AI Red Teaming als Evaluierungsdatenproblem

AI Red Teaming hilft, wenn adversarielle Befunde zu reproduzierbaren Evaluierungsdaten werden: Bedrohungsmodelle, Rubriken, Adjudikation, Leakage-Kontrollen und Routing.
Was ist Red Teaming bei KI eigentlich?
Wenn Sie bereits LLM-Evaluierungen durchführen, lautet die nützliche Antwort nicht „Versuch, ein Modell zu jailbreaken“. Die nützliche Antwort ist eine strukturierte gegnerische Erkundung, die Beweise liefert. KI-Red-Teaming ist dann wichtig, wenn es Ihnen hilft, bessere Evaluierungsdaten, Verweigerungstests, Schadensrubriken und Release-Entscheidungen zu entwerfen. Es ist weniger wichtig, wenn es zu einer Galerie viraler Prompts verkommt. [1]
Diese Unterscheidung ist wichtig, da das Fachgebiet mehrere verwandte Begriffe eher locker verwendet. Traditionelles Cyber-Red-Teaming ist die Emulation von Gegnern gegen die Sicherheitslage eines Unternehmens. KI-Red-Teaming ist ein strukturierter Aufwand, um Fehler und Schwachstellen in KI-Systemen zu finden, oft in Zusammenarbeit mit Entwicklern. Eine Evaluierung ist enger gefasst: Geben Sie dem System eine Eingabe, wenden Sie eine Bewertungslogik an und messen Sie, ob es das getan hat, was Ihnen wichtig ist. Sicherheitstests und TEVV vor der Bereitstellung sind breitere Oberbegriffe, die Red Teaming, Feldtests, öffentliches Feedback und formale Evaluierungen umfassen können. [1]
Wie sich KI-Red-Teaming von Cyber-Red-Teaming und Standard-Evaluierungen unterscheidet.
| Praxis | Analyseeinheit | Ziel | Typische Ausgabe | Zu vermeidende falsche Schlussfolgerung |
|---|---|---|---|---|
| Cyber Red Team | Organisation, Netzwerk, Produkt oder Sicherheitsprogramm. | Emulieren von Gegnern zur Überprüfung der Sicherheitslage. | Angriffspfad, Exploit-Narrativ, Liste der Abhilfemaßnahmen. | Eine Cyber-Übung ist nicht automatisch eine KI-Evaluierung. |
| KI Red Teaming | KI-Modell, Anwendung, Gerüst oder Bereitstellungsoberfläche. | Fehler, Schwachstellen und schädliches Verhalten aufdecken. | Ergebnisse, Prompts, Transkripte, Schweregrad-Notizen. | Ein viraler Jailbreak ist keine automatisch zuverlässige Messung. |
| Modellbewertung | Definierte Eingabe, System-Setup, Grader und Metrik. | Messen, ob ein Zielverhalten unter einem festgelegten Harness auftritt. | Scores, Labels, Konfidenzintervalle, Fehler-Slices. | Ein Bewertungs-Score stützt nur die Aussage, die sein Test-Framework auch belegen kann. |
| Sicherheitstests und TEVV | Gesamter Lebenszyklus von Nachweisen und Qualitätssicherungsmaßnahmen. | Kombination von Tests, Praxisergebnissen, Risikoschwellenwerten und Überprüfungen. | Risikoregister, Abnahmenachweise, Überwachungsplan. | Eine einzelne Red-Teaming-Runde beweist noch nicht, dass ein System sicher ist. |
Cyber Red Team
- Analyseeinheit
- Organisation, Netzwerk, Produkt oder Sicherheitsprogramm.
- Ziel
- Emulieren von Gegnern zur Überprüfung der Sicherheitslage.
- Typische Ausgabe
- Angriffspfad, Exploit-Narrativ, Liste der Abhilfemaßnahmen.
- Zu vermeidende falsche Schlussfolgerung
- Eine Cyber-Übung ist nicht automatisch eine KI-Evaluierung.
KI Red Teaming
- Analyseeinheit
- KI-Modell, Anwendung, Gerüst oder Bereitstellungsoberfläche.
- Ziel
- Fehler, Schwachstellen und schädliches Verhalten aufdecken.
- Typische Ausgabe
- Ergebnisse, Prompts, Transkripte, Schweregrad-Notizen.
- Zu vermeidende falsche Schlussfolgerung
- Ein viraler Jailbreak ist keine automatisch zuverlässige Messung.
Modellbewertung
- Analyseeinheit
- Definierte Eingabe, System-Setup, Grader und Metrik.
- Ziel
- Messen, ob ein Zielverhalten unter einem festgelegten Harness auftritt.
- Typische Ausgabe
- Scores, Labels, Konfidenzintervalle, Fehler-Slices.
- Zu vermeidende falsche Schlussfolgerung
- Ein Bewertungs-Score stützt nur die Aussage, die sein Test-Framework auch belegen kann.
Sicherheitstests und TEVV
- Analyseeinheit
- Gesamter Lebenszyklus von Nachweisen und Qualitätssicherungsmaßnahmen.
- Ziel
- Kombination von Tests, Praxisergebnissen, Risikoschwellenwerten und Überprüfungen.
- Typische Ausgabe
- Risikoregister, Abnahmenachweise, Überwachungsplan.
- Zu vermeidende falsche Schlussfolgerung
- Eine einzelne Red-Teaming-Runde beweist noch nicht, dass ein System sicher ist.
Definitionen, die aus NIST- und Modell-Evaluierungsrichtlinien synthetisiert wurden.
