Optimización Directa de Preferencias vs. PPO después de RLHF

Una referencia técnica sobre lo que cambia DPO después de RLHF, dónde PPO y los datos en línea siguen importando, y por qué medir preferencias sigue siendo difícil.
La Optimización Directa de Preferencias no reemplazó a RLHF en su totalidad. Reemplazó una gran parte de lo que muchos equipos asociaban con RLHF: entrenar un modelo de recompensa explícito y luego ejecutar PPO contra él. La interpretación más sólida es más precisa y más útil. DPO simplifica la optimización mucho más de lo que simplifica la medición.
Cuando los datos de preferencia fuera de línea tienen una cobertura débil, cuando los jueces están sesgados, cuando los modelos de recompensa generalizan mal o cuando las etiquetas tienen ruido, el bucle PPO faltante no es el problema central. El problema central es si el objetivo de preferencia medido se transfiere al comportamiento que realmente le importa al equipo (DPO, InstructGPT, helpful-harmless RLHF).
El objetivo cambia, pero la carga de la prueba no
RLHF al estilo PPO y DPO son diferentes interfaces de optimización para objetivos relacionados con el aprendizaje de preferencias. Ninguno de los dos demuestra que los datos subyacentes o el conjunto de evaluadores sean lo suficientemente buenos.
En el RLHF clásico basado en PPO, la política se optimiza frente a una recompensa aprendida mientras se mantiene cerca de una política de referencia:
DPO, en cambio, optimiza una pérdida por pares sobre respuestas elegidas y rechazadas, con el modelo de referencia aún presente como ancla:
Esa sustitución es real. Elimina el entrenamiento explícito del modelo de recompensa como requisito previo para la optimización de la política, elimina las consultas de recompensa en tiempo de despliegue durante el ajuste fino y evita la maquinaria separada de función de valor y gradiente de política de PPO. No elimina la dependencia de los datos de preferencia por pares, el ancla de la política de referencia ni la evaluación de transferencia.
DPO elimina el trabajo explícito de entrenamiento de modelo de recompensa más PPO, pero no los datos calibrados, los diagnósticos de jueces ni la evaluación de transferencia.
| Capa | RLHF en la era PPO | Enfoque de la familia DPO | Qué todavía debe medirse | Por qué sigue siendo difícil |
|---|---|---|---|---|
| Modelo de recompensa | Entrenar un modelo de recompensa explícito antes de PPO. | Representar la relación de recompensa de forma implícita en la pérdida por pares. | Validez de las etiquetas de preferencia. | Las etiquetas ruidosas o estrechas siguen optimizando la señal equivocada. |
| Optimización de la política | Ejecutar PPO con maquinaria de valor y gradiente de política. | Optimizar un objetivo offline anclado a una referencia. | Transferencia al comportamiento de despliegue. | Los datos offline pueden pasar por alto errores de la política actual. |
| Datos on-policy | Puede recopilar nuevos datos de preferencia durante las iteraciones. | A menudo parte de datos de comparación fijos. | Cobertura de los segmentos objetivo. | Los datos estáticos no cubren comportamientos nuevos por defecto. |
| Pila de evaluación | Se usa para entrenar el modelo de recompensa y aportar evidencia de lanzamiento. | A menudo desplaza más confianza hacia jueces o datos fijos. | Sesgo y confiabilidad del juez. | Siguen existiendo fallas por posición, verbosidad y perturbaciones. |
| Transferencia al conjunto de reserva | Benchmarks y comprobaciones posteriores después de PPO. | Benchmarks y comprobaciones posteriores después de DPO. | Prompts no vistos y linaje de la política. | El ranking en benchmarks es útil, pero insuficiente. |
Modelo de recompensa
- RLHF en la era PPO
- Entrenar un modelo de recompensa explícito antes de PPO.
- Enfoque de la familia DPO
- Representar la relación de recompensa de forma implícita en la pérdida por pares.
- Qué todavía debe medirse
- Validez de las etiquetas de preferencia.
- Por qué sigue siendo difícil
- Las etiquetas ruidosas o estrechas siguen optimizando la señal equivocada.
Optimización de la política
- RLHF en la era PPO
- Ejecutar PPO con maquinaria de valor y gradiente de política.
