioniert“. Sie hat vielmehr engere Behauptungen belegt: Ein Judge kann eine bestimmte menschliche Präferenzverteilung bei einer bestimmten Benchmark-Familie unter einem bestimmten Prompting- und Aggregationsschema abbilden.
AlpacaEval verdeutlicht denselben Punkt aus der anderen Richtung. Seine längenkontrollierte Gewinnrate erhöhte die Korrelation mit Chatbot Arena und verringerte die Manipulierbarkeit durch Textlänge, aber die Maintainer warnen weiterhin davor, automatische Evaluatoren allein für Release-Entscheidungen zu verwenden. Ein Judge kann für die iterative Entwicklung nützlich sein, auch wenn er als finales Gate noch schwach ist.
Härtere Meta-Evaluationen haben die Portabilitäts-Story widerlegt
Arena-Hard machte das Portabilitätsproblem konkret. Es wurde aus per Crowdsourcing gewonnenen Live-Daten entwickelt, um die Trennbarkeit zwischen starken Instruction-Tuned-Modellen zu verbessern, und die Autoren berichteten von einer starken Übereinstimmung mit Chatbot Arena bei geringen Kosten. In derselben Studie konnte MT-Bench zwar noch eine grobe Rangfolge beibehalten, versagte jedoch bei der Trennbarkeit deutlich stärker. Genau das ist die Metrik-Diskrepanz, die die Release-Gate-Logik bricht: Ein Benchmark kann Kandidaten in eine Rangfolge bringen und dennoch daran scheitern, Near-Frontier-Systeme gut genug für Release-Entscheidungen zu trennen.
JUDGE-BENCH erweiterte das Problem auf 20 NLP-Evaluierungsaufgaben und 11 Judge-Modelle. Die Modelle mit den meisten gültigen Antworten erreichten im Durchschnitt eine bescheidene zufallskorrigierte Übereinstimmung, mit sehr großer Varianz je nach Datensatz. GPT-4o konnte in einem Teilbereich stark aussehen und in einem anderen nahe null oder negativ. Dieselbe Arbeit stellte fest, dass Judges besser mit Nicht-Experten-Annotationen übereinstimmten als mit Experten-Annotationen und besser mit von Menschen generierter Sprache als mit maschinell generiertem Text.
JudgeBench ging noch weiter, indem es sich von stilistischer oder Crowd-Präferenz-Ausrichtung abwandte und sich auf objektive Korrektheit in Wissen, logischem Denken, Mathematik und Programmierung konzentrierte. Das Abstract berichtet, dass viele starke Judges, einschließlich GPT-4o, bei schwierigeren Antwortpaaren nur geringfügig besser abschneiden als zufälliges Raten. IF-RewardBench weitet die Kritik auf die Evaluierung der Befehlsbefolgung aus und argumentiert, dass eine rein paarweise Meta-Evaluierung nicht mit den in der Optimierung verwendeten listenweisen Ranking-Workflows übereinstimmt (IF-RewardBench).
Benchmark snapshots show transfer limits
| Benchmark | Evaluation regime | Reliability implication |
|---|---|---|
| MT-Bench / Chatbot Arena | Pairwise chat preference judgments | Strong benchmark-local agreement does not imply universal transfer. |
| Arena-Hard | Harder separability from live arena data | Benchmark construction changes what agreement means. |
| JUDGE-BENCH | 20 NLP tasks and 11 judge models | Chance-corrected and rank metrics vary substantially by task. |
| JudgeBench | Objective correctness across reasoning domains | Correctness-heavy tasks expose weak transfer from preference-style judging. |
MT-Bench / Chatbot Arena
- Evaluation regime
- Pairwise chat preference judgments
- Reliability implication
- Strong benchmark-local agreement does not imply universal transfer.
Arena-Hard
- Evaluation regime
- Harder separability from live arena data
- Reliability implication
- Benchmark construction changes what agreement means.
JUDGE-BENCH
- Evaluation regime
- 20 NLP tasks and 11 judge models
- Reliability implication
- Chance-corrected and rank metrics vary substantially by task.