Das macht Demo-Jailbreaks zu einer schwachen Governance-Einheit. Das NIST warnt, dass Jailbreak- und Prompt-Engineering-Tests die Validität oder Zuverlässigkeit möglicherweise nicht systematisch bewerten. Microsoft definiert Red Teaming als eine Methode, um Schäden aufzudecken und eine Risikofläche zu verstehen, nicht als Ersatz für systematische Messungen. Das AISI vertritt aus Sicht der Evaluatoren denselben Standpunkt: Explorative Tests können auf Bedenken hinweisen, aber stärkere Aussagen erfordern eine bessere Elicitation, Bewertung und Zuordnung zwischen Ergebnissen und Risikoschwellenwerten. [2]
Das praktische Ziel ist einfach: Verwandeln Sie Entdeckungen in Fälle, die Sie wiederholen, kennzeichnen, prüfen und weiterleiten können.
Erst Bedrohungsmodell, dann Jailbreak-Galerie
Wenn ein Red-Teaming-Programm damit beginnt, Leute aufzufordern, „das Modell zu knacken“, führt das meist zu bunten Beispielen und schwachen Messergebnissen. Drehen Sie die Reihenfolge um. Beginnen Sie mit der Aussage, die durch die Beweise gestützt werden soll: Fähigkeitsermittlung, Robustheit der Sicherheitsvorkehrungen oder Vergleich zwischen Systemen unter einer gemeinsamen Konfiguration. Definieren Sie dann das Test-Framework, die Tools und das Budget, die diese Aussage aussagekräftig machen.
Die Richtlinien von OpenAI zur Evaluierung durch Dritte sind in diesem Punkt eindeutig: Ergebnisse sind nur dann interpretierbar, wenn der Bericht beschreibt, welche Behauptung der Aufbau stützt, wie das System abgefragt wurde und welche Validitätsprüfungen durchgeführt wurden. [3]
Ein Bedrohungsmodell für das Red Teaming von KI sollte den Akteur, das Zielverhalten, die Angriffsfläche und den nachgelagerten Schaden benennen. Das AISI argumentiert, dass Evaluierungen auf explizite Risikomodelle ausgerichtet sein und relevante Schadenspfade abdecken sollten. Microsoft beschreibt eine interne Ontologie, die Akteure, Taktiken, Schwachstellen und nachgelagerte Auswirkungen erfasst, da rohe Ergebnisse ohne eine gemeinsame Struktur zu unübersichtlich sind, um daraus Schlüsse zu ziehen. [4]
Für die meisten Teams sollte die „Angriffsfläche“ nicht beim Eingabefeld enden. Wenn das bereitgestellte System Retrieval, Tools, langen Kontext, multimodale Eingaben, Konnektoren oder Agenten-Gerüste nutzt, gehören diese Oberflächen zum Umfang. Das Test-Framework verändert, was das System tun kann. OpenAI betont, dass umgebende Gerüste die Leistung wesentlich verändern können, insbesondere bei agentischen Systemen. Microsoft empfiehlt ebenfalls, sowohl das Basismodell als auch die Anwendungsebene zu testen, idealerweise über die Produktions-UI, sofern möglich. [3][5]
