Direct Preference Optimization vs PPO après RLHF

Une référence technique sur ce que le DPO change après RLHF, où le PPO et les données en ligne restent importants, et pourquoi mesurer les préférences reste difficile.
L’optimisation directe des préférences n’a pas entièrement remplacé RLHF. Elle a remplacé une grande partie de ce que de nombreuses équipes associaient à RLHF : l’entraînement d’un modèle de récompense explicite puis l’exécution de PPO sur celui-ci. L’interprétation la plus forte est plus étroite et plus utile. Le DPO simplifie beaucoup plus l’optimisation qu’il ne simplifie la mesure.
Lorsque les données de préférence hors ligne ont une faible couverture, que les juges sont biaisés, que les modèles de récompense généralisent mal ou que les étiquettes sont bruitées, l’absence de la boucle PPO n’est pas le problème central. Le problème central est de savoir si l’objectif de préférence mesuré se transfère au comportement dont l’équipe se soucie réellement (DPO, InstructGPT, helpful-harmless RLHF).
L’objectif change, mais pas la charge de la preuve
RLHF de type PPO et le DPO sont des interfaces d’optimisation différentes pour des objectifs d’apprentissage des préférences connexes. Aucun des deux ne prouve que les données sous-jacentes ou la pile d’évaluateurs sont suffisamment bonnes.
Dans le RLHF classique basé sur PPO, la politique est optimisée par rapport à une récompense apprise tout en restant proche d’une politique de référence :
Le DPO optimise plutôt une perte par paires sur des réponses choisies et rejetées, le modèle de référence restant présent comme point d’ancrage :
Cette substitution est bien réelle. Elle supprime l’entraînement explicite du modèle de récompense comme prérequis à l’optimisation de la politique, élimine les requêtes de récompense lors du déploiement pendant le réglage fin, et évite le mécanisme séparé de fonction de valeur et de gradient de politique de PPO. Elle ne supprime pas la dépendance aux données de préférence par paires, à l’ancrage de la politique de référence ou à l’évaluation de transfert.
Le DPO supprime le travail explicite d'entraînement modèle de récompense plus PPO, mais pas les données calibrées, les diagnostics des juges ni l'évaluation du transfert.
| Couche | RLHF à l'ère PPO | Approche de la famille DPO | Ce qui doit encore être mesuré | Pourquoi cela reste difficile |
|---|---|---|---|---|
| Modèle de récompense | Entraîner un modèle de récompense explicite avant PPO. | Représenter implicitement la relation de récompense dans la perte par paires. | Validité des étiquettes de préférence. | Des étiquettes bruitées ou étroites optimisent toujours le mauvais signal. |
| Optimisation de la politique | Exécuter PPO avec une machinerie de valeur et de gradient de politique. | Optimiser un objectif hors ligne ancré sur une référence. | Transfert vers le comportement de déploiement. | Les données hors ligne peuvent manquer les erreurs de la politique actuelle. |
| Données on-policy | Peut collecter de nouvelles données de préférence pendant les itérations. | Démarre souvent à partir de données de comparaison fixes. | Couverture des segments cibles. | Les données statiques ne couvrent pas les nouveaux comportements par défaut. |
| Pile d'évaluation | Utilisée pour l'entraînement du modèle de récompense et les preuves de lancement. | Déplace souvent plus de confiance vers les juges ou les données fixes. | Biais et fiabilité du juge. | Les échecs liés à la position, à la verbosité et aux perturbations demeurent. |
| Transfert vers l'ensemble de validation | Benchmarks et contrôles en aval après PPO. | Benchmarks et contrôles en aval après DPO. | Prompts inédits et lignée de la politique. | Le rang dans un benchmark est utile, mais insuffisant. |
Modèle de récompense
- RLHF à l'ère PPO
- Entraîner un modèle de récompense explicite avant PPO.
- Approche de la famille DPO
- Représenter implicitement la relation de récompense dans la perte par paires.
- Ce qui doit encore être mesuré
- Validité des étiquettes de préférence.
- Pourquoi cela reste difficile
- Des étiquettes bruitées ou étroites optimisent toujours le mauvais signal.
Optimisation de la politique
- RLHF à l'ère PPO
- Exécuter PPO avec une machinerie de valeur et de gradient de politique.
- Approche de la famille DPO
- Optimiser un objectif hors ligne ancré sur une référence.
- Ce qui doit encore être mesuré
- Transfert vers le comportement de déploiement.
- Pourquoi cela reste difficile
- Les données hors ligne peuvent manquer les erreurs de la politique actuelle.
