So definieren Sie den Umfang eines RLHF-Datenprogramms

Ein praktisches Framework für den Start eines RLHF-Programms: Definieren Sie die Warteschlangengeometrie, dimensionieren Sie die Bewerter anhand des beobachteten Durchsatzes.
Die meisten ersten RLHF-Datenprogramme scheitern auf der menschlichen Ebene, nicht an der PPO-Schleife. Die teuren Fehler sind alltäglich: eine Rubrik, die Sicherheit, Faktizität, Stil und Aufgabenerfolg in einem Klick vermischt; kein Kalibrierungsdurchlauf vor dem produktiven Labeling; und ein Budget, das davon ausgeht, dass jedes Präferenzpaar die gleichen Kosten verursacht. Öffentliche Beispiele reichen von OpenAIs früher Backflip-Arbeit, die etwa 900 Bits an Feedback in weniger als einer Stunde Evaluatorenzeit nutzte, bis hin zu Anthropics HH-RLHF-Release mit 169,352 ausgewählten/abgelehnten Zeilen (OpenAI, Anthropic HH-RLHF dataset). Der Umfang sollte sich aus der Aufgabengeometrie ergeben und nicht durch das Kopieren einer Schlagzeilenzahl eines Frontier-Labs.
Was beurteilen Menschen eigentlich?
Beginnen Sie mit einer enger gefassten Frage als „Welche Antwort ist besser?“. InstructGPT trennte überwachte Demonstrationen, Belohnungsmodell-Vergleiche und Prompts für die Richtlinienoptimierung; diese Datenprodukte trainieren verschiedene Teile des Systems (InstructGPT). Demonstrationen lehren Format und Aufgabenabschluss. Präferenzpaare lehren relative Beurteilung. Prompt-Pools entscheiden, was das feinabgestimmte Modell während des Trainings sieht.
Für ein erstes oder zweites Programm sollten Sie die Arbeit in drei Warteschlangen aufteilen:
- Erfolgs-Warteschlange: Prompts, bei denen das Modell meistens richtig liegt und gelegentliche Präferenzprüfungen benötigt.
- Grenz-Warteschlange: Randfälle, bei denen das Verhalten in Bezug auf Richtlinien, Sicherheit, Faktizität oder Stil abweicht.
- Wiederherstellungs-Warteschlange: Adversarielle oder Hochrisiko-Fälle, bei denen eine falsche Antwort teuer ist.
Diese Aufteilung der Warteschlangen bestimmt, welches Annotationsprodukt zuerst gekauft werden sollte. Wenn Sie paarweise Präferenzen benötigen, richten Sie das Programm auf RLHF und Präferenzdaten aus. Wenn der Fehler innerhalb der Antwort liegt, sammeln Sie Labels innerhalb der Antwort. OpenAIs Arbeit zur Prozessüberwachung veröffentlichte PRM800K mit rund 800,000 Labels auf Schrittebene und stellte fest, dass die Prozessüberwachung die Ergebnisüberwachung im evaluierten MATH-Setting übertraf (Let’s Verify Step by Step). Für Mathematik, Code-Reasoning und mehrstufige Werkzeugnutzung ist die paarweise Präferenz allein oft zu grob.
Wie viele Daten sind für den ersten ernsthaften Durchlauf ausreichend?
Nutzen Sie öffentliche Programme als Orientierungsgrößen, nicht als Quoten. Die Zusammenfassungsarbeit von OpenAI nutzte 64,832 Zusammenfassungsvergleiche; InstructGPT berichtete von etwa 13,000 überwachten Prompts, etwa 33,000 Reward-Model-Prompts und etwa 40 überprüften Auftragnehmern; PRM800K war viel größer, da jede Überwachungseinheit eine kleinere Beurteilung auf Schrittebene war (summarization from human feedback, InstructGPT, PRM800K).
