Cómo definir el alcance de un programa de datos RLHF

Un marco práctico para lanzar un programa RLHF: defina la geometría de la cola, dimensione a los evaluadores según el rendimiento observado, presupueste el ciclo de revisión.
La mayoría de los primeros programas de datos de RLHF fallan en la capa humana, no en el bucle PPO. Los errores costosos son comunes: una rúbrica que mezcla seguridad, veracidad, estilo y éxito en la tarea en un solo clic; la falta de una fase de calibración antes del etiquetado de producción; y un presupuesto que asume que cada par de preferencias tiene el mismo costo. Los ejemplos públicos van desde el trabajo inicial de OpenAI sobre backflips, que utilizó alrededor de 900 bits de retroalimentación en menos de una hora de tiempo de evaluación, hasta el lanzamiento de HH-RLHF de Anthropic con 169,352 filas elegidas/rechazadas (OpenAI, conjunto de datos Anthropic HH-RLHF). El alcance debe definirse a partir de la geometría de la tarea, no copiando una cifra destacada de un laboratorio de vanguardia.
¿Qué están evaluando realmente los humanos?
Comience con una pregunta más específica que “¿qué respuesta es mejor?”. InstructGPT separó las demostraciones supervisadas, las comparaciones de modelos de recompensa y los prompts para la optimización de políticas; esos productos de datos enseñan diferentes partes del sistema (InstructGPT). Las demostraciones enseñan el formato y la finalización de tareas. Los pares de preferencias enseñan el juicio relativo. Los grupos de prompts deciden qué ve el modelo ajustado durante el entrenamiento.
Para un primer o segundo programa, divida el trabajo en tres colas:
- Cola de éxito: prompts donde el modelo suele tener razón y necesita verificaciones de preferencia ocasionales.
- Cola de límites: casos extremos donde el comportamiento se desvía en cuanto a política, seguridad, veracidad o estilo.
- Cola de recuperación: casos adversarios o de alto riesgo donde una respuesta incorrecta resulta costosa.
Esa división de colas determina qué producto de anotación comprar primero. Si necesita preferencias por pares, oriente el programa hacia RLHF y datos de preferencia. Si el fallo reside dentro de la respuesta, recopile etiquetas dentro de la respuesta. El trabajo de supervisión de procesos de OpenAI lanzó PRM800K con aproximadamente 800,000 etiquetas a nivel de paso y descubrió que la supervisión de procesos superaba a la supervisión de resultados en el entorno MATH evaluado (Let’s Verify Step by Step). Para matemáticas, razonamiento de código y uso de herramientas de varios pasos, la preferencia por pares por sí sola suele ser demasiado imprecisa.
¿Cuántos datos son suficientes para la primera ejecución seria?
Utilice los programas públicos como formas operativas, no como cuotas. El trabajo de resumen de OpenAI utilizó 64,832 comparaciones de resúmenes; InstructGPT informó sobre 13,000 prompts supervisados, alrededor de 33,000 prompts para modelos de recompensa y cerca de 40 contratistas evaluados; PRM800K fue mucho mayor porque cada unidad de supervisión era un juicio a nivel de paso más pequeño (resumen a partir de retroalimentación humana, InstructGPT, PRM800K).
Formas de programas públicos RLHF
| Programa público | Huella de retroalimentación humana | Lo que le indica |
|---|---|---|
| OpenAI backflip | Alrededor de 900 bits de retroalimentación, menos de 1 hora de tiempo del evaluador y unas 70 horas de experiencia simulada. | Los objetivos muy específicos pueden justificar pilotos pequeños si la tarea es fácil de evaluar. |
| Resumen de OpenAI | 64,832 comparaciones de resúmenes. | Un programa de alineación de texto de una sola tarea alcanza decenas de miles rápidamente una vez que se busca un modelado de recompensa estable. |
| InstructGPT | Alrededor de 13k prompts de SFT, 33k prompts de modelo de recompensa y unos 40 contratistas. | La alineación de asistentes generalmente requiere múltiples colas, no un solo tipo de anotación. |
| Anthropic HH-RLHF | 169,352 filas elegidas y rechazadas en el conjunto de datos publicado; la configuración de entrenamiento subyacente utilizó una actualización semanal en línea con retroalimentación humana reciente. | El post-entrenamiento conversacional se beneficia de los ciclos de actualización, no de un lote estático. |
| Supervisión de procesos de OpenAI | PRM800K con 800,000 etiquetas a nivel de paso; el modelo supervisado por procesos resolvió el 78% de un subconjunto representativo de MATH. | Las etiquetas a nivel de paso solo valen la pena cuando la corrección intermedia es el verdadero cuello de botella. |
OpenAI backflip
- Huella de retroalimentación humana
- Alrededor de 900 bits de retroalimentación, menos de 1 hora de tiempo del evaluador y unas 70 horas de experiencia simulada.
