Los jueces LLM son sistemas de medición, no oráculos

Referencia técnica sobre cuándo los jueces LLM son confiables para evals de producción y post-entrenamiento, y cómo calibrarlos, auditarlos y controlarlos.
Los jueces LLM son utilizables en producción, pero solo como sistemas de medición que están versionados, calibrados y auditados. La tensión central es que el caso de éxito más citado del campo, GPT-4 alcanzando más del 80% de acuerdo con las preferencias humanas en MT-Bench y Chatbot Arena, ahora se encuentra junto a evidencia más reciente que muestra fallas de transferencia agudas una vez que cambia la mezcla de tareas, la construcción del benchmark, la métrica o la familia de jueces (MT-Bench and Chatbot Arena, Arena-Hard, JUDGE-BENCH, JudgeBench).
Esos resultados no son contradictorios. Describen lo que sucede cuando un juez es tratado como una fuente de verdad portátil en lugar de un instrumento calibrado.
Los primeros resultados de acuerdo eran locales al benchmark, no universales
Los primeros resultados positivos fueron reales. MT-Bench y Chatbot Arena establecieron que los jueces fuertes por pares pueden aproximarse a los juicios de preferencia humana en comparaciones amplias de estilo chat. G-Eval demostró que la evaluación estructurada de GPT-4 podía superar a las métricas automáticas más antiguas en resumen, al tiempo que advertía sobre el sesgo del evaluador hacia el texto generado por LLM (G-Eval). Más tarde, Prometheus 2 demostró que los modelos de evaluadores abiertos pueden mejorar sustancialmente como modelos de jueces dedicados con criterios definidos por el usuario (Prometheus 2).
Esa combinación importa. Significa que el campo no demostró que “un juez LLM funciona” en abstracto. Demostró afirmaciones más limitadas: un juez puede rastrear una distribución particular de preferencias humanas, en una familia particular de benchmarks, bajo un esquema particular de prompting y agregación.
AlpacaEval plantea el mismo punto desde la otra dirección. Su tasa de victorias controlada por longitud aumentó la correlación con Chatbot Arena y redujo la manipulación por longitud, pero sus mantenedores aún advierten contra el uso exclusivo de evaluadores automáticos para decisiones de lanzamiento. Un juez puede ser útil para el desarrollo iterativo y, al mismo tiempo, ser débil como filtro final.
Las metaevaluaciones más difíciles rompieron la historia de la portabilidad
Arena-Hard hizo concreto el problema de la portabilidad. Fue diseñado a partir de datos en vivo obtenidos mediante crowdsourcing para mejorar la separabilidad entre modelos fuertes ajustados por instrucciones, y los autores reportaron un fuerte acuerdo con Chatbot Arena a bajo costo. En el mismo estudio, MT-Bench aún podía preservar un orden de clasificación aproximado mientras fallaba mucho más en la separabilidad. Ese es exactamente el desajuste métrico que rompe el razonamiento del filtro de lanzamiento: un benchmark puede clasificar candidatos y aun así fallar en separar sistemas cercanos a la frontera lo suficientemente bien para tomar decisiones de lanzamiento.
JUDGE-BENCH amplió el problema a través de 20 tareas de evaluación de PNL y 11 modelos de juez. Los modelos con la mayor cantidad de respuestas válidas promediaron una modesta concordancia corregida por azar, con una varianza muy grande según el conjunto de datos. GPT-4o podía parecer fuerte en un segmento y cercano a cero o negativo en otro. El mismo artículo encontró que los jueces se alineaban mejor con las anotaciones de no expertos que con las anotaciones de expertos, y mejor con el lenguaje generado por humanos que con el texto generado por máquinas.