JudgeBench
- Evaluation regime
- Objective correctness across reasoning domains
- Reliability implication
- Correctness-heavy tasks expose weak transfer from preference-style judging.
OpenTrain synthesis from cited benchmark and meta-evaluation sources.
Zufallskorrigierte Zuverlässigkeitsmetriken
Prozentuale Übereinstimmung ist für sich genommen ein schwaches Freigabeargument. Wenn die Label-Verteilung verzerrt ist, kann ein Judge oft übereinstimmen, während er nur wenig Informationen hinzufügt. Bei der kategorialen Evaluierung gehört die zufallskorrigierte Übereinstimmung neben die allgemeine Übereinstimmung.
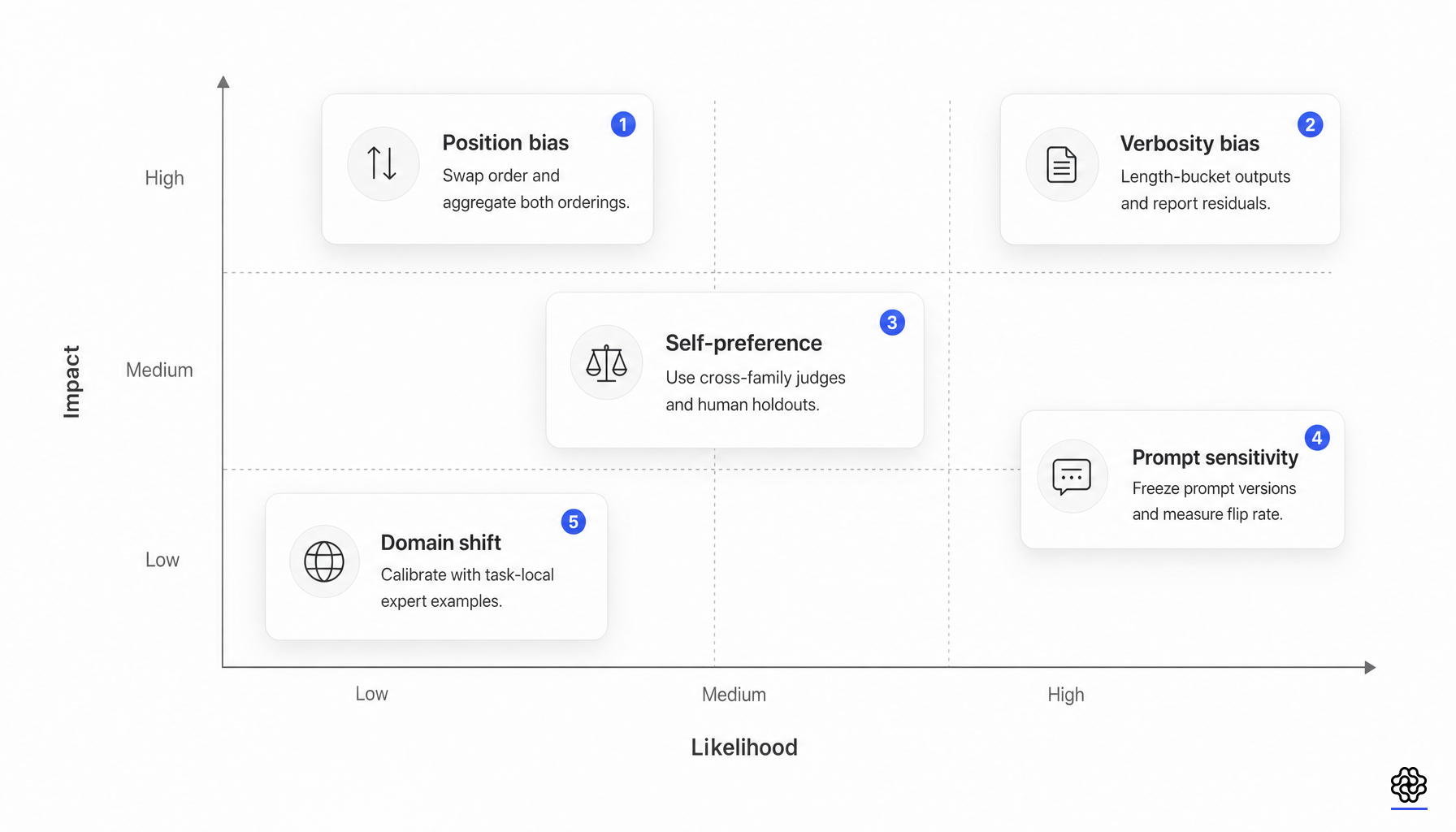
Bias und Judge-Familien-Effekte erzeugen strukturierte Fehler
Das wichtigste Zuverlässigkeits-Update des Fachgebiets ist, dass Bias keine Randnotiz mehr ist. Er ist eine messbare Quelle für strukturierte Fehler.