- Lo que le indica
- Los objetivos muy específicos pueden justificar pilotos pequeños si la tarea es fácil de evaluar.
Resumen de OpenAI
- Huella de retroalimentación humana
- 64,832 comparaciones de resúmenes.
- Lo que le indica
- Un programa de alineación de texto de una sola tarea alcanza decenas de miles rápidamente una vez que se busca un modelado de recompensa estable.
InstructGPT
- Huella de retroalimentación humana
- Alrededor de 13k prompts de SFT, 33k prompts de modelo de recompensa y unos 40 contratistas.
- Lo que le indica
- La alineación de asistentes generalmente requiere múltiples colas, no un solo tipo de anotación.
Anthropic HH-RLHF
- Huella de retroalimentación humana
- 169,352 filas elegidas y rechazadas en el conjunto de datos publicado; la configuración de entrenamiento subyacente utilizó una actualización semanal en línea con retroalimentación humana reciente.
- Lo que le indica
- El post-entrenamiento conversacional se beneficia de los ciclos de actualización, no de un lote estático.
Supervisión de procesos de OpenAI
- Huella de retroalimentación humana
- PRM800K con 800,000 etiquetas a nivel de paso; el modelo supervisado por procesos resolvió el 78% de un subconjunto representativo de MATH.
- Lo que le indica
- Las etiquetas a nivel de paso solo valen la pena cuando la corrección intermedia es el verdadero cuello de botella.
Síntesis OpenTrain a partir de fuentes públicas citadas.
La primera regla es realizar una prueba piloto antes de escalar. RewardBench informa que algunos conjuntos de prueba de datos de preferencia tienen una precisión máxima humana en el rango del 60-70%, lo que significa que el desacuerdo puede ser una propiedad de la tarea en lugar de un fallo en la capacidad del evaluador (RewardBench). Si el acuerdo en su prueba piloto es deficiente, añada especificaciones antes de añadir puestos.
La segunda regla es aumentar la densidad de información antes que el número de prompts. InstructGPT pidió a los etiquetadores que clasificaran de 4 a 9 resultados para un prompt, lo que generó más información de comparación por prompt que una simple elección binaria (InstructGPT). A menudo, ese es un mejor primer paso que duplicar el grupo de evaluadores en una rúbrica inestable.
¿Cuántos evaluadores necesita realmente?
El número de evaluadores es un cálculo de rendimiento con un margen de discrepancia:
Utilice los números de su programa piloto para el denominador. La utilización productiva incluye todo lo que resta tiempo al etiquetado puro: actualización de rúbricas, adjudicación, controles aleatorios, reentrenamiento, descansos y fricción de las herramientas.
Por ejemplo, supongamos que el piloto muestra 180 juicios calibrados por evaluador a la semana y la próxima actualización requiere 3,000 juicios por semana. Con una utilización productiva del 70%, el equipo base es ceil(3000 / 180 / 0.70) = 24 evaluadores antes de aplicar los márgenes de dominio, idioma, zona horaria y capacidad de respaldo. Si la cola requiere cuatro celdas de dominio-idioma, realice el cálculo por celda antes de agrupar el total.
Los puntos de referencia públicos solo son útiles como controles de coherencia. InstructGPT informó una concordancia entre etiquetadores de entrenamiento del 72.6 +/- 1.5% y una concordancia entre etiquetadores de prueba del 77.3 +/- 1.3%; el trabajo de resumen de OpenAI informó una concordancia entre investigadores del 73 +/- 4% (InstructGPT, resumen a partir de retroalimentación humana). Esas cifras no son prescripciones para el número de evaluadores. Son recordatorios de que un equipo pequeño y calibrado puede respaldar una ejecución seria, y que una discrepancia en el rango del 60% alto o 70% bajo puede ser normal cuando la tarea es difícil.