Hier beginnt das Theater der reinen Prompt-Tests: Benutzereingaben gegen einen reduzierten Chat-Endpunkt testen und das Ergebnis dann als Beweis für ein bereitgestelltes Produkt behandeln. Dabei können indirekte Prompt-Injektionen, unsichere Tool-Nutzung, zustandsabhängige Eskalationen über mehrere Runden, Retrieval-abhängige Fehler und umgebungsspezifisches Verhalten übersehen werden. Das Problem ist nicht, dass reine Prompt-Tests nutzlos wären. Das Problem ist, sie so zu behandeln, als würden sie das gesamte System messen.
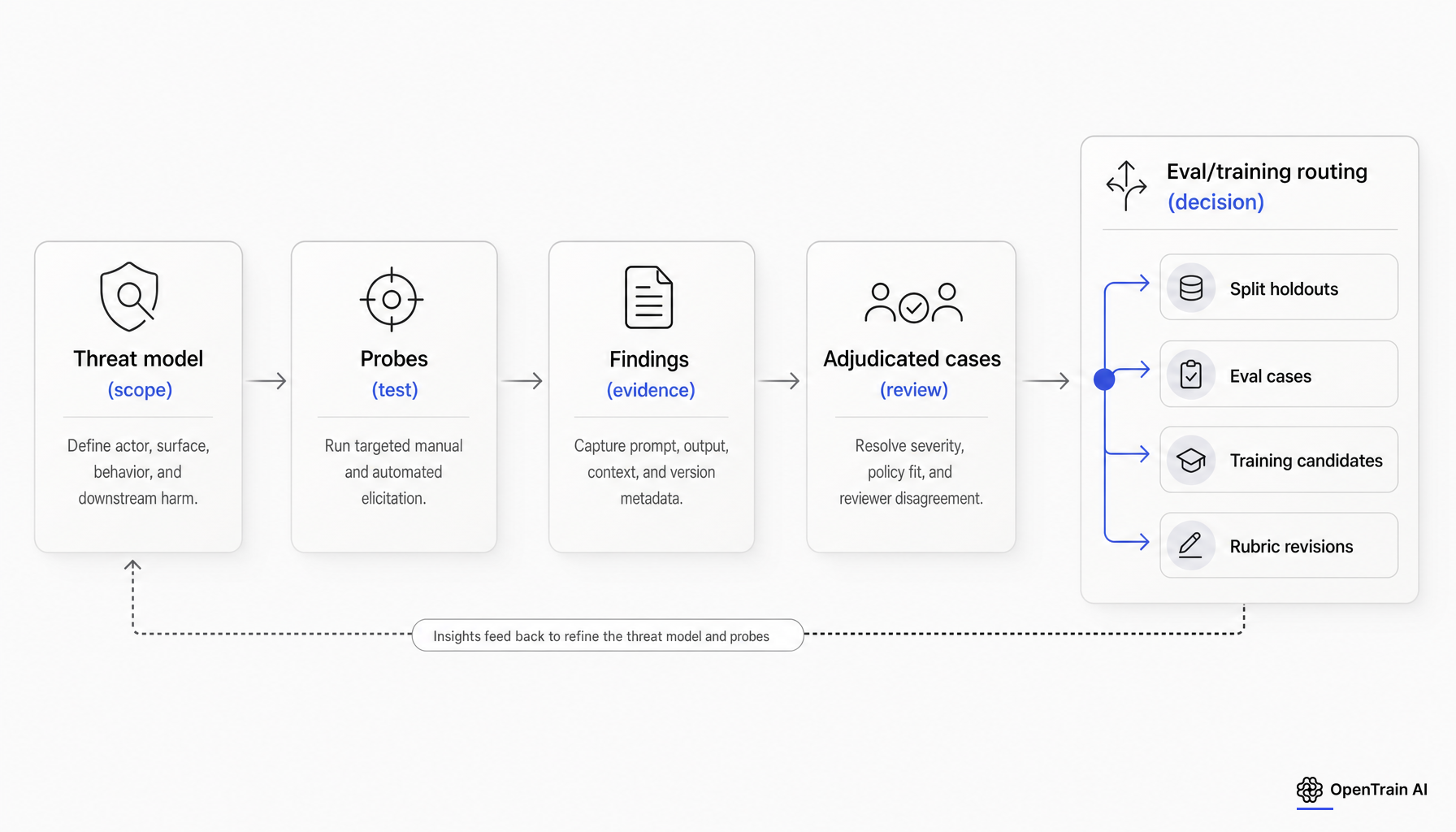
Stichproben, Schweregrad und Adjudikation
Bei der Stichprobenziehung wird aus Red Teaming ein Bewertungsdesign. Google empfiehlt vielfältige und repräsentative Eingaben über Produktrichtlinien, Anwendungsfälle, Fehlermodi, lexikalische Vielfalt und semantische Vielfalt hinweg. Microsoft empfiehlt, mit ergebnisoffenen Tests zu beginnen, um Schäden aufzudecken, und dann zu geführten Runden überzugehen, die auf einer sich entwickelnden Schadensliste basieren. In der Praxis sollte eine Stichprobe nicht aus einer öffentlichen Jailbreak-Liste plus ein paar improvisierten Prompts bestehen. Sie sollte ein geplanter Querschnitt über Schadenskategorien, Benutzerabsichten, Oberflächen, Sprachen und plausible Elicitation-Strategien sein. [6]
Auch der Schweregrad benötigt eine Struktur, bevor das Programm skaliert. Das NIST definiert Risiko als eine Kombination aus Wahrscheinlichkeit und Konsequenz. Für die Kennzeichnung durch Red-Teams ist dies ein Ausgangspunkt, kein fertiges Regelwerk. Die meisten Teams benötigen zudem Dimensionen wie Schadensart, Umsetzbarkeit, Reproduzierbarkeit, Realismus und die Frage, ob das Verhalten nach den üblichen Sicherheitsvorkehrungen bestehen bleibt. Dieses Regelwerk ist eine redaktionelle Synthese, die auf der Risikobewertung des NIST und der Bewertungspraxis basiert, nicht auf einem zitierten Standard. [2]
Adjudikation ist der Punkt, an dem Teams oft unbemerkt scheitern. Google merkt an, dass Menschen problematische Inhalte unterschiedlich bewerten können, und empfiehlt klare Richtlinien oder Vorlagen für Bewerter. OpenAI empfiehlt klare Regelwerke, Beispiel-Bewertungsstufen, Pass-Fail-Schwellenwerte und eine Konsensaggregation, wenn mehrere Prüfer eingesetzt werden. Bei Fällen mit hohem Schweregrad oder unklarer Richtlinienlage sollte menschliche Uneinigkeit als Signal für das Messsystem behandelt werden, nicht nur als Rauschen der Annotatoren. [6][7]
Eine nützliche Arbeitsregel lautet: Wenn ein Befund einen hohen Schweregrad aufweist, richtlinienunklar oder fachspezifisch ist, sollte er von der Einzelprüfung zur Experten-Adjudikation eskaliert werden. Wenn sich Prüfer uneinig darüber sind, ob das Modell gegen Richtlinien verstoßen hat, sollte der Fall in der Regel zu einer Überarbeitung des Regelwerks führen, bevor er das Post-Training beeinflusst. Diese Empfehlung ist eine Synthese, folgt jedoch den zitierten Leitlinien zu Klarheit, Kalibrierung und menschlicher Überprüfung des Regelwerks.