Die Arbeit zum Positions-Bias ist über Anekdoten hinausgegangen. Eine systematische Studie über MTBench und DevBench hinweg führte Wiederholungsstabilität, Positionskonsistenz und Präferenzfairness ein, analysierte mehr als 100,000 Evaluierungsinstanzen und stellte fest, dass Positions-Bias kein Zufall ist (position bias study). Die Identität des Judges, die Aufgabenkategorie und die Lücke in der Antwortqualität spielen alle eine Rolle.
Selbstpräferenz ist ebenso wichtig, da sie die Evaluierung an die Modellfamilie koppelt. Eine Forschungsrichtung zeigte, dass LLM-Evaluatoren ihre eigenen Generierungen erkennen und bevorzugen können; eine spätere Studie verknüpfte die Selbstpräferenz von GPT-4 eher mit Vertrautheit und geringerer Perplexität als mit einfacher Eitelkeit (self-recognition, self-preference). Dies ist immer dann von Bedeutung, wenn der Judge, die Policy und der Datengenerator aus derselben Familie stammen oder einen ähnlichen Post-Training-Stil teilen.
Das Referenzdesign ändert den Fehlermodus erneut. „No Free Labels“ fand heraus, dass die Fähigkeit eines Judges, eine Frage zu beantworten, mit seiner Fähigkeit zusammenhängt, Antworten auf diese Frage zu bewerten, und dass ein schwächerer Judge mit stärkeren menschlichen Referenzen einen stärkeren Judge mit synthetischen Referenzen schlagen kann (No Free Labels). Ensemble-Ergebnisse deuten in die gleiche Richtung: Diverse Judge-Panels können den Single-Family-Bias reduzieren und in einigen Umgebungen weniger kosten als ein einzelner großer Judge (Replacing Judges with Juries).
Im Post-Training ist die Reward-Qualität nur so gut wie die Judge-Kalibrierung
Sobald der Judge von der Evaluierung ins Training übergeht, wird der Messfehler zum Optimierungsfehler. RewardBench lieferte das ursprüngliche Argument für die direkte Evaluierung von Reward-Modellen durch Prompt-, Chosen- und Rejected-Tripel. RewardBench 2 aktualisierte diese Geschichte mit einem härteren Benchmark, der aus größtenteils ungesehenen menschlichen Prompts, sechs Domänen, 1,865 Prompts, Vervollständigungen von 20 Modellen oder Menschen, einem Best-of-4-Scoring-Setup und einem Ties-Subset besteht, das die Kalibrierung zwischen gleichwertig gültigen Antworten testen soll (RewardBench 2, dataset card).
RewardBench 2 ist nützlich, weil es sich einer vereinfachenden Geschichte über die Übertragung von Benchmark-Scores ins Training widersetzt. Das Paper zeigt eine starke Korrelation mit der Best-of-N-Sampling-Performance, besagt aber auch, dass die RLHF PPO-Korrelation von kontextspezifischen Faktoren beeinflusst wird. Genauigkeitsbasierte Reward-Benchmark-Scores sind eine Voraussetzung für ein starkes RLHF Training, aber sie sind nicht ausreichend.