- Enfoque de la familia DPO
- Optimizar un objetivo offline anclado a una referencia.
- Qué todavía debe medirse
- Transferencia al comportamiento de despliegue.
- Por qué sigue siendo difícil
- Los datos offline pueden pasar por alto errores de la política actual.
Datos on-policy
- RLHF en la era PPO
- Puede recopilar nuevos datos de preferencia durante las iteraciones.
- Enfoque de la familia DPO
- A menudo parte de datos de comparación fijos.
- Qué todavía debe medirse
- Cobertura de los segmentos objetivo.
- Por qué sigue siendo difícil
- Los datos estáticos no cubren comportamientos nuevos por defecto.
Pila de evaluación
- RLHF en la era PPO
- Se usa para entrenar el modelo de recompensa y aportar evidencia de lanzamiento.
- Enfoque de la familia DPO
- A menudo desplaza más confianza hacia jueces o datos fijos.
- Qué todavía debe medirse
- Sesgo y confiabilidad del juez.
- Por qué sigue siendo difícil
- Siguen existiendo fallas por posición, verbosidad y perturbaciones.
Transferencia al conjunto de reserva
- RLHF en la era PPO
- Benchmarks y comprobaciones posteriores después de PPO.
- Enfoque de la familia DPO
- Benchmarks y comprobaciones posteriores después de DPO.
- Qué todavía debe medirse
- Prompts no vistos y linaje de la política.
- Por qué sigue siendo difícil
- El ranking en benchmarks es útil, pero insuficiente.
Síntesis de OpenTrain a partir de DPO, InstructGPT, Anthropic RLHF, teoría de cobertura, RewardBench 2 y las recetas públicas de post-entrenamiento citadas en este artículo.
Lo que DPO realmente elimina
DPO elimina el entrenamiento explícito del modelo de recompensa de la ruta de ajuste de preferencias y elimina la optimización de gradiente de política en línea al estilo PPO de esa fase. En términos de ingeniería, eso significa menos piezas móviles, menor complejidad de implementación, menos fragilidad de hiperparámetros y menos formas de que el colapso del modelo de recompensa o la inestabilidad de PPO dominen la ejecución.
Esa simplificación explica por qué las pilas abiertas de post-entrenamiento adoptaron DPO rápidamente. El artículo original enfatizó la estabilidad y la baja carga de ajuste, y las recetas públicas, como el trabajo al estilo Zephyr y los lanzamientos posteriores de la familia Tulu, hicieron de DPO una etapa normal en los flujos de trabajo de alineación abiertos.
Lo que DPO no elimina es la dependencia de comparaciones confiables. El optimizador aún hereda la relación de preferencia codificada en el conjunto de datos. Sigue dependiendo de la elección del modelo de referencia, la escala beta, la distribución de los prompts y la política de selección de pares. Si las etiquetas son ruidosas, distribucionalmente estrechas, están sesgadas por artefactos de anotación o son producidas por un juez frágil, DPO optimizará ese problema de manera eficiente.
La familia DPO se diversificó por la misma razón. KTO cambia la forma de supervisión de preferencias por pares a señales de deseable frente a indeseable. ORPO integra el aprendizaje de preferencias en una etapa monolítica al estilo SFT. SimPO elimina el término del modelo de referencia y reportó mejoras sobre DPO en sus configuraciones. Estos son cambios algorítmicos significativos, pero ninguno elimina la necesidad de saber si las etiquetas, los jueces o los puntos de referencia reflejan la calidad final (KTO, ORPO, SimPO).