Menschliche und automatisierte Arbeit gezielt aufteilen
Automatisierung hilft vor allem dann, wenn es um Breite, Aktualisierung und die Erkennung schwacher Signale geht. Die Arbeit von Anthropic zu modellgeschriebenen Evaluierungen hat gezeigt, dass Modelle dabei helfen können, schnell viele relevante Evaluierungselemente zu generieren, wobei in diesem Umfeld eine hohe Übereinstimmung der Crowdworker bei den Labels erzielt wurde. Das AISI argumentiert, dass automatisierte Fähigkeitsbewertungen skalierbar genug sind, um einen großen Teil der relevanten Fähigkeitsbereiche abzudecken. Google empfiehlt ebenfalls, mit Seed-Beispielen zu beginnen und diese synthetisch zu erweitern, wenn bestehende Datensätze nicht ausreichen. [8][4][6]
Dieselben Quellen definieren auch die Grenzen. Das AISI gibt an, dass automatisierte Tests die reale Nutzung nicht widerspiegeln und daher nicht allein als Grundlage für weitreichende Schlussfolgerungen dienen sollten. Google warnt, dass die Genauigkeit von Klassifikatoren bei vage definierten Konstrukten gering sein kann. OpenAI betont, dass Evaluierungen mehr als nur Scores umfassen und empfiehlt, die automatisierte Bewertung anhand menschlicher Urteile zu kalibrieren. [4][6][7]
Automatisierte Sonden sind in drei Bereichen stark. Erstens verbessern sie die Abdeckung, indem sie mehr lexikalische und semantische Varianten generieren, als ein kleines menschliches Team produzieren könnte. Zweitens machen sie Regressionstests kostengünstig, sobald ein Fall zu einer wiederverwendbaren Evaluierung wird. Drittens ermöglichen sie es Teams, ein System durch wiederholtes Sampling in großem Maßstab anzugreifen, was wichtig ist, da sich einige Jailbreak-Klassen mit mehr Versuchen verbessern. Die Many-Shot-Arbeit von Anthropic ist ein Beispiel dafür, wie langer Kontext neue Fehlermodi erzeugt. [9]
Die Tooling-Landschaft spiegelt diese Arbeitsteilung mittlerweile wider. Microsoft PyRIT ist ein modellunabhängiges Framework zur Untersuchung multimodaler Systeme und zur Wiederverwendung modularer Red-Teaming-Bausteine. AISI Inspect unterstützt mehrstufige Dialoge, Agenten-Gerüste, Modellbewertungen und detaillierte Protokolle. Diese Tools sind nützlich, da Red-Teaming-Ergebnisse zu analysierbaren Evaluierungsartefakten werden müssen und nicht nur lose Notizen bleiben dürfen. [10][11]
Menschen bleiben dort notwendig, wo die Frage nicht nur lautet: „Hat die Richtlinie versagt?“, sondern „Was ist hier tatsächlich von Bedeutung?“. Microsoft ist direkt: Medizin, Cybersicherheit, CBRN, interkulturelle Schäden und psychosoziale Schäden erfordern fachliches Urteilsvermögen. Das AISI beschreibt Experten-Red-Teaming ähnlich als natürlicher und offener als automatisierte Tests. [12][4]
LLM-Richter erfordern dieselbe Skepsis. OpenAI empfiehlt paarweise oder Pass-Fail-Formate, klare Rubriken und eine Validierung anhand menschlicher Labels, da Richter-Modelle durch Antwortreihenfolge und Antwortlänge beeinflusst werden können. Verwenden Sie LLM-Richter wie Messinstrumente: Kalibrieren Sie sie, prüfen Sie auf Drift und führen Sie regelmäßige Audits durch. Übertragen Sie ihnen nicht die endgültige Autorität bei spezialisierten Schäden oder mehrdeutigen Richtliniengrenzen. [7]
Wo Automatisierung hilft und wo Menschen weiterhin wichtig sind.
| Methode | Beste Verwendung | Hauptvorteil | Hauptblinder Fleck | Menschliche Überprüfung erforderlich? |
|---|---|---|---|---|
| Automatisierte Sonden | Breite, wiederholte Versuche über bekannte Taktiken hinweg. | Skaliert Abdeckung und Aktualisierungsfrequenz. | Kann realistischen Produktkontext und domänenspezifische Schäden übersehen. | Ja, bei schwerwiegenden oder mehrdeutigen Fällen. |
| Modellgenerierte Varianten | Erweiterung von Seed-Beispielen hinsichtlich Wortwahl und Semantik. | Findet lexikalische und semantische Nachbarn schnell. | Kann zu Overfitting bei einfachen Variationen führen. | Ja, für Label-Kalibrierung und Neuheitsprüfungen. |
| Klassifikatoren | Vorabprüfung großer Ausgabemengen. | Kostengünstige Triage und Überwachung. | Geringe Genauigkeit bei lockeren Konstrukten. | Ja, für Richtlinien- und Schweregradentscheidungen. |
| LLM Richter | Bestanden/Nicht-bestanden oder paarweise Bewertung mit klaren Rubriken. | Schnelle, wiederverwendbare Bewertung bei Kalibrierung. | Reihenfolge, Länge, Stil und domänenspezifische Verzerrung. | Ja, mit regelmäßigen menschlichen Audits. |
| Skriptbasierte Regressions-Suiten | Erneutes Ausführen bekannter Fälle nach Modell- oder Richtlinienänderungen. | Stabile Wiedergabe und Diffing. | Misst die Fehlerquellen von gestern. | Ja, wenn Regressionen ein hohes Risiko darstellen. |
| Menschliche Fachexperten | Medizin, Sicherheit, CBRN, kulturelle, rechtliche oder psychosoziale Schäden. | Kontext- und Konsequenzbeurteilung. | Begrenzter Durchsatz und Uneinigkeit ohne Bewertungsrichtlinien. | Sie bilden den Überprüfungspfad. |
Automatisierte Sonden
- Beste Verwendung
- Breite, wiederholte Versuche über bekannte Taktiken hinweg.
- Hauptvorteil
- Skaliert Abdeckung und Aktualisierungsfrequenz.