Bessere Judge-Signale können helfen, wenn sie sorgfältig eingesetzt werden. Crowd Comparative Reasoning erweitert die paarweise Beurteilung um zusätzliche Crowd-Antworten und zeigt Verbesserungen über Präferenz-Benchmarks hinweg, einschließlich nachgelagerter Rejection-Sampling-Verbesserungen (Crowd Comparative Reasoning). Die Lektion ist nicht, dass zusätzliche Judge-Time-Compute die Zuverlässigkeit löst. Sie lautet, dass reichhaltigere Beurteilungsprotokolle das Messsignal verbessern können, das für die Auswahl und Filterung verwendet wird.
Offizielle Produktdokumentationen spiegeln nun dieselbe Realität wider. Die Grader-Dokumentation von OpenAI behandelt Grader als First-Class-Objekte für Evals und Reinforcement Fine-Tuning, empfiehlt, Grader gegen hochwertige Modell- und menschliche Beispiele zu testen, und definiert Grader-Hacking als den Fall, in dem ein Modell bei Grader-Evals gut abschneidet, aber bei menschlichen Expertenbewertungen schlecht (OpenAI graders, reinforcement fine-tuning cookbook). Der Fehlermodus ist unkompliziert: Das Team bindet einen Judge in den Loop ein, bevor es validiert, ob der Score ausgerichtet bleibt, sobald die Policy beginnt, dagegen zu optimieren.
Where judge signals enter post-training
| Workflow stage | Judge artifact | Minimum control |
|---|---|---|
| Eval-only regression testing | Versioned judge prompt over a calibration set | Track drift, slice deltas, and chance-corrected agreement. |
| Rejection sampling | Pairwise, listwise, or verifier score | Audit whether selection improves human-preferred outputs on target slices. |
| Reward-model benchmarking | Reward model or judge ensemble | Separate benchmark score from downstream PPO or best-of-N behavior. |
| RFT / RLHF grading | Rubric grader or reward signal | Run small-scale validation before scaling optimization. |
| Release gating | Calibrated judge score plus human audit | Require uncertainty bounds, disagreement limits, and slice checks. |
Eval-only regression testing
- Judge artifact
- Versioned judge prompt over a calibration set
- Minimum control
- Track drift, slice deltas, and chance-corrected agreement.
Rejection sampling
- Judge artifact
- Pairwise, listwise, or verifier score
- Minimum control
- Audit whether selection improves human-preferred outputs on target slices.
Reward-model benchmarking
- Judge artifact
- Reward model or judge ensemble
- Minimum control
- Separate benchmark score from downstream PPO or best-of-N behavior.
RFT / RLHF grading
- Judge artifact
- Rubric grader or reward signal
- Minimum control
- Run small-scale validation before scaling optimization.
Release gating
- Judge artifact
- Calibrated judge score plus human audit
- Minimum control
- Require uncertainty bounds, disagreement limits, and slice checks.
OpenTrain synthesis from RewardBench 2, OpenAI grader guidance, RLAIF literature, and recent rubric-based post-training work.
Ein Production-Judge-Stack benötigt Kalibrierung, Versionierung und menschliche Eskalation
Öffentliches Material von OpenAI und Anthropic deutet darauf hin, dass Frontier-Teams Judges als Komponenten in mehrschichtigen Mess-Stacks behandeln und nicht als eigenständige Freigabeinstanzen. OpenAI stellt Grader als Teil von Eval- und Reinforcement-Fine-Tuning-Workflows zur Verfügung. Anthropic berichtet, dass ein einzelner LLM Judge für Komponenten eines Forschungssystems mit klaren Antworten konsistent sein kann, während gleichzeitig betont wird, dass menschliche Tests unerlässlich bleiben, da Menschen Halluzinationen, Systemausfälle und Quellqualitätsfehler erkennen, die der Automatisierung entgehen (Anthropic engineering).