Données on-policy
- RLHF à l'ère PPO
- Peut collecter de nouvelles données de préférence pendant les itérations.
- Approche de la famille DPO
- Démarre souvent à partir de données de comparaison fixes.
- Ce qui doit encore être mesuré
- Couverture des segments cibles.
- Pourquoi cela reste difficile
- Les données statiques ne couvrent pas les nouveaux comportements par défaut.
Pile d'évaluation
- RLHF à l'ère PPO
- Utilisée pour l'entraînement du modèle de récompense et les preuves de lancement.
- Approche de la famille DPO
- Déplace souvent plus de confiance vers les juges ou les données fixes.
- Ce qui doit encore être mesuré
- Biais et fiabilité du juge.
- Pourquoi cela reste difficile
- Les échecs liés à la position, à la verbosité et aux perturbations demeurent.
Transfert vers l'ensemble de validation
- RLHF à l'ère PPO
- Benchmarks et contrôles en aval après PPO.
- Approche de la famille DPO
- Benchmarks et contrôles en aval après DPO.
- Ce qui doit encore être mesuré
- Prompts inédits et lignée de la politique.
- Pourquoi cela reste difficile
- Le rang dans un benchmark est utile, mais insuffisant.
Synthèse OpenTrain à partir du DPO, d'InstructGPT, du RLHF d'Anthropic, de la théorie de la couverture, de RewardBench 2 et des recettes publiques de post-entraînement citées dans cet article.
Ce que le DPO supprime réellement
Le DPO supprime l’entraînement explicite du modèle de récompense du processus d’ajustement des préférences et supprime l’optimisation en ligne du gradient de politique de type PPO de cette phase. En termes d’ingénierie, cela signifie moins d’éléments mobiles, une complexité d’implémentation plus faible, une fragilité des hyperparamètres réduite et moins de risques que l’effondrement du modèle de récompense ou l’instabilité du PPO ne dominent l’exécution.
Cette simplification explique pourquoi les stacks de post-entraînement ouverts ont rapidement adopté le DPO. L’article original soulignait la stabilité et la faible charge d’ajustement, et les recettes publiques telles que les travaux de type Zephyr et les versions ultérieures de la famille Tulu ont fait du DPO une étape normale dans les workflows d’alignement ouverts.
Ce que le DPO ne supprime pas, c’est la dépendance à l’égard de comparaisons fiables. L’optimiseur hérite toujours de la relation de préférence encodée dans le jeu de données. Il dépend toujours du choix du modèle de référence, de l’échelle bêta, de la distribution des prompts et de la politique de sélection des paires. Si les étiquettes sont bruitées, à distribution étroite, biaisées par des artefacts d’annotation ou produites par un juge fragile, le DPO optimisera ce problème avec efficacité.
La famille DPO s’est diversifiée pour la même raison. KTO modifie la forme de supervision, passant des préférences par paires à des signaux de type désirable/indésirable. ORPO intègre l’apprentissage des préférences dans une étape monolithique de type SFT. SimPO supprime le terme de modèle de référence et a rapporté des gains par rapport au DPO dans ses configurations. Ce sont des changements algorithmiques significatifs, mais aucun ne supprime la nécessité de savoir si les étiquettes, les juges ou les benchmarks reflètent la qualité en aval (KTO, ORPO, SimPO).