La cobertura es tan importante como el número bruto. Si la cola abarca medicina, seguridad multilingüe y revisión de código, usted está dimensionando celdas de dominio-idioma, no un grupo de trabajo unificado. El AI RMF del NIST exige diversas perspectivas al mapear y medir los riesgos de la IA; su Perfil de IA Generativa también recomienda ejercicios estructurados de retroalimentación humana con roles y rutas de revisión documentados (NIST AI RMF 1.0, NIST GenAI Profile).
¿Cómo debe estructurarse el presupuesto?
Una lista de precios de fuente primaria para pares de preferencia de RLHF a través de dominios, idiomas y diseños de tareas no es verificable públicamente. Presupueste a partir del trabajo cronometrado:
La partida que los equipos pasan por alto es la adjudicación y el tiempo de los investigadores. El documento sobre resumen de OpenAI indica que el conjunto de datos de retroalimentación humana requirió una cantidad significativa de horas de etiquetadores y tiempo de investigadores para garantizar la calidad (resumen a partir de retroalimentación humana). Es por eso que los proyectos piloto que parecen económicos en una hoja de cálculo se vuelven costosos una vez que la rúbrica comienza a cambiar.
Trate las tarifas de abastecimiento y de mercado como algo separado de la mano de obra. OpenTrain publica una tarifa de autoservicio del 15% y una tarifa de servicio gestionado del 20%; los equipos pueden contratar directamente o utilizar el servicio gestionado cuando deseen que OpenTrain ejecute las operaciones del proyecto (precios de OpenTrain). Eso importa cuando el cuello de botella es el abastecimiento y la operación de una cola calibrada, no el diseño de la actualización del modelo.
¿Qué cronograma debería planificar?
Piense en etapas, no en una fase de etiquetado monolítica:
- Especificación: defina la rúbrica, las reglas de desacuerdo y la ruta de escalamiento.
- Calibración: ejecute elementos de muestra hasta que la adjudicación deje de descubrir nuevas ramas de la rúbrica cada día.
- Piloto: etiquete una cola limitada con una revisión estricta.
- Evaluar: requiera negativos difíciles en el conjunto de evaluación.
- Actualizar: actualice la rúbrica y repita con una cadencia semanal o basada en lanzamientos.
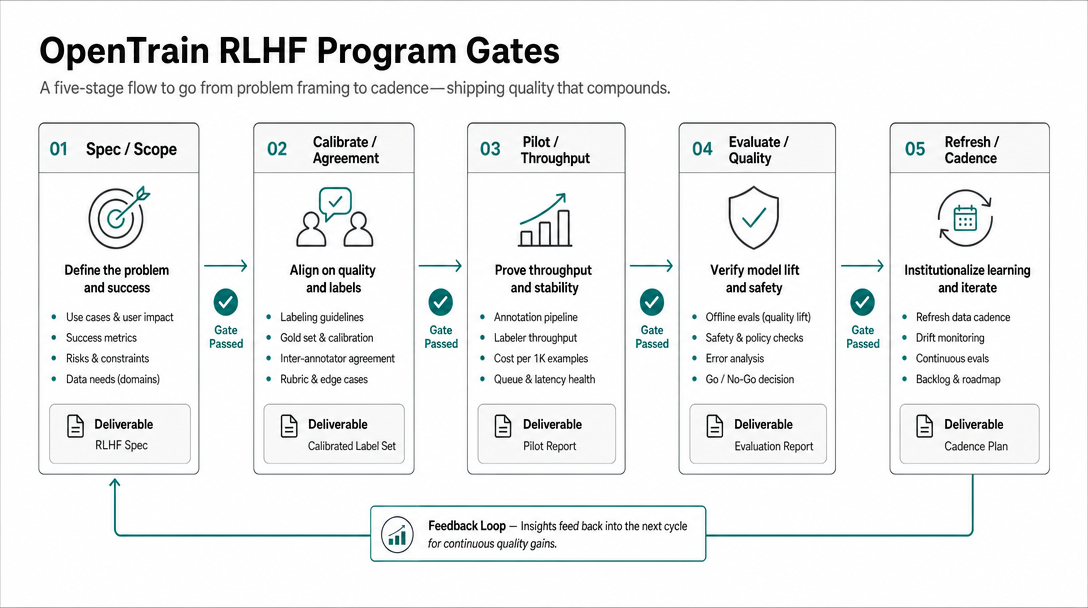
El patrón de investigación pública admite ciclos cortos. El trabajo inicial de preferencia humana de OpenAI muestreó activamente comparaciones donde el modelo era incierto; InstructGPT utilizó conjuntos de datos separados para demostraciones, entrenamiento de modelos de recompensa y optimización de políticas; el trabajo de Sparrow de DeepMind utilizó juicios humanos específicos y evaluaciones respaldadas por evidencia; el artículo sobre asistentes útiles e inofensivos de Anthropic describe la recopilación de datos en línea iterativa con retroalimentación humana fresca (OpenAI human preferences, InstructGPT, Sparrow, Anthropic HH-RLHF). Los primeros y segundos programas deben copiar el ciclo operativo, no el tamaño del conjunto de datos.