JudgeBench fue aún más lejos al alejarse de la alineación estilística o de preferencia del público y acercarse a la corrección objetiva en conocimiento, razonamiento, matemáticas y programación. Su resumen informa que muchos jueces fuertes, incluido GPT-4o, tienen un desempeño solo un poco mejor que adivinar al azar en los pares de respuestas más difíciles. IF-RewardBench extiende la crítica a la evaluación del seguimiento de instrucciones al argumentar que la metaevaluación únicamente por pares está desalineada con los flujos de trabajo de clasificación por listas utilizados en la optimización (IF-RewardBench).
Benchmark snapshots show transfer limits
| Benchmark | Evaluation regime | Reliability implication |
|---|---|---|
| MT-Bench / Chatbot Arena | Pairwise chat preference judgments | Strong benchmark-local agreement does not imply universal transfer. |
| Arena-Hard | Harder separability from live arena data | Benchmark construction changes what agreement means. |
| JUDGE-BENCH | 20 NLP tasks and 11 judge models | Chance-corrected and rank metrics vary substantially by task. |
| JudgeBench | Objective correctness across reasoning domains | Correctness-heavy tasks expose weak transfer from preference-style judging. |
MT-Bench / Chatbot Arena
- Evaluation regime
- Pairwise chat preference judgments
- Reliability implication
- Strong benchmark-local agreement does not imply universal transfer.
Arena-Hard
- Evaluation regime
- Harder separability from live arena data
- Reliability implication
- Benchmark construction changes what agreement means.
JUDGE-BENCH
- Evaluation regime
- 20 NLP tasks and 11 judge models
- Reliability implication
- Chance-corrected and rank metrics vary substantially by task.
JudgeBench
- Evaluation regime
- Objective correctness across reasoning domains
- Reliability implication
- Correctness-heavy tasks expose weak transfer from preference-style judging.
OpenTrain synthesis from cited benchmark and meta-evaluation sources.
Métricas de confiabilidad corregidas por azar
El porcentaje de concordancia es un argumento de lanzamiento débil por sí solo. Si el equilibrio de las etiquetas está sesgado, un juez puede concordar a menudo mientras agrega poca información. Para la evaluación categórica, la concordancia corregida por azar debe acompañar a la concordancia principal.
El sesgo y los efectos de la familia de jueces crean un error estructurado
La actualización de confiabilidad más importante del campo es que el sesgo ya no es una nota al margen. Es una fuente medible de error estructurado.
El trabajo sobre el sesgo de posición ha ido más allá de la anécdota. Un estudio sistemático en MTBench y DevBench introdujo la estabilidad de repetición, la consistencia de posición y la equidad de preferencia, analizó más de 100,000 instancias de evaluación y descubrió que el sesgo de posición no es producto del azar (estudio de sesgo de posición). La identidad del juez, la categoría de la tarea y la brecha de calidad de las respuestas, todos importan.
La autopreferencia es igualmente importante porque vincula la evaluación a la familia del modelo. Una línea de trabajo demostró que los evaluadores LLM pueden reconocer y favorecer sus propias generaciones; un estudio posterior relacionó la autopreferencia de GPT-4 con la familiaridad y una menor perplejidad en lugar de simple vanidad (reconocimiento propio, autopreferencia). Esto es importante siempre que el juez, la política y el generador de datos provengan de la misma familia o compartan un estilo de posentrenamiento similar.
El diseño de referencia vuelve a cambiar el modo de fallo. “No Free Labels” descubrió que la capacidad de un juez para responder a una pregunta está conectada con su capacidad para calificar las respuestas a esa pregunta, y que un juez más débil con referencias humanas más fuertes puede superar a un juez más fuerte con referencias sintéticas (No Free Labels). Los hallazgos de los conjuntos apuntan en la misma dirección: los paneles de jueces diversos pueden reducir el sesgo de una sola familia y costar menos que un solo juez grande en algunos entornos (Replacing Judges with Juries).