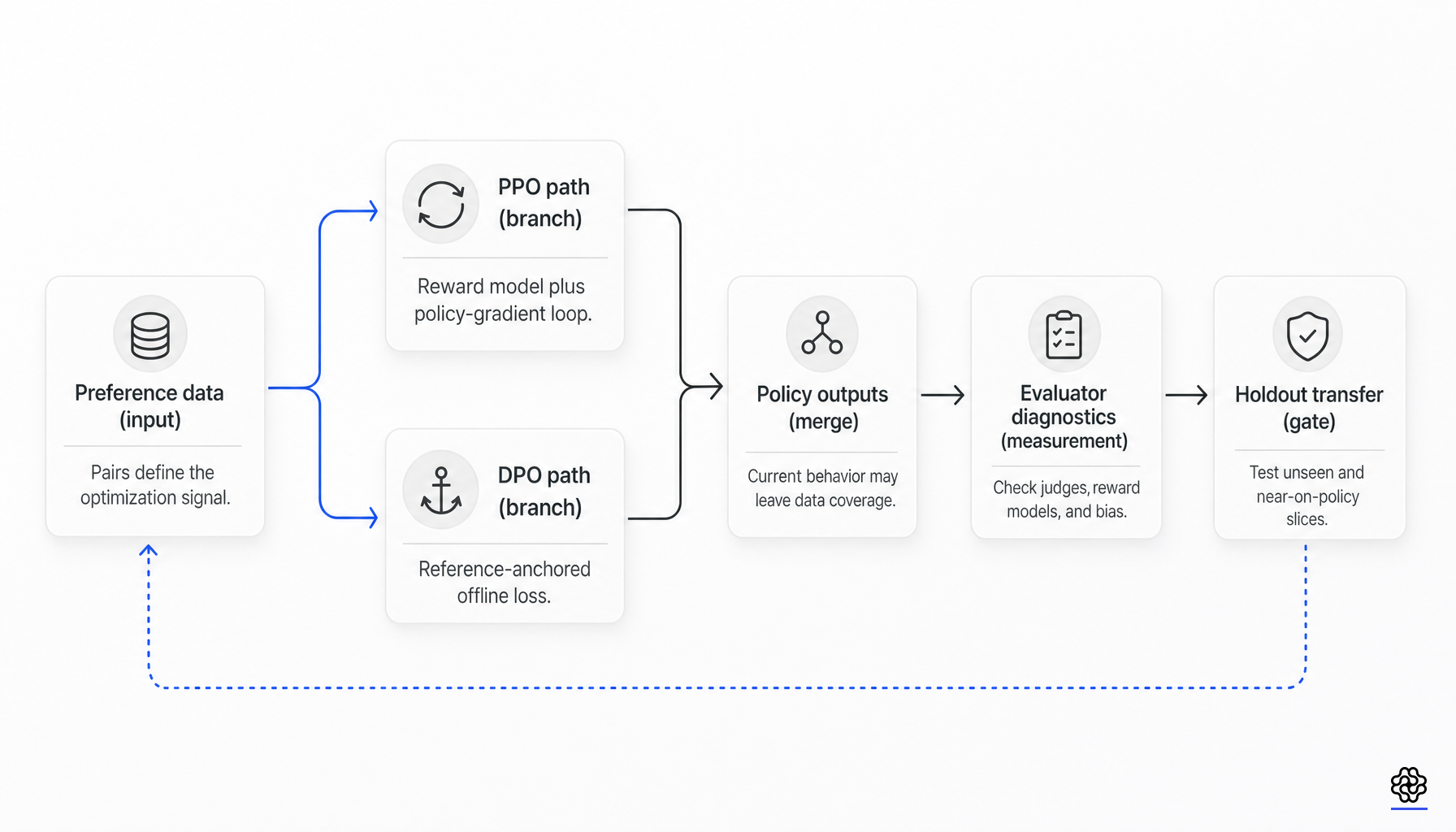
Lo que DPO no elimina
La limitación actual más clara proviene de la literatura sobre cobertura. Song et al. argumentan que los métodos contrastivos offline como DPO necesitan una cobertura global más fuerte para converger a la política óptima, mientras que los métodos de RL online pueden tener éxito bajo una cobertura parcial más débil. El punto operativo es simple: si el conjunto de datos de preferencias fijo no cubre el espacio de respuestas que importa en el momento de la evaluación, el optimizador no puede inferir esa información faltante (datos online y cobertura).
Tajwar et al. llegan a un punto empírico relacionado. Sus experimentos argumentan que el muestreo on-policy y los objetivos de preferencia de estilo de gradiente negativo pueden superar a los objetivos puramente offline porque pueden reasignar la masa de probabilidad hacia las regiones preferidas más rápido. Esa no es una defensa general de PPO. Es un recordatorio de que la información online puede importar cuando los propios errores de la política actual no están representados en los datos estáticos (ajuste fino de preferencias on-policy).