Public RLHF program shapes
| Public program | Human-feedback footprint | What it tells you |
|---|---|---|
| OpenAI backflip | About 900 bits of feedback, under 1 hour of evaluator time, and about 70 hours of simulated experience. | Very narrow objectives can justify tiny pilots if the task is easy to judge. |
| OpenAI summarization | 64,832 summary comparisons. | A single-task text-alignment program reaches tens of thousands quickly once you want stable reward modeling. |
| InstructGPT | About 13k SFT prompts, 33k reward-model prompts, and about 40 contractors. | Assistant alignment usually needs multiple queues, not one annotation type. |
| Anthropic HH-RLHF | 169,352 chosen and rejected rows in the released dataset; the underlying training setup used weekly online refresh with fresh human feedback. | Conversational post-training benefits from refresh loops, not one static batch. |
| OpenAI process supervision | PRM800K with 800,000 step-level labels; the process-supervised model solved 78% of a representative MATH subset. | Step-level labels are only worth the cost when intermediate correctness is the real bottleneck. |
OpenAI backflip
- Human-feedback footprint
- About 900 bits of feedback, under 1 hour of evaluator time, and about 70 hours of simulated experience.
- What it tells you
- Very narrow objectives can justify tiny pilots if the task is easy to judge.
OpenAI summarization
- Human-feedback footprint
- 64,832 summary comparisons.
- What it tells you
- A single-task text-alignment program reaches tens of thousands quickly once you want stable reward modeling.
InstructGPT
- Human-feedback footprint
- About 13k SFT prompts, 33k reward-model prompts, and about 40 contractors.
- What it tells you
- Assistant alignment usually needs multiple queues, not one annotation type.
Anthropic HH-RLHF
- Human-feedback footprint
- 169,352 chosen and rejected rows in the released dataset; the underlying training setup used weekly online refresh with fresh human feedback.
- What it tells you
- Conversational post-training benefits from refresh loops, not one static batch.
OpenAI process supervision
- Human-feedback footprint
- PRM800K with 800,000 step-level labels; the process-supervised model solved 78% of a representative MATH subset.
- What it tells you
- Step-level labels are only worth the cost when intermediate correctness is the real bottleneck.
OpenTrain synthesis from cited public sources.
Die erste Regel lautet: Pilotieren vor dem Skalieren. RewardBench berichtet, dass einige Präferenzdaten-Testsets eine menschliche Obergrenze der Genauigkeit im Bereich von 60-70% aufweisen, was bedeutet, dass Uneinigkeit eher eine Eigenschaft der Aufgabe als ein Versagen der Bewerterkapazität sein kann (RewardBench). Wenn Ihre Pilot-Übereinstimmung schlecht ist, fügen Sie Spezifikationen hinzu, bevor Sie weitere Plätze hinzufügen.
Die zweite Regel lautet: Erhöhen Sie die Informationsdichte vor der Anzahl der Prompts. InstructGPT bat Labeler, 4 bis 9 Ausgaben für einen Prompt in eine Rangfolge zu bringen, was mehr Vergleichsinformationen pro Prompt erzeugte als eine einzelne binäre Entscheidung (InstructGPT). Das ist oft ein besserer erster Schritt, als den Bewerter-Pool bei einer instabilen Rubrik zu verdoppeln.
Wie viele Bewerter benötigen Sie tatsächlich?
Die Anzahl der Bewerter ist eine Durchsatzberechnung mit einem Puffer für Uneinigkeiten:
Verwenden Sie Ihre Pilotzahlen für den Nenner. Die produktive Auslastung umfasst alles, was Zeit vom reinen Labeling stiehlt: Rubrik-Aktualisierungen, Schlichtungen, Stichproben, Umschulungen, Pausen und Tool-Reibung.
Angenommen, der Pilot zeigt 180 kalibrierte Beurteilungen pro Bewerter pro Woche und die nächste Aktualisierung benötigt 3,000 Beurteilungen pro Woche. Bei 70% produktiver Auslastung besteht das Basisteam aus ceil(3000 / 180 / 0.70) = 24 Bewertern, bevor Puffer für Domäne, Sprache, Zeitzone und Backup-Kapazität berücksichtigt werden. Wenn die Warteschlange vier Domänen-Sprach-Zellen benötigt, führen Sie die Berechnung pro Zelle durch, bevor Sie die Gesamtsumme zusammenfassen.