¿Cómo cambia el alcance después de la primera ejecución?
El primer programa debe comprar velocidad de aprendizaje. Un programa maduro debe comprar repetibilidad. Trátelos como compras diferentes.
Cómo cambia el alcance de RLHF después de la primera ejecución
| Decisión | Primer programa RLHF | Segundo programa o programa maduro |
|---|---|---|
| Objetivo de datos | Realice una prueba piloto con la cola más pequeña que exponga el desacuerdo en las rúbricas, la fricción en las tareas y los modos de falla evidentes del modelo de recompensa. | Determine el tamaño de los lotes de actualización semanal a partir de la deriva observada del modelo, las nuevas superficies de producto y la extracción de casos negativos difíciles. |
| Grupo de evaluadores | Comience con un grupo pequeño y calibrado, e invierta excesivamente en notas de adjudicación. | Mantenga celdas de lenguaje de dominio, capacidad de respaldo, rutas de promoción para revisores y márgenes de deserción. |
| QA | Revise una alta proporción de etiquetas hasta que la rúbrica deje de cambiar diariamente. | Pase a la revisión por muestreo, elementos de referencia (gold items), paneles de discrepancias y actualizaciones programadas de la rúbrica. |
| Cronograma | Establezca hitos para la especificación, calibración, piloto, evaluación y una primera decisión de actualización. | Establezca hitos para la actualización semanal o basada en lanzamientos, comprobaciones de regresión de evaluación y métricas de salud de la cola. |
| Modelo de abastecimiento | Contrate directamente si el equipo puede gestionar la calibración y la adjudicación. Utilice el Servicio Gestionado si la gestión de la cola es el cuello de botella. | Mantenga un equipo estable, añada especialistas solo cuando el modelo o la superficie del producto cambien, y separe las tarifas de búsqueda de las tarifas de mano de obra. |
| Hito de éxito | Una rúbrica utilizable, un conjunto de evaluación con errores y un modelo de capacidad de los evaluadores. | Una cadencia operativa repetible con rendimiento conocido, bandas de desacuerdo conocidas y una ruta de escalada clara. |
Objetivo de datos
- Primer programa RLHF
- Realice una prueba piloto con la cola más pequeña que exponga el desacuerdo en las rúbricas, la fricción en las tareas y los modos de falla evidentes del modelo de recompensa.
- Segundo programa o programa maduro
- Determine el tamaño de los lotes de actualización semanal a partir de la deriva observada del modelo, las nuevas superficies de producto y la extracción de casos negativos difíciles.
Grupo de evaluadores
- Primer programa RLHF
- Comience con un grupo pequeño y calibrado, e invierta excesivamente en notas de adjudicación.
- Segundo programa o programa maduro
- Mantenga celdas de lenguaje de dominio, capacidad de respaldo, rutas de promoción para revisores y márgenes de deserción.