- Hauptblinder Fleck
- Kann realistischen Produktkontext und domänenspezifische Schäden übersehen.
- Menschliche Überprüfung erforderlich?
- Ja, bei schwerwiegenden oder mehrdeutigen Fällen.
Modellgenerierte Varianten
- Beste Verwendung
- Erweiterung von Seed-Beispielen hinsichtlich Wortwahl und Semantik.
- Hauptvorteil
- Findet lexikalische und semantische Nachbarn schnell.
- Hauptblinder Fleck
- Kann zu Overfitting bei einfachen Variationen führen.
- Menschliche Überprüfung erforderlich?
- Ja, für Label-Kalibrierung und Neuheitsprüfungen.
Klassifikatoren
- Beste Verwendung
- Vorabprüfung großer Ausgabemengen.
- Hauptvorteil
- Kostengünstige Triage und Überwachung.
- Hauptblinder Fleck
- Geringe Genauigkeit bei lockeren Konstrukten.
- Menschliche Überprüfung erforderlich?
- Ja, für Richtlinien- und Schweregradentscheidungen.
LLM Richter
- Beste Verwendung
- Bestanden/Nicht-bestanden oder paarweise Bewertung mit klaren Rubriken.
- Hauptvorteil
- Schnelle, wiederverwendbare Bewertung bei Kalibrierung.
- Hauptblinder Fleck
- Reihenfolge, Länge, Stil und domänenspezifische Verzerrung.
- Menschliche Überprüfung erforderlich?
- Ja, mit regelmäßigen menschlichen Audits.
Skriptbasierte Regressions-Suiten
- Beste Verwendung
- Erneutes Ausführen bekannter Fälle nach Modell- oder Richtlinienänderungen.
- Hauptvorteil
- Stabile Wiedergabe und Diffing.
- Hauptblinder Fleck
- Misst die Fehlerquellen von gestern.
- Menschliche Überprüfung erforderlich?
- Ja, wenn Regressionen ein hohes Risiko darstellen.
Menschliche Fachexperten
- Beste Verwendung
- Medizin, Sicherheit, CBRN, kulturelle, rechtliche oder psychosoziale Schäden.
- Hauptvorteil
- Kontext- und Konsequenzbeurteilung.
- Hauptblinder Fleck
- Begrenzter Durchsatz und Uneinigkeit ohne Bewertungsrichtlinien.
- Menschliche Überprüfung erforderlich?
- Sie bilden den Überprüfungspfad.
Basierend auf der AISI-Klassifizierung, Googles Adversarial Testing, OpenAI-Evaluierungspraktiken, Anthropic-Modell-Evaluierungen und den Erkenntnissen aus dem Microsoft Red Teaming.
Eine gute operative Aufteilung ist einfach. Lassen Sie die Automatisierung Angriffs-Kandidaten generieren, Seed-Sets erweitern, offensichtliche Fälle vorab kennzeichnen, Duplikate gruppieren und Regressionen erneut ausführen. Lassen Sie Menschen die Schadensliste definieren, unsichere oder schwerwiegende Fälle überprüfen, die Qualität der Beurteilung prüfen und interpretieren, was das Systemversagen für das Produkt oder das Modell bedeutet. Diese Aufteilung ist eine Synthese, die auf den oben genannten Quellen basiert.
Behandeln Sie Ergebnisse als Datenobjekte, nicht als Anekdoten
Wenn Red-Team-Ausgaben zu wiederverwendbaren Evaluierungsdaten werden sollen, erfassen Sie mehr als nur den Prompt und die endgültige Antwort. Microsoft empfiehlt, mindestens das Datum des Auftretens, eine eindeutige Kennung, den Eingabe-Prompt und die Ausgabedetails aufzuzeichnen. Google empfiehlt, Ausgaben in Fehlermodi und Schäden zu unterteilen. Das Log-Modell von Inspect zeigt, was eine ausgereiftere Darstellung bewahren kann: Eingabe, Beispiel-Metadaten, Bewertungen, Fehler, Nachrichten und Ereignisprotokolle auf mehreren Granularitätsebenen. [5][6][11]
Für angewandte Teams ist das minimal nützliche Schema meist umfangreicher. Behalten Sie zusätzlich zu Prompt und Antwort die Modellversion, die System-Prompt-Version oder den Hash, die Tool-Konfiguration, den Abrufkontext oder Referenzen, die Angriffsmethode, die Richtlinienkategorie, den Verweigerungsstatus, das Label des Prüfers, das Schweregrad-Label, die Begründung, den Adjudikationsstatus, das Fall-Cluster und den Routing-Status bei. Diese genaue Feldliste ist eine Synthese, stellt jedoch eine praktische Erweiterung der aktuellen Leitlinien zur strukturierten Erfassung, Metadaten und Bewertung dar.
Der Umgang mit Duplikaten ist wichtiger, als die meisten Teams erwarten. Google empfiehlt, bei der Generierung von gegnerischen Datensätzen Duplikate und verrauschte Beispiele mit mehreren Labels zu vermeiden. Ohne Deduplizierung fallen “Top-Fehlermodi” oft in einige wenige virale Angriffsvorlagen zusammen, die dann sowohl die Minderungsarbeit als auch die Trainingsdaten verzerren. Behalten Sie ein Konzept von kanonischen Fällen gegenüber Paraphrasen-Clustern bei und berichten Sie sowohl die Rohanzahl als auch die Anzahl der eindeutigen Angriffsfamilien. Die Empfehlung für kanonische gegenüber Cluster-Fällen ist eine Synthese, aber die Notwendigkeit von Einzigartigkeit und sorgfältiger Zusammenstellung stammt direkt aus den Leitlinien von Google. [6]
Ein wiederverwendbares Red-Team-Fallschema für Evaluierungs- und Post-Training-Schleifen.