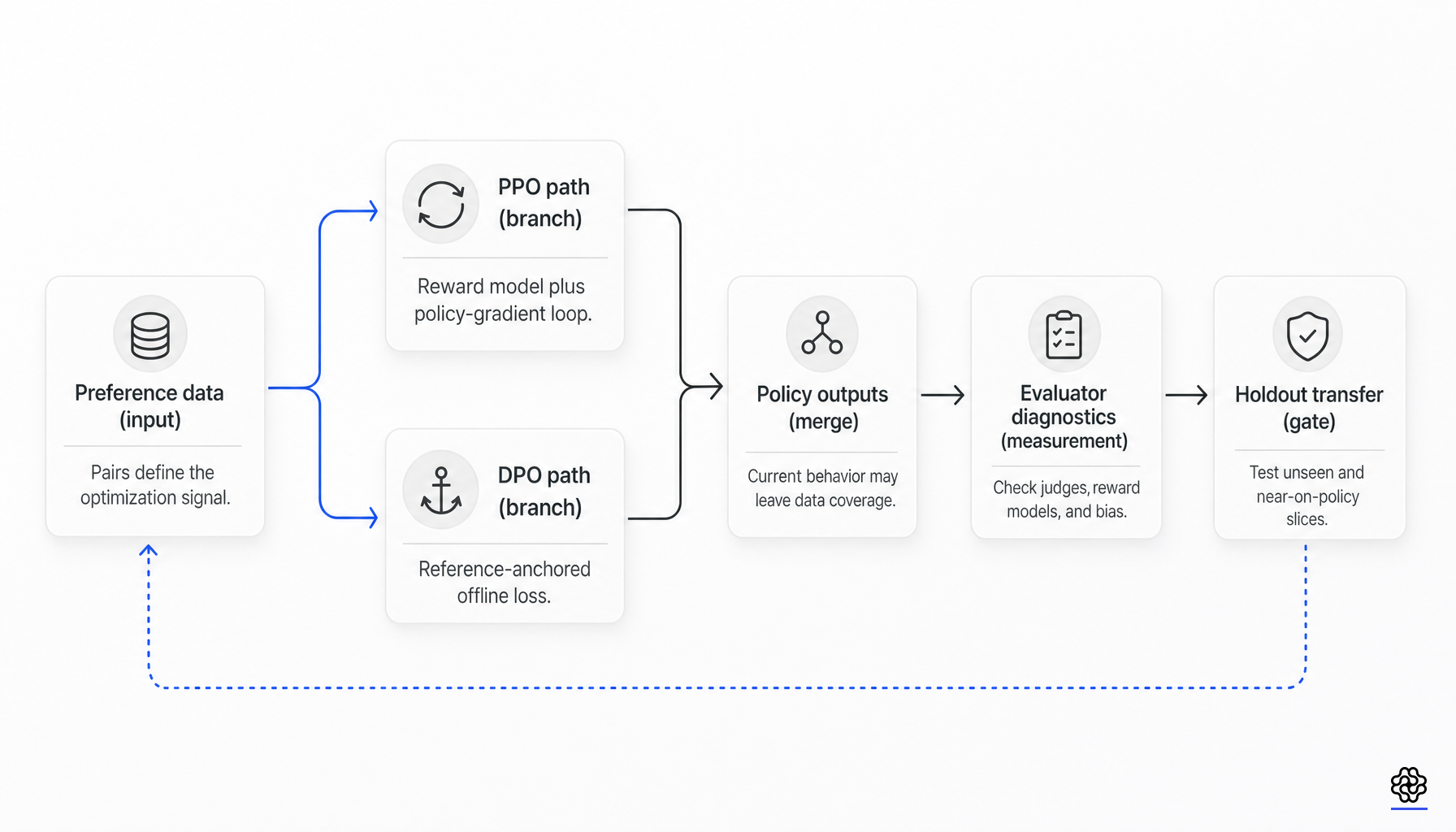
Ce que le DPO ne supprime pas
La limite actuelle la plus évidente provient de la littérature sur la couverture. Song et al. affirment que les méthodes contrastives hors ligne comme le DPO nécessitent une couverture globale plus forte pour converger vers la politique optimale, tandis que les méthodes de RL en ligne peuvent réussir avec une couverture partielle plus faible. Le principe opérationnel est simple : si le jeu de données de préférences fixe ne couvre pas l’espace de réponse pertinent au moment de l’évaluation, l’optimiseur ne peut pas déduire cette information manquante (données en ligne et couverture).
Tajwar et al. parviennent à une conclusion empirique similaire. Leurs expériences démontrent que l’échantillonnage sur politique et les objectifs de préférence de type gradient négatif peuvent surpasser les objectifs purement hors ligne, car ils peuvent réallouer plus rapidement la masse de probabilité vers les régions préférées. Il ne s’agit pas d’une défense inconditionnelle du PPO. C’est un rappel que les informations en ligne peuvent avoir de l’importance lorsque les propres erreurs de la politique actuelle ne sont pas représentées dans les données statiques (ajustement fin des préférences sur politique).
C’est ici que le slogan DPO contre PPO montre généralement ses limites. Si le comportement cible est stable et bien représenté dans les données de préférences, le DPO permet d’obtenir la plupart des gains pratiques avec une complexité moindre. Si l’on s’attend à ce que le modèle adopte de nouveaux comportements, de nouveaux régimes de prompts ou des segments adversariaux après l’entraînement, l’équipe a toujours besoin de données sur politique, de RL en ligne, d’échantillonnage de rejet ou d’une actualisation ciblée des données.
Contrastes empiriques derrière le slogan
La bonne interprétation des preuves n’est pas « DPO a perdu » ou « PPO a gagné ». C’est que le DPO a davantage modifié l’optimiseur que l’épistémologie. De meilleures données de préférence, la couverture de la politique actuelle, le transfert du modèle de récompense et la fiabilité des juges dominent souvent l’image de marque de l’algorithme.