Öffentliche Ankerpunkte sind nur als Plausibilitätsprüfungen nützlich. InstructGPT berichtete von einer Übereinstimmung der Trainings-Labeler von 72.6 +/- 1.5% und einer Übereinstimmung der zurückgehaltenen Labeler von 77.3 +/- 1.3%; OpenAIs Zusammenfassungsarbeit berichtete von 73 +/- 4% Übereinstimmung zwischen Forschern (InstructGPT, summarization from human feedback). Diese Zahlen sind keine Vorgaben für die Anzahl der Bewerter. Sie sind Erinnerungen daran, dass ein kleines, kalibriertes Team einen ernsthaften Durchlauf unterstützen kann und dass Unstimmigkeiten im hohen 60er- oder niedrigen 70er-Bereich normal sein können, wenn die Aufgabe schwierig ist.
Abdeckung ist genauso wichtig wie die reine Anzahl. Wenn die Warteschlange Medizin, mehrsprachige Sicherheit und Code-Reviews umfasst, dimensionieren Sie Domänen-Sprach-Zellen und nicht einen einzigen, zusammengefassten Arbeitspool. Das AI RMF von NIST fordert vielfältige Perspektiven bei der Erfassung und Messung von KI-Risiken; sein Generative AI Profile empfiehlt ebenfalls strukturierte Human-Feedback-Übungen mit dokumentierten Rollen und Überprüfungspfaden (NIST AI RMF 1.0, NIST GenAI Profile).
Wie sollte das Budget aufgebaut sein?
Eine primäre Preisliste für RLHF Präferenzpaare über Domänen, Sprachen und Aufgabendesigns hinweg ist nicht öffentlich verifizierbar. Budgetieren Sie stattdessen auf Basis von zeitlich erfasster Arbeit:
Der Budgetposten, den Teams übersehen, ist die Zeit für Schlichtung und Forscher. Das Zusammenfassungspapier von OpenAI besagt, dass der Human-Feedback-Datensatz erhebliche Labeler-Stunden und Forscherzeit erforderte, um die Qualität sicherzustellen (summarization from human feedback). Das ist der Grund, warum Pilotprojekte, die in einer Tabellenkalkulation günstig aussehen, teuer werden, sobald sich die Bewertungsrichtlinien ändern.
Behandeln Sie Beschaffungs- und Marktplatzgebühren getrennt von den Arbeitskosten. OpenTrain veröffentlicht eine 15% Self-Service-Gebühr und eine 20% Managed-Service-Gebühr; Teams können entweder direkt einstellen oder den Managed Service nutzen, wenn sie möchten, dass OpenTrain den Projektbetrieb übernimmt (OpenTrain pricing). Das ist wichtig, wenn der Engpass in der Beschaffung und dem Betrieb einer kalibrierten Warteschlange liegt und nicht im Entwurf des Modell-Updates.
Welchen Zeitplan sollten Sie einplanen?
Denken Sie in Etappen, nicht in einer einzigen monolithischen Labeling-Phase:
- Spezifikation: Definieren Sie die Rubrik, die Regeln für Unstimmigkeiten und den Eskalationspfad.
- Kalibrierung: Durchlaufen Sie Beispielelemente, bis die Beurteilung nicht mehr jeden Tag neue Rubrikzweige aufdeckt.
- Pilotprojekt: Labeln Sie eine schmale Warteschlange unter strenger Überprüfung.
- Evaluierung: Verlangen Sie harte Negativbeispiele im Evaluierungsdatensatz.
- Aktualisierung: Aktualisieren Sie die Rubrik und wiederholen Sie dies in einem wöchentlichen oder releasebasierten Rhythmus.