QA
- Primer programa RLHF
- Revise una alta proporción de etiquetas hasta que la rúbrica deje de cambiar diariamente.
- Segundo programa o programa maduro
- Pase a la revisión por muestreo, elementos de referencia (gold items), paneles de discrepancias y actualizaciones programadas de la rúbrica.
Cronograma
- Primer programa RLHF
- Establezca hitos para la especificación, calibración, piloto, evaluación y una primera decisión de actualización.
- Segundo programa o programa maduro
- Establezca hitos para la actualización semanal o basada en lanzamientos, comprobaciones de regresión de evaluación y métricas de salud de la cola.
Modelo de abastecimiento
- Primer programa RLHF
- Contrate directamente si el equipo puede gestionar la calibración y la adjudicación. Utilice el Servicio Gestionado si la gestión de la cola es el cuello de botella.
- Segundo programa o programa maduro
- Mantenga un equipo estable, añada especialistas solo cuando el modelo o la superficie del producto cambien, y separe las tarifas de búsqueda de las tarifas de mano de obra.
Hito de éxito
- Primer programa RLHF
- Una rúbrica utilizable, un conjunto de evaluación con errores y un modelo de capacidad de los evaluadores.
- Segundo programa o programa maduro
- Una cadencia operativa repetible con rendimiento conocido, bandas de desacuerdo conocidas y una ruta de escalada clara.
Modelo de alcance de OpenTrain.
¿Dónde suelen fallar los programas?
La mayoría de los fallos de calidad son fallos de medición. RewardBench informa que algunos subconjuntos difíciles siguen siendo complicados para los modelos de recompensa, y que el desacuerdo humano puede limitar la fiabilidad de los puntos de referencia (RewardBench). Si una evaluación interna se satura inmediatamente, probablemente sea demasiado fácil para gobernar la próxima actualización del modelo.
Para el trabajo de veracidad y sensible a las políticas, facilite el juicio del evaluador. Sparrow adjuntó evidencia a las afirmaciones fácticas y evaluó las violaciones de reglas bajo sondeo adversarial (Blog de DeepMind Sparrow, documento de Sparrow). Para programas de producción, conecte esto con la evaluación de LLM desde el principio: el conjunto de evaluación debe contener ejemplos que el modelo aún no acierta, no solo ejemplos que demuestren que el piloto funcionó.
La gobernanza debe estar dentro del alcance cuando el sistema es de alto riesgo o está destinado a producción. El AI RMF y el GenAI Profile del NIST son referencias operativas útiles para documentar riesgos, métodos de medición y el uso de retroalimentación; la Ley de IA de la UE exige prácticas de gobernanza como documentación técnica, registro de actividades, supervisión humana y robustez para sistemas de IA de alto riesgo (NIST AI RMF 1.0, NIST GenAI Profile, resumen de la Ley de IA de la UE). Esto no constituye asesoramiento legal. Es un recordatorio sobre el alcance: si el flujo de trabajo de RLHF alimenta un proceso de alto riesgo, la documentación comienza en la primera semana.
¿Qué debería dejar atrás el primer programa?
Un buen primer programa de RLHF deja tres activos reutilizables:
- Una rúbrica que haya incorporado adjudicaciones repetidas.
- Un conjunto de evaluación con ejemplos que el modelo aún no acierta.
- Un modelo de capacidad de evaluadores que el equipo pueda ejecutar semanalmente sin tener que volver a aprender las operaciones.
Si esos artefactos existen, el siguiente programa será más económico de definir. Si no existen, el equipo compró etiquetas, pero no compró un sistema operativo.
Qué hacer a continuación
Citas
- OpenAI — Learning from human preferences
- Training language models to follow instructions with human feedback
- Learning to summarize from human feedback
- Ficha del conjunto de datos Anthropic HH-RLHF
- Training a Helpful and Harmless Assistant with RLHF
- Sparrow: Mejora de la alineación de agentes de diálogo mediante juicios humanos específicos
- DeepMind — Creación de agentes de diálogo más seguros
- Verifiquemos paso a paso
- RewardBench
- NIST AI RMF 1.0
- Perfil de IA generativa del NIST
- Descripción general de la Ley de IA de la UE
- Precios de OpenTrain