Aquí es donde el lema de DPO frente a PPO generalmente se rompe. Si el comportamiento objetivo es estable y está bien representado en los datos de preferencias, DPO puede obtener la mayor parte de la ganancia práctica con una menor complejidad. Si se espera que el modelo pase a nuevos comportamientos, nuevos regímenes de prompts o segmentos adversarios después del entrenamiento, el equipo aún necesita datos on-policy, RL online, muestreo de rechazo o una actualización de datos dirigida.
Contrastes empíricos detrás del eslogan
La interpretación correcta de la evidencia no es que “DPO perdió” o “PPO ganó”. Es que DPO cambió el optimizador más de lo que cambió la epistemología. Mejores datos de preferencia, la cobertura de la política actual, la transferencia del modelo de recompensa y la confiabilidad del juez a menudo dominan sobre la marca del algoritmo.
La evidencia pública favorece una lectura condicional: DPO suele ser más simple y sólido, mientras que la calidad de los datos, la cobertura y la validez del evaluador siguen decidiendo la transferencia.
| Estudio/informe | Configuración | Resultado clave | Implicación para la medición |
|---|---|---|---|
| Artículo de DPO | DPO frente a RLHF basado en PPO. | DPO igualó o mejoró la calidad de resumen y diálogo con un entrenamiento más simple. | Explica la adopción de DPO sin demostrar que la medición esté resuelta. |
| Unpacking DPO and PPO | Recetas controladas de aprendizaje de preferencias. | PPO superó a DPO en algunos regímenes matemáticos y generales, mientras que la calidad de los datos movió más los resultados. | La elección del algoritmo puede importar menos que la validez de los datos. |
| Ajuste fino de preferencias on-policy | Métodos contrastivos offline frente a métodos online o de gradiente negativo. | El muestreo on-policy puede superar objetivos puramente offline. | Las fallas de cobertura pueden hacer que la información online sea valiosa. |
| RewardBench 2 | Puntuación de benchmark frente a uso posterior. | La correlación best-of-N fue fuerte, pero la transferencia PPO dependió del linaje y la distribución. | El ranking de benchmark por sí solo no es evidencia de transferencia. |
| JudgeBench | Evaluación de jueces LLM. | Los jueces fuertes tuvieron dificultades con pares de respuestas objetivas difíciles. | La evaluación automatizada puede convertirse en el cuello de botella después de simplificar la optimización. |
Artículo de DPO
- Configuración
- DPO frente a RLHF basado en PPO.
- Resultado clave
- DPO igualó o mejoró la calidad de resumen y diálogo con un entrenamiento más simple.
- Implicación para la medición
- Explica la adopción de DPO sin demostrar que la medición esté resuelta.
Unpacking DPO and PPO
- Configuración
- Recetas controladas de aprendizaje de preferencias.
- Resultado clave
- PPO superó a DPO en algunos regímenes matemáticos y generales, mientras que la calidad de los datos movió más los resultados.
- Implicación para la medición
- La elección del algoritmo puede importar menos que la validez de los datos.
Ajuste fino de preferencias on-policy
- Configuración
- Métodos contrastivos offline frente a métodos online o de gradiente negativo.
- Resultado clave
- El muestreo on-policy puede superar objetivos puramente offline.
- Implicación para la medición
- Las fallas de cobertura pueden hacer que la información online sea valiosa.
RewardBench 2
- Configuración
- Puntuación de benchmark frente a uso posterior.
- Resultado clave
- La correlación best-of-N fue fuerte, pero la transferencia PPO dependió del linaje y la distribución.
- Implicación para la medición
- El ranking de benchmark por sí solo no es evidencia de transferencia.
JudgeBench
- Configuración
- Evaluación de jueces LLM.
- Resultado clave
- Los jueces fuertes tuvieron dificultades con pares de respuestas objetivas difíciles.
- Implicación para la medición
- La evaluación automatizada puede convertirse en el cuello de botella después de simplificar la optimización.
Síntesis de OpenTrain a partir de las fuentes citadas sobre DPO, PPO, RewardBench 2, selección de datos y evaluación de jueces.