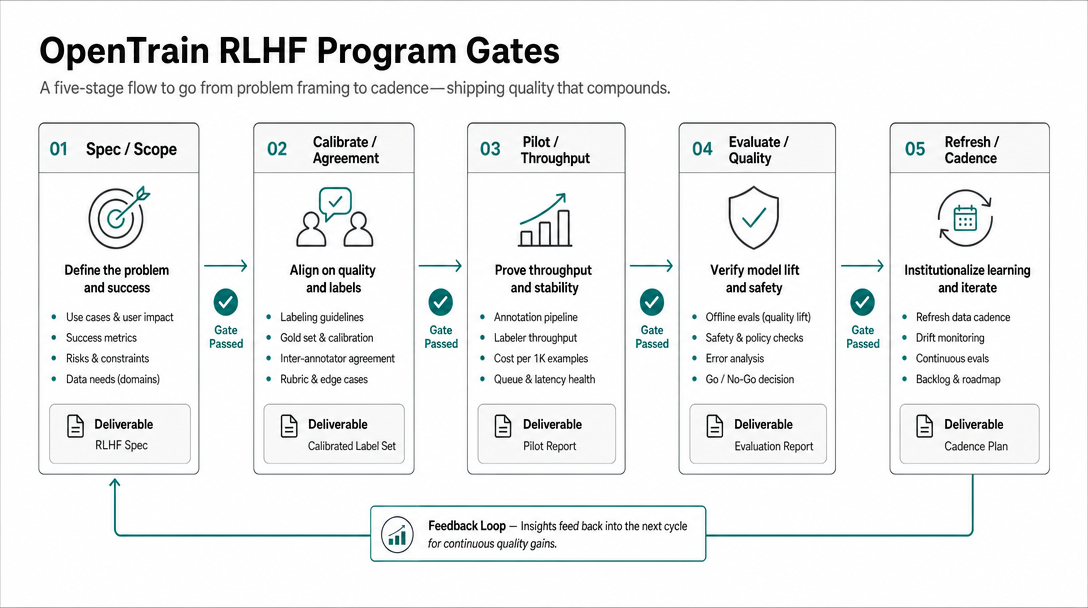
Das öffentliche Forschungsmuster unterstützt kurze Schleifen. Die frühe Arbeit von OpenAI zu menschlichen Präferenzen zog aktiv Vergleiche heran, bei denen sich das Modell unsicher war; InstructGPT verwendete separate Datensätze für Demonstrationen, Reward-Model-Training und Policy-Optimierung; die Sparrow-Arbeit von DeepMind nutzte gezielte menschliche Urteile und evidenzbasierte Evaluierung; das Paper zum Helpful-Harmless-Assistenten von Anthropic beschreibt eine iterative Online-Datenerfassung mit frischem menschlichem Feedback (OpenAI human preferences, InstructGPT, Sparrow, Anthropic HH-RLHF). Erste und zweite Programme sollten die Ablaufschleife kopieren, nicht die Datensatzgröße.
Wie ändert sich der Umfang nach dem ersten Durchlauf?
Das erste Programm sollte Lerngeschwindigkeit erkaufen. Ein ausgereiftes Programm sollte Wiederholbarkeit erkaufen. Behandeln Sie diese als unterschiedliche Investitionen.
How RLHF scope changes after the first run
| Decision | First RLHF program | Second or mature program |
|---|---|---|
| Data target | Pilot the smallest queue that exposes rubric disagreement, task friction, and obvious reward-model failure modes. | Size weekly refresh batches from observed model drift, new product surfaces, and hard-negative mining. |
| Rater pool | Start with a small calibrated group and over-invest in adjudication notes. | Maintain domain-language cells, backup capacity, reviewer promotion paths, and attrition buffers. |
| QA | Review a high share of labels until the rubric stops changing daily. | Move to sampled review, gold items, disagreement dashboards, and scheduled rubric refresh. |
| Timeline | Gate on specification, calibration, pilot, evaluation, and a first refresh decision. | Gate on weekly or release-based refresh, eval regression checks, and queue-health metrics. |
| Sourcing model | Hire directly if the team can run calibration and adjudication. Use managed service if operating the queue is the bottleneck. | Keep a stable bench, add specialists only where the model or product surface changed, and separate sourcing fees from labor rates. |
| Success artifact | A usable rubric, an eval set with misses, and a rater-capacity model. | A repeatable operating cadence with known throughput, known disagreement bands, and a clear escalation path. |
Data target
- First RLHF program
- Pilot the smallest queue that exposes rubric disagreement, task friction, and obvious reward-model failure modes.
- Second or mature program
- Size weekly refresh batches from observed model drift, new product surfaces, and hard-negative mining.
Rater pool
- First RLHF program
- Start with a small calibrated group and over-invest in adjudication notes.