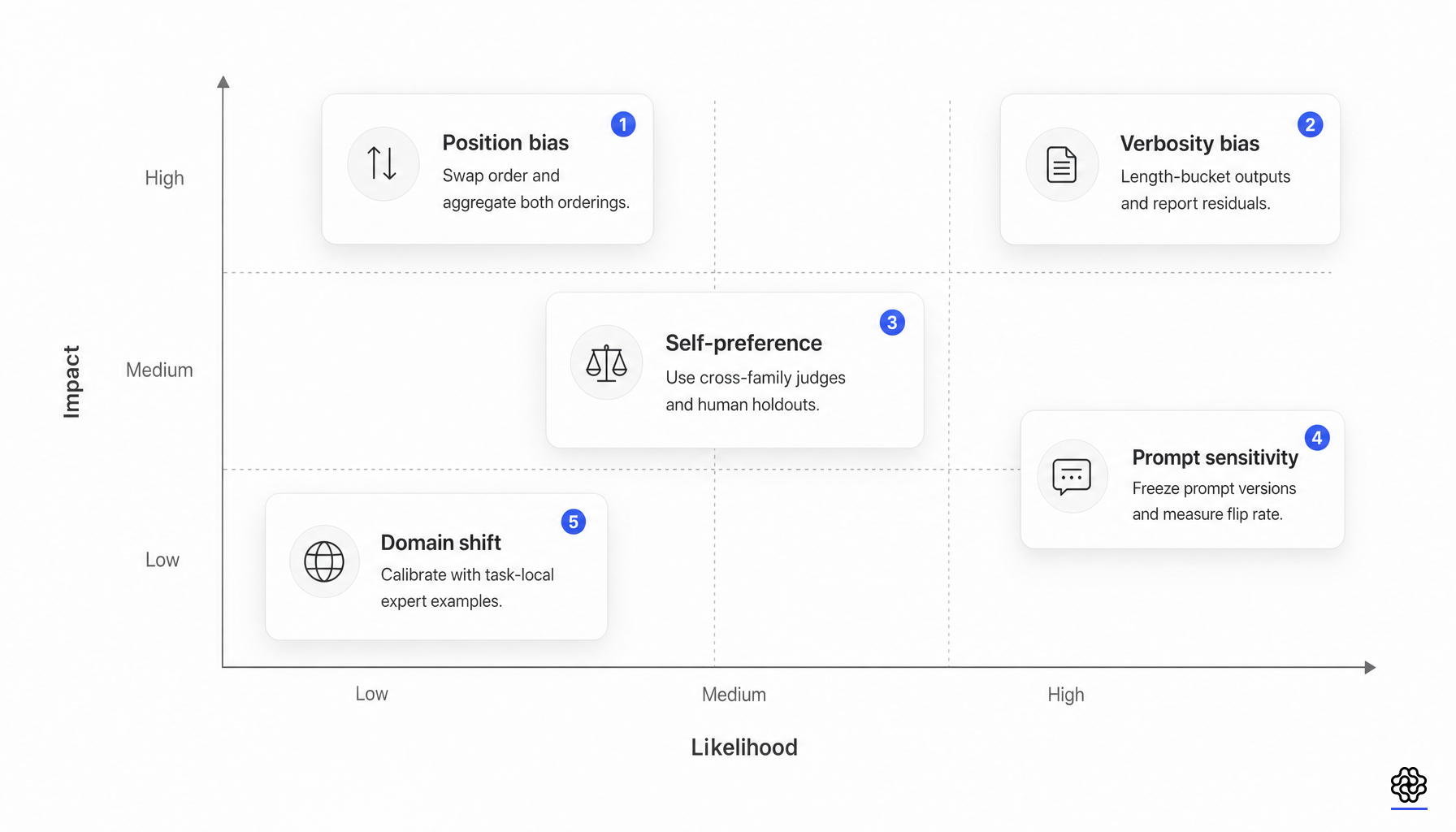
En el post-entrenamiento, la calidad de la recompensa es tan buena como la calibración del juez
Una vez que el juez pasa de la evaluación al entrenamiento, el error de medición se convierte en error de optimización. RewardBench presentó el caso original para la evaluación directa del modelo de recompensa a través de triples de indicaciones (prompts), elegidos y rechazados. RewardBench 2 actualizó esa historia con un punto de referencia más difícil construido a partir de indicaciones humanas en su mayoría no vistas, seis dominios, 1,865 indicaciones, finalizaciones de 20 modelos o humanos, una configuración de puntuación del mejor de 4 y un subconjunto de empates destinado a probar la calibración entre respuestas equivalentemente válidas (RewardBench 2, dataset card).