Les preuves publiques favorisent une lecture conditionnelle : le DPO est souvent plus simple et solide, tandis que la qualité des données, la couverture et la validité de l'évaluateur décident encore du transfert.
| Étude/rapport | Configuration | Résultat clé | Implication pour la mesure |
|---|---|---|---|
| Article DPO | DPO face au RLHF basé sur PPO. | Le DPO a égalé ou amélioré la qualité du résumé et du dialogue tout en étant plus simple à entraîner. | Explique l'adoption du DPO sans prouver que la mesure est résolue. |
| Unpacking DPO and PPO | Recettes contrôlées d'apprentissage des préférences. | PPO a dépassé le DPO dans certains régimes mathématiques et généraux, tandis que la qualité des données a davantage déplacé les résultats. | Le choix de l'algorithme peut compter moins que la validité des données. |
| Ajustement fin de préférences on-policy | Méthodes contrastives hors ligne face aux méthodes en ligne ou à gradient négatif. | L'échantillonnage on-policy peut surpasser des objectifs purement hors ligne. | Les échecs de couverture peuvent rendre l'information en ligne précieuse. |
| RewardBench 2 | Score de benchmark face à l'usage en aval. | La corrélation best-of-N était forte, mais le transfert PPO dépendait de la lignée et de la distribution. | Le rang de benchmark seul n'est pas une preuve de transfert. |
| JudgeBench | Évaluation de juges LLM. | Les juges forts ont peiné sur des paires de réponses objectives difficiles. | L'évaluation automatisée peut devenir le goulot d'étranglement après simplification de l'optimisation. |
Article DPO
- Configuration
- DPO face au RLHF basé sur PPO.
- Résultat clé
- Le DPO a égalé ou amélioré la qualité du résumé et du dialogue tout en étant plus simple à entraîner.
- Implication pour la mesure
- Explique l'adoption du DPO sans prouver que la mesure est résolue.
Unpacking DPO and PPO
- Configuration
- Recettes contrôlées d'apprentissage des préférences.
- Résultat clé
- PPO a dépassé le DPO dans certains régimes mathématiques et généraux, tandis que la qualité des données a davantage déplacé les résultats.
- Implication pour la mesure
- Le choix de l'algorithme peut compter moins que la validité des données.
Ajustement fin de préférences on-policy
- Configuration
- Méthodes contrastives hors ligne face aux méthodes en ligne ou à gradient négatif.
- Résultat clé
- L'échantillonnage on-policy peut surpasser des objectifs purement hors ligne.
- Implication pour la mesure
- Les échecs de couverture peuvent rendre l'information en ligne précieuse.
RewardBench 2
- Configuration
- Score de benchmark face à l'usage en aval.
- Résultat clé
- La corrélation best-of-N était forte, mais le transfert PPO dépendait de la lignée et de la distribution.
- Implication pour la mesure
- Le rang de benchmark seul n'est pas une preuve de transfert.
JudgeBench
- Configuration
- Évaluation de juges LLM.
- Résultat clé
- Les juges forts ont peiné sur des paires de réponses objectives difficiles.
- Implication pour la mesure
- L'évaluation automatisée peut devenir le goulot d'étranglement après simplification de l'optimisation.
Synthèse OpenTrain à partir des sources citées sur le DPO, le PPO, RewardBench 2, la sélection des données et l'évaluation des juges.
Ivison et al. ont trouvé des avantages au PPO dans certains régimes contrôlés tout en montrant que la qualité des données de préférence pouvait faire progresser le respect des instructions et la véracité davantage que le changement d’optimiseur lui-même (Unpacking DPO and PPO). Les travaux centrés sur les données aboutissent à la même conclusion pratique. Filtered DPO, Less is More et les jeux de données de type HelpSteer soulignent tous la même contrainte : la distribution des données et le protocole d’étiquetage choisis peuvent dominer la taille brute du jeu de données ou le nom de l’optimiseur (Filtered DPO, Less is More, HelpSteer3-Preference).
Là où la mesure échoue en premier
Le mode d’échec le plus utile n’est pas le détournement de récompense abstrait. Il s’agit du transfert mal prédit : l’objectif de préférence hors ligne semble bon sur une métrique alignée sur l’entraînement, mais le système en aval échoue sur le comportement qui compte vraiment pour l’équipe.