Neuere Literatur zur Kalibrierung nähert sich derselben Sichtweise an. SLMEval argumentiert, dass mehrere kalibrierte Evaluatoren bei realen, offenen Aufgaben versagen, und berichtet von einer Verbesserung für Produktionsanwendungsfälle durch die Nutzung kleiner Mengen menschlicher Präferenzdaten plus entropiebasierter Kalibrierung (SLMEval). Ein auf IRT basierendes Paper zur Zuverlässigkeit unterscheidet zwischen intrinsischer Konsistenz, die fragt, ob sich der Judge unter Prompt-Variationen stabil verhält, und menschlichem Alignment, das fragt, ob dieses stabile Verhalten tatsächlich mit menschlichen Qualitätsbewertungen übereinstimmt (IRT reliability).
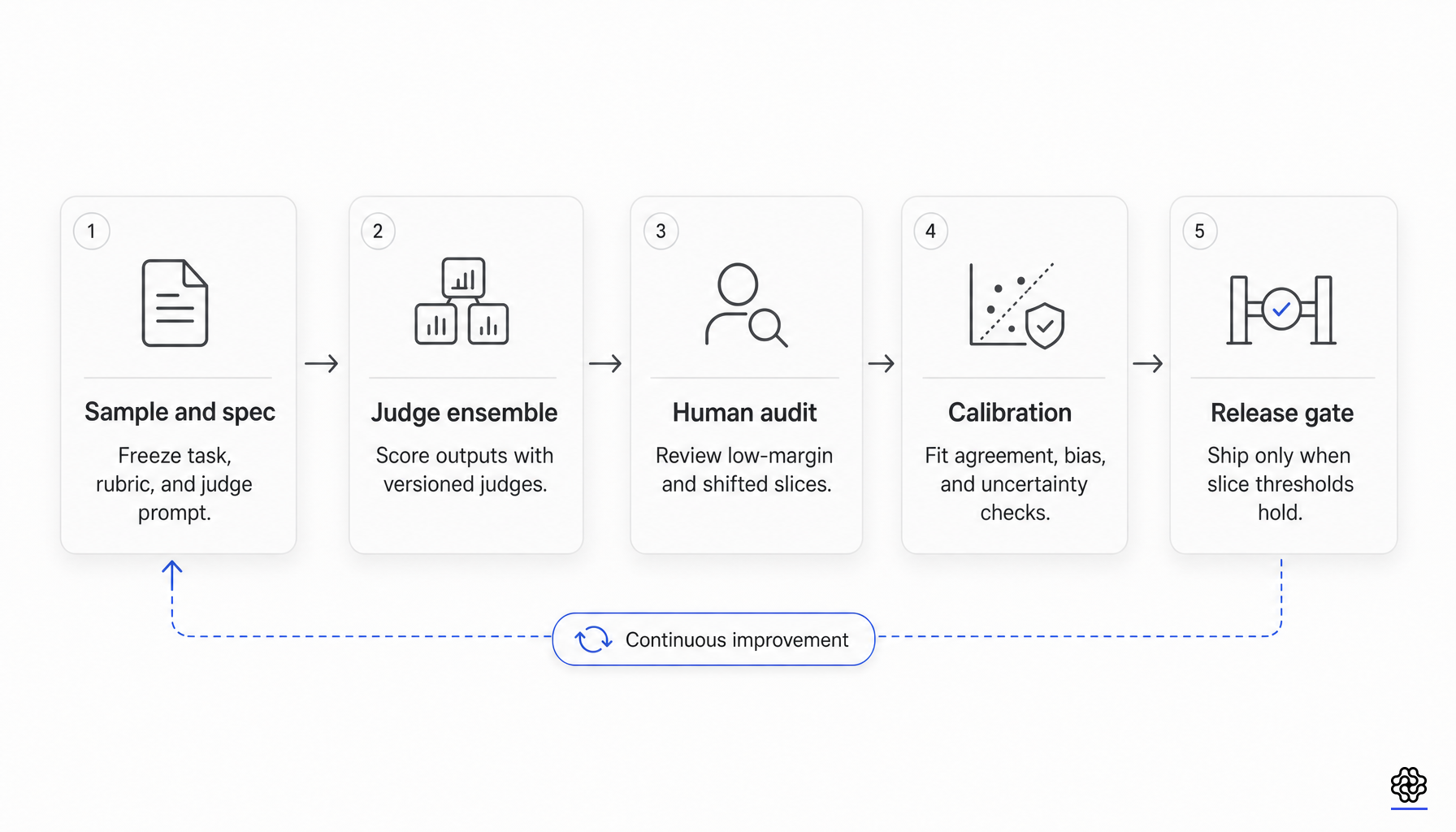
Ein konkretes Anti-Pattern für Release-Gates ergibt sich aus den Belegen: die Verwendung eines einzelnen durchschnittlichen Judge-Scores oder einer paarweisen Win-Rate als universeller Schwellenwert für das Bestehen. Dies setzt eine Messinvarianz voraus, die durch die aktuellen Belege nicht gestützt wird. Ein besserer Mindeststandard ist enger gefasst und wird explizit auditiert:
- Fixieren Sie die Version des Judge-Modells, den Judge-Prompt, den Rubriktext, die Referenzrichtlinie, die Gleichstandsregelung und die Aggregationslogik.
- Pflegen Sie ein von Menschen gelabeltes Kalibrierungsset für die exakte Release-Verteilung, einschließlich hochriskanter Segmente.
- Berichten Sie mindestens eine zufallskorrigierte Übereinstimmungsmetrik sowie eine Rang- oder Trennbarkeitsmetrik.
- Überprüfen Sie Reihenfolgeeffekte, Stil- und Längeneffekte, Präferenzen für die eigene Modellfamilie und Referenzsensitivität.
- Trennen Sie die Reward-Auswahl zur Trainingszeit von der Akzeptanz zur Release-Zeit.