Ivison et al. encontraron ventajas de PPO en algunos regímenes controlados, al mismo tiempo que demostraron que la calidad de los datos de preferencia podría mejorar el seguimiento de instrucciones y la veracidad más que el propio cambio de optimizador (Unpacking DPO and PPO). El trabajo centrado en datos llega a la misma conclusión práctica. Filtered DPO, Less is More y los conjuntos de datos al estilo HelpSteer apuntan a la misma restricción: la distribución de datos elegida y el protocolo de etiquetado pueden dominar sobre el tamaño bruto del conjunto de datos o el nombre del optimizador (Filtered DPO, Less is More, HelpSteer3-Preference).
Dónde falla primero la medición
El modo de falla más útil no es la manipulación abstracta de recompensas. Es la transferencia mal predicha: el objetivo de preferencia fuera de línea se ve bien en una métrica alineada con el entrenamiento, pero el sistema posterior falla en el comportamiento que realmente le importa al equipo.
RewardBench 2 es un claro ejemplo público. Se construyó en torno a prompts humanos no vistos y un formato más difícil de mejor de 4. Las puntuaciones fueron aproximadamente 20 puntos más bajas en promedio que en el RewardBench original. El benchmark se correlacionó fuertemente con el uso posterior de mejor de N, con una correlación de Pearson de 0.87, pero solo fue una señal útil, no evidencia de transferencia suficiente para PPO. En los experimentos de PPO del artículo, un modelo de recompensa fuera de política con una puntuación de 72.9 en RewardBench 2 logró una puntuación de PPO de 54.5, mientras que un modelo de recompensa en política con una puntuación de 68.7 en RewardBench 2 logró una puntuación de PPO de 59.8 (RewardBench 2).
El trabajo de evaluación de modelos de recompensa sobre la sobreoptimización apunta en la misma dirección. Si el benchmark no se aproxima a la presión de optimización que experimentará la política, una puntuación alta en el benchmark puede decirle al equipo menos de lo que cree (evaluación del modelo de recompensa, sobreoptimización de la recompensa).
Una tercera versión aparece en la propia retroalimentación humana. Un estudio de 2024 sobre Anthropic-HH encontró segmentos sustanciales de bajo acuerdo o sin acuerdo en relación con un comité de modelos de recompensa, y su modelo de datos limpios mejoró el comportamiento posterior de DPO bajo la configuración de evaluación del artículo. Esto no es prueba de que un comité de modelos de recompensa equivalga a la verdad fundamental. Es evidencia de que los datos de preferencia fijos no son un monolito (confiabilidad de la retroalimentación humana).
Los jueces y los modelos de recompensa aún necesitan diagnósticos
Una vez que los equipos dejan de entrenar un modelo de recompensa explícito para PPO, a menudo depositan más confianza en los jueces LLM o en conjuntos de preferencias estáticos. Eso puede ocultar el mismo error de medición detrás de un optimizador más limpio.
JudgeBench demostró que jueces fuertes como GPT-4o tuvieron un desempeño solo ligeramente mejor que adivinar al azar en pares de respuestas objetivas difíciles sobre conocimiento, razonamiento, matemáticas y programación. El Judge Reliability Harness de 2026 de RAND amplió este punto: ningún juez que probaron fue uniformemente confiable en todos los benchmarks, y perturbaciones como cambios de formato, paráfrasis, cambios de verbosidad e inversiones de etiquetas causaron una variación significativa en la confiabilidad (JudgeBench, Judge Reliability Harness).
La literatura sobre sesgos hace que esto sea más evidente. Los evaluadores LLM pueden reconocer y favorecer sus propias generaciones. Los jueces por pares pueden exhibir sesgo de posición, dependencia de la tarea y segmentos difíciles con gran desacuerdo. Length-Controlled AlpacaEval es un buen ejemplo del campo corrigiendo un artefacto de medición en lugar de simplemente mejorar un optimizador (self-preference, position bias, Length-Controlled AlpacaEval).
La lección de mitigación no es que los jueces automatizados sean inutilizables. Es que un juez es un instrumento. Necesita controles de instrumento: intercambios de posición, invariancia de paráfrasis, controles de verbosidad, muestreo repetido y elementos de anclaje con etiquetas conocidas.