| Feld | Warum es wichtig ist | Training-sicher? | Holdout-sicher? | Anmerkungen |
|---|---|---|---|---|
| Fall-ID | Hält Überprüfung, erneute Ausführungen und Korrekturen nachvollziehbar. | Ja | Ja | Stabile IDs sollten Paraphrasierungs-Clustering überstehen. |
| Prompt/Eingabe | Definiert das Elicitation-Artefakt. | Manchmal | Ja | Exakte Holdout-Prompts sollten später nicht zu Trainingsbeispielen werden. |
| Modellausgabe | Erfasst das beobachtete Verhalten. | Manchmal | Ja | Beinhaltet Verweigerungen, teilweise Vervollständigungen und Tool-Ausgaben. |
| Modellversion | Verhindert falsche Vergleiche zwischen sich ändernden Systemen. | Ja | Ja | Modell, Checkpoint und relevanten Release-Kanal erfassen. |
| System-Prompt-Hash | Verknüpft Verhalten mit Anweisungen, ohne Geheimnisse preiszugeben. | Ja | Ja | Verwenden Sie Hashes oder kontrollierte Referenzen, wenn Prompts sensibel sind. |
| Tool-/Abrufkontext | Zeigt, was das bereitgestellte Harness zur Verfügung gestellt hat. | Manchmal | Ja | Kritisch für RAG, Tool-Nutzung, langen Kontext und Agententests. |
| Angriffsmethode | Unterstützt Abdeckung und Deduplizierung. | Ja | Ja | Beispiele sind direkte Jailbreaks, indirekte Injektionen, Rollenspiele oder mehrstufige Eskalationen. |
| Richtlinienkategorie | Verknüpft das Ergebnis mit der Rubrik. | Ja | Ja | Überarbeiten Sie die Kategorien, wenn die Beurteilung Unklarheiten aufdeckt. |
| Ablehnungsstatus | Unterscheidet zwischen unsicherer Compliance und Überverweigerung. | Ja | Ja | Fassen Sie nicht alle Verweigerungen als Erfolg zusammen. |
| Prüfer-Label | Definiert die Entscheidung durch einen Menschen oder einen kalibrierten Bewerter. | Ja | Ja | Prüfertyp und Kalibrierungsstatus nachverfolgen. |
| Schweregrad | Priorisiert die Fehlerbehebung und Release-Gates. | Ja | Ja | Schweregrad-Dimensionen sind eine Synthese, kein universeller Standard. |
| Begründung | Ermöglicht spätere Audits. | Ja | Ja | Kurze Begründungen sind besser als undurchsichtige Klassenbezeichnungen. |
| Adjudication-Status | Unterscheidet zwischen Einzelbewertungen und geklärten Fällen. | Ja | Ja | Fälle mit hohem Schweregrad und strittige Fälle erfordern eine Eskalation. |
| Cluster-ID | Verhindert, dass doppelte Prompts Berichte dominieren. | Ja | Ja | Rohanzahl und Anzahl der eindeutigen Angriffsfamilien separat melden. |
| Routing-Status | Verhindert Datenlecks zwischen Training und Messung. | Ja, bei Routing zum Training | Ja, wenn als Holdout gesperrt | Zu den möglichen Zuständen gehören Trainingskandidat, Evaluierungsfall, gesperrtes Holdout, Überarbeitung der Richtlinien oder Freigabenachweis. |
Fall-ID
- Warum es wichtig ist
- Hält Überprüfung, erneute Ausführungen und Korrekturen nachvollziehbar.
- Training-sicher?
- Ja
- Holdout-sicher?
- Ja
- Anmerkungen
- Stabile IDs sollten Paraphrasierungs-Clustering überstehen.
Prompt/Eingabe
- Warum es wichtig ist
- Definiert das Elicitation-Artefakt.
- Training-sicher?
- Manchmal
- Holdout-sicher?
- Ja
- Anmerkungen
- Exakte Holdout-Prompts sollten später nicht zu Trainingsbeispielen werden.
Modellausgabe
- Warum es wichtig ist
- Erfasst das beobachtete Verhalten.
- Training-sicher?
- Manchmal
- Holdout-sicher?
- Ja
- Anmerkungen
- Beinhaltet Verweigerungen, teilweise Vervollständigungen und Tool-Ausgaben.
Modellversion
- Warum es wichtig ist
- Verhindert falsche Vergleiche zwischen sich ändernden Systemen.
- Training-sicher?
- Ja
- Holdout-sicher?
- Ja
- Anmerkungen
- Modell, Checkpoint und relevanten Release-Kanal erfassen.
System-Prompt-Hash
- Warum es wichtig ist
- Verknüpft Verhalten mit Anweisungen, ohne Geheimnisse preiszugeben.
- Training-sicher?
- Ja
- Holdout-sicher?
- Ja
- Anmerkungen
- Verwenden Sie Hashes oder kontrollierte Referenzen, wenn Prompts sensibel sind.
Tool-/Abrufkontext
- Warum es wichtig ist
- Zeigt, was das bereitgestellte Harness zur Verfügung gestellt hat.
- Training-sicher?
- Manchmal
- Holdout-sicher?
- Ja
- Anmerkungen
- Kritisch für RAG, Tool-Nutzung, langen Kontext und Agententests.
Angriffsmethode
- Warum es wichtig ist
- Unterstützt Abdeckung und Deduplizierung.
- Training-sicher?
- Ja
- Holdout-sicher?