RewardBench 2 es útil porque resiste una historia simplista sobre la transferencia de la puntuación del punto de referencia al entrenamiento. El artículo muestra una fuerte correlación con el rendimiento del muestreo del mejor de N, pero también dice que la correlación PPO de RLHF se ve afectada por factores específicos del contexto. Las puntuaciones de los puntos de referencia de recompensa basadas en la precisión son un requisito previo para un entrenamiento sólido de RLHF, pero no son suficientes.
Las mejores señales de los jueces pueden ayudar cuando se usan con cuidado. El razonamiento comparativo de multitudes aumenta el juicio por pares con respuestas adicionales de la multitud y muestra ganancias en los puntos de referencia de preferencia, incluidas las mejoras en el muestreo de rechazo posterior (Crowd Comparative Reasoning). La lección no es que el cálculo adicional del tiempo del juez resuelva la confiabilidad. Es que los protocolos de juicio más ricos pueden mejorar la señal de medición utilizada para la selección y el filtrado.
La documentación oficial del producto ahora refleja la misma realidad. Los documentos de los calificadores de OpenAI tratan a los calificadores como objetos de primera clase para las evaluaciones y el ajuste fino de refuerzo, recomiendan probar a los calificadores con modelos de alta calidad y ejemplos humanos, y definen el hackeo del calificador como el caso en el que un modelo obtiene una puntuación alta en las evaluaciones del calificador pero baja en las evaluaciones de expertos humanos (OpenAI graders, reinforcement fine-tuning cookbook). El modo de fallo es sencillo: el equipo integra a un juez en el ciclo antes de validar si la puntuación se mantiene alineada una vez que la política comienza a optimizarse en su contra.
Where judge signals enter post-training
| Workflow stage | Judge artifact | Minimum control |
|---|---|---|
| Eval-only regression testing | Versioned judge prompt over a calibration set | Track drift, slice deltas, and chance-corrected agreement. |
| Rejection sampling | Pairwise, listwise, or verifier score | Audit whether selection improves human-preferred outputs on target slices. |
| Reward-model benchmarking | Reward model or judge ensemble | Separate benchmark score from downstream PPO or best-of-N behavior. |
| RFT / RLHF grading | Rubric grader or reward signal | Run small-scale validation before scaling optimization. |
| Release gating | Calibrated judge score plus human audit | Require uncertainty bounds, disagreement limits, and slice checks. |
Eval-only regression testing
- Judge artifact
- Versioned judge prompt over a calibration set
- Minimum control
- Track drift, slice deltas, and chance-corrected agreement.
Rejection sampling
- Judge artifact
- Pairwise, listwise, or verifier score
- Minimum control
- Audit whether selection improves human-preferred outputs on target slices.
Reward-model benchmarking
- Judge artifact
- Reward model or judge ensemble
- Minimum control
- Separate benchmark score from downstream PPO or best-of-N behavior.
RFT / RLHF grading
- Judge artifact
- Rubric grader or reward signal
- Minimum control
- Run small-scale validation before scaling optimization.
Release gating
- Judge artifact
- Calibrated judge score plus human audit
- Minimum control
- Require uncertainty bounds, disagreement limits, and slice checks.
OpenTrain synthesis from RewardBench 2, OpenAI grader guidance, RLAIF literature, and recent rubric-based post-training work.