- Eskalieren Sie Segmente mit geringem Abstand, hoher Uneinigkeit oder neuen Verschiebungen zur menschlichen Beurteilung.
Die praktische Grenze
Die praktische Bedeutung für Produktionsteams ist begrenzt, aber dennoch stark. LLM-Bewerter sind dort nützlich, wo menschliche Evaluierung zu langsam oder zu teuer ist, um kontinuierlich ausgeführt zu werden, wo das Evaluierungsziel offen ist und wo das Team bereit ist, echten Aufwand in Kalibrierung, Bias-Audits und Warteschlangen für menschliche Entscheidungen zu investieren.
Sie sind keine portablen Wahrheitsmesser. Sie sind Messinfrastruktur. Teams, die sie als solche behandeln, können sie für die tägliche Regressionserkennung, Kandidatenfilterung, Auswahl von Reward-Modellen und gezielte menschliche Eskalation nutzen. Teams, die dies nicht tun, werden letztendlich in ihre blinden Flecken hinein optimieren.
OpenTrain kann spezialisierte menschliche Prüfer für Kalibrierungsdatensätze, Audit-Slices und Drift-Checks innerhalb des Evaluierungs-Stacks beschaffen, den ein Team bereits nutzt. Beginnen Sie mit dem Managed Service, wenn der Engpass im Betrieb der Überprüfungsschleife liegt, oder veröffentlichen Sie ein Stellenangebot, wenn das Team direkt einstellen möchte.
Quellen
- MT-Bench and Chatbot Arena
- G-Eval
- AlpacaEval
- Arena-Hard
- JUDGE-BENCH
- JudgeBench
- IF-RewardBench
- Positions-Bias bei LLM-as-a-judge
- Selbsterkennung und Selbstpräferenz
- No Free Labels
- RewardBench 2
- OpenAI-Bewerter
- OpenAI-Cookbook für Reinforcement Fine-Tuning
- Anthropic Multi-Agenten-Forschungssystem
- SLMEval
- Diagnose der Zuverlässigkeit mittels Item-Response-Theorie