- Ja
- Anmerkungen
- Beispiele sind direkte Jailbreaks, indirekte Injektionen, Rollenspiele oder mehrstufige Eskalationen.
Richtlinienkategorie
- Warum es wichtig ist
- Verknüpft das Ergebnis mit der Rubrik.
- Training-sicher?
- Ja
- Holdout-sicher?
- Ja
- Anmerkungen
- Überarbeiten Sie die Kategorien, wenn die Beurteilung Unklarheiten aufdeckt.
Ablehnungsstatus
- Warum es wichtig ist
- Unterscheidet zwischen unsicherer Compliance und Überverweigerung.
- Training-sicher?
- Ja
- Holdout-sicher?
- Ja
- Anmerkungen
- Fassen Sie nicht alle Verweigerungen als Erfolg zusammen.
Prüfer-Label
- Warum es wichtig ist
- Definiert die Entscheidung durch einen Menschen oder einen kalibrierten Bewerter.
- Training-sicher?
- Ja
- Holdout-sicher?
- Ja
- Anmerkungen
- Prüfertyp und Kalibrierungsstatus nachverfolgen.
Schweregrad
- Warum es wichtig ist
- Priorisiert die Fehlerbehebung und Release-Gates.
- Training-sicher?
- Ja
- Holdout-sicher?
- Ja
- Anmerkungen
- Schweregrad-Dimensionen sind eine Synthese, kein universeller Standard.
Begründung
- Warum es wichtig ist
- Ermöglicht spätere Audits.
- Training-sicher?
- Ja
- Holdout-sicher?
- Ja
- Anmerkungen
- Kurze Begründungen sind besser als undurchsichtige Klassenbezeichnungen.
Adjudication-Status
- Warum es wichtig ist
- Unterscheidet zwischen Einzelbewertungen und geklärten Fällen.
- Training-sicher?
- Ja
- Holdout-sicher?
- Ja
- Anmerkungen
- Fälle mit hohem Schweregrad und strittige Fälle erfordern eine Eskalation.
Cluster-ID
- Warum es wichtig ist
- Verhindert, dass doppelte Prompts Berichte dominieren.
- Training-sicher?
- Ja
- Holdout-sicher?
- Ja
- Anmerkungen
- Rohanzahl und Anzahl der eindeutigen Angriffsfamilien separat melden.
Routing-Status
- Warum es wichtig ist
- Verhindert Datenlecks zwischen Training und Messung.
- Training-sicher?
- Ja, bei Routing zum Training
- Holdout-sicher?
- Ja, wenn als Holdout gesperrt
- Anmerkungen
- Zu den möglichen Zuständen gehören Trainingskandidat, Evaluierungsfall, gesperrtes Holdout, Überarbeitung der Richtlinien oder Freigabenachweis.
Die Feldliste kombiniert Tool-Dokumentation und operative Anleitungen; das Routing für Training/Holdout ist eine redaktionelle Synthese.
Entscheiden Sie, was aus jedem Ergebnis wird, bevor Sie damit trainieren
Dies ist die zentrale operative Frage, und die Antwort sollte vor dem ersten Meeting nach dem Training schriftlich festgehalten werden.
Ein Red-Team-Fall kann mindestens fünf verschiedene Dinge werden: ein Trainingsbeispiel, ein wiederverwendbarer Evaluierungsfall, ein gesperrtes Holdout, eine Überarbeitung von Richtlinien oder Rubriken oder ein Nachweis für die Freigabe. Aktuelle Primärquellen unterstützen die Notwendigkeit dieser getrennten Wege, auch wenn sie diese nicht in einem Standard-Workflow zusammenfassen. OpenAI warnt davor, Evaluierungsdaten in das Reinforcement Fine-Tuning einfließen zu lassen, beschreibt produktionsbasierte Evaluierungen, die regelmäßig aktualisiert werden, und betont Validitätsrisiken wie Kontamination und Reward Hacking. AISI argumentiert ähnlich für vordefinierte Schwellenwerte und wiederholte Tests über den gesamten Modelllebenszyklus hinweg. [13][14][3][4]
Ein Fall ist ein sinnvoller Trainingskandidat, wenn das Label stabil ist, der Fehler repräsentativ für die realistische Nutzung ist, die Richtliniengrenze klar ist und das Beispiel nicht für zukünftige Messungen reserviert ist. Die frühere Red-Teaming-Arbeit von Anthropic ergab, dass die Verwendung von Red-Team-Daten in Sicherheitsmethoden die Anfälligkeit gegenüber dem untersuchten Angriffskorpus verringerte. Deshalb sind Teams versucht, mit allem zu trainieren. Deshalb ist auch die Kontrolle von Leckagen wichtig: Wenn dieselben Fälle später als Fortschrittsnachweis verwendet werden, ist die Messung kompromittiert. [15]
Halten Sie einen Fall aus dem Training heraus, wenn er als Holdout benötigt wird, wenn er einem öffentlichen Benchmark oder einem wahrscheinlichen zukünftigen Benchmark ähnelt, wenn das Label umstritten ist oder wenn der Exploit so fallspezifisch ist, dass ein Training damit das Modell hauptsächlich dazu bringen würde, einen Patch auswendig zu lernen. Die Notiz von Anthropic zur BrowseComp-Kontamination zeigt, wie öffentliche Leckagen Ergebnisse verfälschen können, und die Analyse von OpenAI zu SWE-bench Verified zeigt dasselbe Fehlermuster auf Benchmark-Ebene. In beiden Fällen ist die Lektion dieselbe: Dasselbe Artefakt kann nicht gleichzeitig Trainingsmaterial und ehrlicher Messnachweis sein. [16][17]
Praktische Routing-Regel: Wenn ein Fall einen neuartigen Fehlermodus aufgedeckt hat, blockieren Sie ihn zuerst in einem Holdout-Bucket. Erst nachdem Sie das Holdout aktualisiert und die Korrektur an neuen Fällen nachgewiesen haben, sollten Sie in Erwägung ziehen, Varianten dieses Fehlermusters in das Training zu übernehmen. Diese Regel ist eine Synthese, respektiert jedoch die aktuellen Richtlinien zur Datenleckvermeidung von Anbieter- und Evaluierungsquellen.