Una pila de jueces en producción necesita calibración, control de versiones y escalamiento humano
El material público de OpenAI y Anthropic sugiere que los equipos de frontera tratan a los jueces como componentes en pilas de medición en capas, no como autoridades de lanzamiento independientes. OpenAI expone a los calificadores como parte de los flujos de trabajo de evaluación y ajuste fino de refuerzo. Anthropic informa que un solo juez de LLM puede ser consistente para los componentes de respuesta clara de un sistema de investigación, al tiempo que afirma que las pruebas humanas siguen siendo esenciales porque las personas detectan alucinaciones, fallos del sistema y errores de calidad de la fuente que la automatización pasa por alto (Anthropic engineering).
La literatura de calibración más reciente está convergiendo en el mismo enfoque. SLMEval argumenta que varios evaluadores calibrados fallan en tareas abiertas del mundo real y reporta una mejora en casos de uso de producción utilizando pequeñas cantidades de datos de preferencia humana más calibración basada en entropía (SLMEval). Un artículo sobre confiabilidad basada en IRT separa la consistencia intrínseca, que pregunta si el juez se comporta de manera estable bajo la variación del prompt, de la alineación humana, que pregunta si ese comportamiento estable está realmente alineado con las evaluaciones de calidad humanas (IRT reliability).
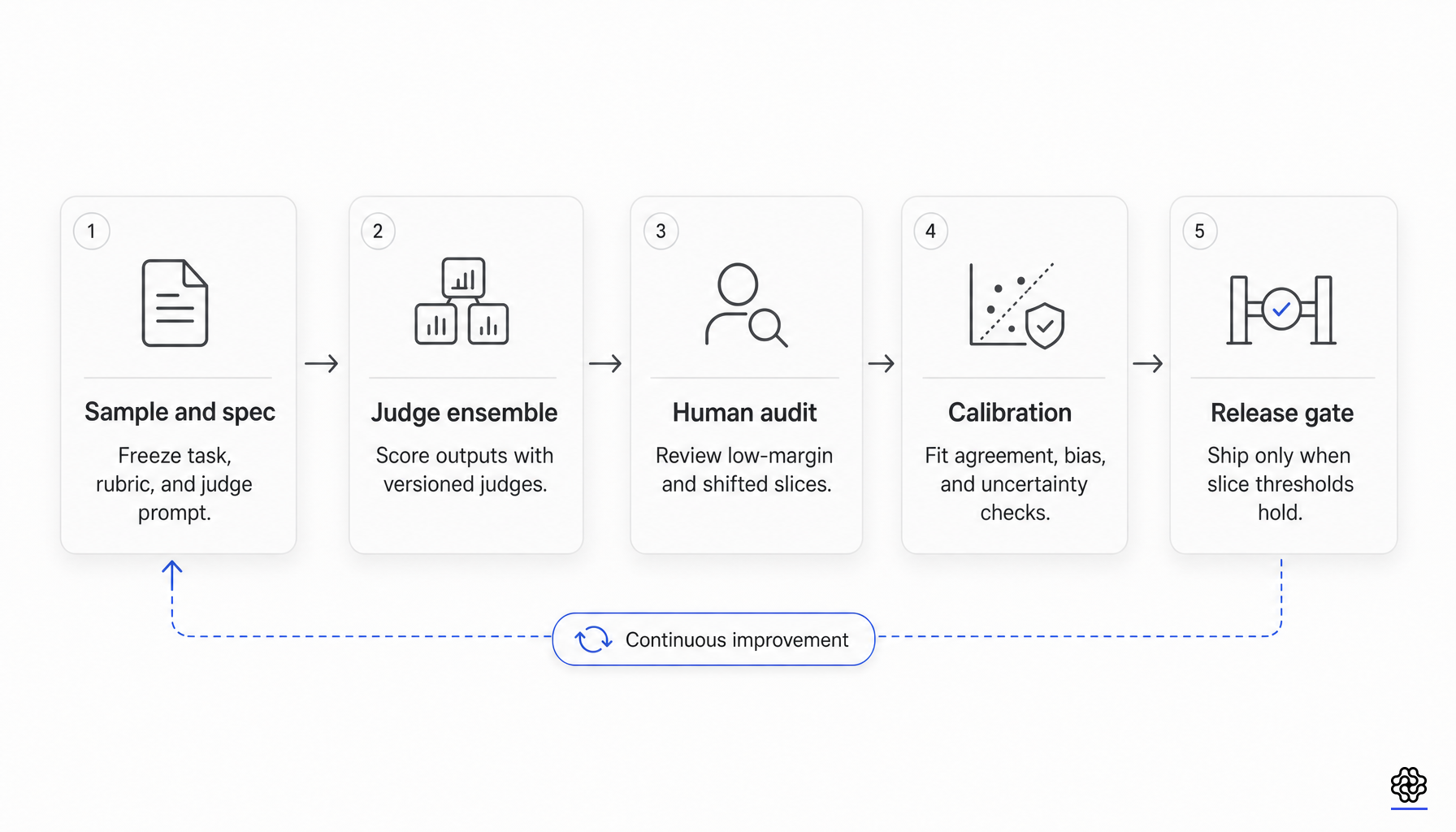
De la evidencia se desprende un antipatrón concreto para el control de lanzamiento: usar una única puntuación promedio del juez o una tasa de victorias por pares como un umbral de aprobación universal. Eso asume una invariancia de medición que la evidencia actual no respalda. Un mejor contrato mínimo es más acotado y se audita explícitamente:
- Fijar la versión del modelo juez, el prompt del juez, el texto de la rúbrica, la política de referencia, la política de empates y la lógica de agregación.
- Mantener un conjunto de calibración etiquetado por humanos para la distribución exacta de lanzamiento, incluyendo los segmentos de alto riesgo.