- Second or mature program
- Maintain domain-language cells, backup capacity, reviewer promotion paths, and attrition buffers.
QA
- First RLHF program
- Review a high share of labels until the rubric stops changing daily.
- Second or mature program
- Move to sampled review, gold items, disagreement dashboards, and scheduled rubric refresh.
Timeline
- First RLHF program
- Gate on specification, calibration, pilot, evaluation, and a first refresh decision.
- Second or mature program
- Gate on weekly or release-based refresh, eval regression checks, and queue-health metrics.
Sourcing model
- First RLHF program
- Hire directly if the team can run calibration and adjudication. Use managed service if operating the queue is the bottleneck.
- Second or mature program
- Keep a stable bench, add specialists only where the model or product surface changed, and separate sourcing fees from labor rates.
Success artifact
- First RLHF program
- A usable rubric, an eval set with misses, and a rater-capacity model.
- Second or mature program
- A repeatable operating cadence with known throughput, known disagreement bands, and a clear escalation path.
OpenTrain scoping model.
Woran scheitern Programme normalerweise?
Die meisten Qualitätsmängel sind Messfehler. RewardBench berichtet, dass einige schwierige Teilmengen für Reward-Modelle weiterhin problematisch bleiben und dass menschliche Uneinigkeit die Zuverlässigkeit von Benchmarks einschränken kann (RewardBench). Wenn eine interne Evaluierung sofort gesättigt ist, ist sie wahrscheinlich zu einfach, um die nächste Modellaktualisierung zu steuern.
Erleichtern Sie bei faktischen und richtliniensensiblen Arbeiten dem Bewerter die Beurteilung. Sparrow fügte faktischen Behauptungen Beweise bei und bewertete Regelverstöße unter Adversarial Probing (DeepMind Sparrow blog, Sparrow paper). Für Produktionsprogramme sollte dies frühzeitig mit der LLM-Evaluierung verknüpft werden: Das Evaluierungsset sollte Beispiele enthalten, die das Modell noch immer verfehlt, und nicht nur Beispiele, die beweisen, dass das Pilotprojekt funktioniert hat.
Governance gehört zum Umfang, wenn das System ein hohes Risiko birgt oder für die Produktion bestimmt ist. Das AI RMF und das GenAI Profile des NIST sind nützliche operative Referenzen für die Dokumentation von Risiken, Messmethoden und der Nutzung von Feedback; der EU AI Act erfordert Governance-Praktiken wie technische Dokumentation, Protokollierung, menschliche Aufsicht und Robustheit für Hochrisiko-KI-Systeme (NIST AI RMF 1.0, NIST GenAI Profile, EU AI Act overview). Dies ist keine Rechtsberatung. Es ist eine Erinnerung an das Scoping: Wenn die RLHF-Pipeline einen Hochrisiko-Workflow speist, beginnt die Dokumentation in Woche eins.
Was sollte das erste Programm hinterlassen?
Ein gutes erstes RLHF-Programm hinterlässt drei wiederverwendbare Ressourcen:
- Eine Bewertungsrichtlinie, die wiederholte Beurteilungen aufgenommen hat.
- Ein Evaluierungsset mit Beispielen, die das Modell noch immer verfehlt.
- Ein Modell zur Bewerterkapazität, das das Team wöchentlich ausführen kann, ohne operative Abläufe neu erlernen zu müssen.
Wenn diese Artefakte vorhanden sind, wird die Planung des nächsten Programms günstiger. Wenn nicht, hat das Team zwar Labels gekauft, aber kein Betriebssystem.
Nächste Schritte
Quellen
- OpenAI — Learning from human preferences
- Training language models to follow instructions with human feedback
- Learning to summarize from human feedback
- Anthropic HH-RLHF Datensatz-Karte
- Training a Helpful and Harmless Assistant with RLHF
- Sparrow: Improving alignment of dialogue agents via targeted human judgements
- DeepMind — Building safer dialogue agents
- Let’s Verify Step by Step
- RewardBench
- NIST AI RMF 1.0
- NIST Generative AI Profile
- Überblick über den EU AI Act
- OpenTrain-Preise