Ein Betriebsmodell für kleine Teams, das nicht vorgibt, Sicherheit zu garantieren
Für ein kleines KI-Team besteht das Ziel nicht darin, „alles abzudecken“. Das Ziel ist es, einen Kreislauf zu schaffen, der Nachweise produziert, denen Sie auch nach Änderungen am Modell noch vertrauen.
Beginnen Sie mit einem konkreten, für den Einsatz relevanten Bedrohungsmodell, einer eng gefassten Produktoberfläche und einer manuellen Entdeckungsrunde. Nutzen Sie nach Möglichkeit verschiedene Tester, aber beziehen Sie mindestens jemanden ein, der den Schaden im Fachbereich versteht, und jemanden, der adversariell über die Systemschnittstelle nachdenken kann. Microsoft empfiehlt diverse Tester und explizite Zuweisungen zu Schäden oder Funktionen; Google empfiehlt, mit Startbeispielen zu beginnen und diese sorgfältig zu erweitern; OpenAI empfiehlt, frühzeitig Evaluierungen zu erstellen, alles zu protokollieren und die Automatisierung mit menschlichen Labels zu kalibrieren. [5][6][7]
Frieren Sie dann die erste Tranche der Ergebnisse mit hoher Konfidenz in einem zurückgehaltenen adversariellen Evaluierungsset ein. Führen Sie kein Fine-Tuning mit genau diesen Fällen durch. Erstellen Sie einfache Regressionsläufe um sie herum, auch wenn der Bewerter nur mit Bestehen/Nichtbestehen und menschlicher Prüfung arbeitet. Sobald das funktioniert, fügen Sie eine zweite Spur für Trainingskandidaten hinzu und halten Sie die Trennung sauber. Die Evaluierungsrichtlinien von OpenAI betonen wiederholt zurückgehaltene Daten, Nicht-Überschneidungen und separate Trainingssets für Post-Training-Schleifen. [13][7]
Danach lohnt sich der Aufwand für die Automatisierung. Nutzen Sie modellgenerierte Erweiterungen, Klassifikatoren oder LLM-Bewerter, um die Abdeckung zu erweitern und die Überprüfungskosten zu senken, aber nur in Bereichen, in denen Sie festgelegt haben, was ein korrektes Label bedeutet. Der gestufte Ansatz von AISI ist eine nützliche Vorlage: Lassen Sie leichtere automatisierte Tests schnell Bedenken finden und eskalieren Sie dann zu maßgeschneiderter Elicitation und Expertenprüfung, wenn das Signal wichtig ist. [4]
Nichts davon beweist, dass ein System sicher ist. Das ist das falsche Versprechen. Ein guter Red-Team-Loop liefert Ihnen Fälle, die Sie erneut abspielen können, Labels, die Sie verteidigen können, Holdouts, mit denen Sie nicht trainiert haben, und genügend Struktur, um festzustellen, ob eine Risikominderung das Modell tatsächlich verändert hat oder nur einen Demo-Prompt korrigiert hat.
OpenTrain kann Teams dabei unterstützen, Red-Teamer, Fachgutachter und Bewertungsspezialisten für diese Arbeit einzustellen. Nutzen Sie die LLM-Referenz zur Zuverlässigkeit von Judges für die Kalibrierung von Evaluatoren, den Leitfaden zu RLAIF vs. RLHF für die Grenzen der Automatisierung, die Referenz zu PRM vs. ORM für das Design von Messzielen und den RLHF-Leitfaden zur Bereichsabgrenzung für die Planung von Review-Loops. Wenn der Engpass in der Besetzung des Review-Loops liegt, schalten Sie eine Stellenanzeige.
Quellen
- NIST-Glossar: Red Team; NIST-Glossar: Artificial Intelligence Red-Teaming; NIST AI RMF Generative AI Profile
- NIST AI RMF Generative AI Profile
- OpenAI: Trustworthy third-party evaluations foundations
- AISI: Early lessons from evaluating frontier AI systems
- Microsoft Learn: Planning red teaming for LLMs
- Google: Adversarial Testing for Generative AI
- OpenAI: Evaluation best practices
- Anthropic: Entdeckung von Sprachmodell-Verhaltensweisen mit modellgeschriebenen Bewertungen
- Anthropic: Many-shot Jailbreaking
- PyRIT: Ein Framework zur Identifizierung von Sicherheitsrisiken und Red Teaming in generativen KI-Systemen
- Inspect AI Dokumentation
- Microsoft Research: Lektionen aus dem Red Teaming von 100 generativen KI-Produkten; Zusammenfassung im Microsoft Security Blog
- OpenAI Cookbook: Eval-gesteuertes Systemdesign
- OpenAI: Produktionsbewertungen
- Anthropic: Red Teaming von Sprachmodellen zur Schadensreduzierung
- Anthropic: Eval awareness und BrowseComp
- OpenAI: Warum wir SWE-bench Verified nicht mehr zur Evaluierung nutzen