Los stacks de producción públicos siguen siendo multietapa
La evidencia pública de los principales productores de modelos apunta en la misma dirección. El informe de post-entrenamiento de Llama 3.1 de Meta indica que cada ronda de alineación involucró SFT, muestreo de rechazo y DPO. Qwen2.5 reporta SFT a gran escala y aprendizaje por refuerzo multietapa. DeepSeek-R1 describe dos etapas de RL, datos de inicio en frío, muestreo de rechazo y una posterior expansión de la supervisión. Tulu 3 combina SFT, datos de preferencia on-policy curados para DPO, modelado de recompensas, RL con recompensas verificables, descontaminación y conjuntos separados de desarrollo frente a evaluación no vista (Llama 3.1, Qwen2.5, DeepSeek-R1, Tulu 3).
La expresión adecuada es una inferencia a partir de la evidencia pública, no un hecho universal sobre cada stack de frontera cerrado. Pero la inferencia es fuerte: los stacks públicos de alto rendimiento no tratan a DPO como una razón para dejar de invertir en evaluación, actualización de datos on-policy, muestreo de rechazo o etapas de RL dirigidas. Utilizan DPO como una etapa dentro de un sistema de post-entrenamiento más amplio.
Un patrón de implementación práctico
Un patrón de post-entrenamiento técnicamente defendible en 2026 se parece menos a “elegir DPO o PPO” y más a un diseño de medición por etapas.
En primer lugar, los equipos necesitan un conjunto de datos de preferencias calibrado para el caso de uso objetivo, en lugar de uno que sea simplemente grande. Si la fuente de datos es heterogénea, segméntela por origen del juez, familia de prompts, tipo de tarea y régimen de ruido probable antes de realizar afirmaciones sobre el entrenamiento.
En segundo lugar, los equipos necesitan diagnósticos del evaluador antes de usar un modelo de recompensa o un juez LLM ya sea como entrenador o como evaluador. Como mínimo, esto significa comprobaciones de intercambio de posición, comprobaciones de invariancia de paráfrasis y formato, comprobaciones de sesgo de verbosidad, estabilidad de muestreo repetido y un pequeño conjunto de anclaje verificado por humanos.
Tercero, los equipos necesitan una evaluación de transferencia real. El conjunto de reserva no se limita a pares de preferencia reservados. Debe incluir prompts no vistos, segmentos adversarios, segmentos de estrés para el juez y, cuando sea posible, un segmento en política o casi en política producido por el modelo actual.
Cuarto, los equipos deben decidir si los datos en línea son necesarios diagnosticando la cobertura, no por ideología. Si las fallas de evaluación se agrupan en las salidas de la política actual, o si el modelo se está moviendo hacia regímenes de razonamiento o seguridad no representados en el conjunto de datos, la recopilación en línea, el muestreo de rechazo o el RL aún pueden ser la forma más económica de obtener una mejora confiable.
La conclusión práctica es específica pero contundente. El DPO debe tratarse como una sustitución del optimizador, no como una sustitución de la evaluación. A menudo elimina la costosa maquinaria de optimización en línea. No elimina la necesidad de saber si el objetivo de preferencia elegido, el proceso de etiquetado, el modelo de recompensa o el juez realmente se transfieren.
OpenTrain puede proveer evaluadores especialistas y operadores de datos de preferencia dentro del stack que un equipo ya utiliza. Utilice la referencia de confiabilidad del juez de LLM para el contexto de calibración del evaluador, la guía de alcance de RLHF para la planificación de datos de preferencia, y publique un trabajo cuando el cuello de botella sea la dotación de personal para el ciclo de revisión.
Fuentes
- Optimización Directa de Preferencias
- Entrenamiento de modelos de lenguaje para seguir instrucciones con retroalimentación humana
- Entrenamiento de un asistente útil e inofensivo con RLHF
- Desglosando DPO y PPO
- Ajuste fino de preferencias con datos on-policy subóptimos
- La importancia de los datos en línea
- RewardBench 2
- Evaluación del modelo de recompensa
- Sobreoptimización de la recompensa
- JudgeBench
- Judge Reliability Harness
- Los evaluadores de LLM reconocen y favorecen sus propias generaciones
- Juzgando a los jueces
- Optimización Directa de Preferencias Filtrada
- Menos es más
- HelpSteer3-Preference
- Llama 3.1
- Informe técnico de Qwen2.5
- Tulu 3
- DeepSeek-R1
- KTO
- ORPO
- SimPO
- Length-Controlled AlpacaEval