- Reportar al menos una métrica de acuerdo corregida por azar más una métrica de clasificación o separabilidad.
- Auditar los efectos de orden, los efectos de estilo y longitud, la preferencia por la propia familia y la sensibilidad a la referencia.
- Separar la selección de recompensas durante el entrenamiento de la aceptación durante el lanzamiento.
- Escalar los segmentos de bajo margen, alto desacuerdo o recientemente desplazados a la adjudicación humana.
El límite práctico
La implicación práctica para los equipos de producción es limitada, pero sigue siendo fuerte. Los jueces LLM son útiles donde la evaluación humana es demasiado lenta o costosa para ejecutarse continuamente, donde el objetivo de evaluación es abierto y donde el equipo está dispuesto a dedicar un esfuerzo real en la calibración, las auditorías de sesgo y las colas de adjudicación humana.
No son medidores de verdad portátiles. Son infraestructura de medición. Los equipos que los tratan de esa manera pueden usarlos para la detección diaria de regresiones, el filtrado de candidatos, la selección de modelos de recompensa y el escalamiento humano selectivo. Los equipos que no lo hagan eventualmente optimizarán hacia sus puntos ciegos.
OpenTrain puede proveer adjudicadores humanos especializados para conjuntos de calibración, segmentos de auditoría y controles de desviación dentro de la pila de evaluación que un equipo ya utiliza. Comience con el Servicio Gestionado cuando el cuello de botella sea operar el ciclo de revisión, o publique un trabajo cuando el equipo desee contratar directamente.
Fuentes
- MT-Bench and Chatbot Arena
- G-Eval
- AlpacaEval
- Arena-Hard
- JUDGE-BENCH
- JudgeBench
- IF-RewardBench
- Sesgo de posición en LLM como juez
- Autorreconocimiento y autopreferencia
- No Free Labels
- RewardBench 2
- Evaluadores de OpenAI
- Recetario de ajuste fino por refuerzo de OpenAI
- Sistema de investigación multiagente de Anthropic
- SLMEval
- Diagnóstico de confiabilidad mediante la teoría de respuesta al ítem