RewardBench 2 en est un exemple public clair. Il a été construit autour de prompts humains inédits et d’un format best-of-4 plus difficile. Les scores étaient en moyenne inférieurs d’environ 20 points à ceux du RewardBench original. Le benchmark était fortement corrélé à l’utilisation en aval best-of-N, avec une corrélation de Pearson de 0.87, mais ce n’était qu’un signal utile, pas une preuve de transfert suffisante pour le PPO. Dans les expériences PPO de l’article, un modèle de récompense hors politique avec un score RewardBench 2 de 72.9 a atteint un score PPO de 54.5, tandis qu’un modèle de récompense sur politique avec un score RewardBench 2 de 68.7 a atteint un score PPO de 59.8 (RewardBench 2).
Les travaux d’évaluation des modèles de récompense sur la suroptimisation vont dans le même sens. Si le benchmark n’approxime pas la pression d’optimisation que subira la politique, un score élevé au benchmark pourrait en apprendre moins à l’équipe qu’elle ne le pense (évaluation du modèle de récompense, suroptimisation de la récompense).
Une troisième version apparaît dans les retours humains eux-mêmes. Une étude de 2024 sur Anthropic-HH a révélé des tranches substantielles de faible accord ou de désaccord par rapport à un comité de modèles de récompense, et son modèle de données nettoyées a amélioré le comportement DPO en aval dans le cadre de l’évaluation de l’article. Ce n’est pas la preuve qu’un comité de modèles de récompense équivaut à la vérité terrain. C’est la preuve que les données de préférence fixes ne sont pas un monolithe (fiabilité des retours humains).
Les juges et les modèles de récompense ont toujours besoin de diagnostics
Une fois que les équipes cessent d’entraîner un modèle de récompense explicite pour le PPO, elles accordent souvent plus de confiance aux juges LLM ou à des ensembles de préférences statiques. Cela peut masquer la même erreur de mesure derrière un optimiseur plus propre.
JudgeBench a montré que des juges performants tels que GPT-4o ne faisaient qu’un peu mieux que le hasard sur des paires de réponses objectives difficiles en matière de connaissances, de raisonnement, de mathématiques et de codage. Le Judge Reliability Harness de 2026 de RAND a élargi le propos : aucun juge testé n’était uniformément fiable sur l’ensemble des benchmarks, et des perturbations telles que des changements de formatage, des paraphrases, des variations de verbosité et des inversions d’étiquettes ont provoqué des variations de fiabilité significatives (JudgeBench, Judge Reliability Harness).
La littérature sur les biais rend cela plus évident. Les évaluateurs LLM peuvent reconnaître et favoriser leurs propres générations. Les juges par paires peuvent présenter un biais de position, une dépendance à la tâche et des segments difficiles propices aux désaccords. Length-Controlled AlpacaEval est un bon exemple du domaine corrigeant un artefact de mesure plutôt que d’améliorer simplement un optimiseur (auto-préférence, biais de position, Length-Controlled AlpacaEval).
La leçon en matière d’atténuation n’est pas que les juges automatisés sont inutilisables. C’est qu’un juge est un instrument. Il nécessite des vérifications d’instrument : inversions de position, invariance de paraphrase, contrôles de verbosité, échantillonnage répété et éléments d’ancrage avec des étiquettes connues.
Les stacks de production publics restent multi-étapes
Les preuves publiques des principaux producteurs de modèles vont dans le même sens. Le rapport de post-entraînement du Llama 3.1 de Meta indique que chaque cycle d’alignement impliquait du SFT, de l’échantillonnage de rejet et du DPO. Qwen2.5 fait état d’un SFT à grande échelle et d’un apprentissage par renforcement multi-étapes. DeepSeek-R1 décrit deux étapes de RL, des données de démarrage à froid, de l’échantillonnage de rejet et une expansion ultérieure de la supervision. Tulu 3 combine le SFT, des données de préférence on-policy sélectionnées pour le DPO, la modélisation des récompenses, le RL avec des récompenses vérifiables, la décontamination et des suites de développement séparées des suites d’évaluation inédites (Llama 3.1, Qwen2.5, DeepSeek-R1, Tulu 3).
La formulation appropriée est une déduction à partir de preuves publiques, et non un fait universel concernant chaque stack de pointe fermé. Mais la déduction est forte : les stacks publics très performants ne considèrent pas le DPO comme une raison d’arrêter d’investir dans l’évaluation, l’actualisation des données on-policy, l’échantillonnage de rejet ou les étapes de RL ciblées. Ils utilisent le DPO comme une étape au sein d’un système de post-entraînement plus vaste.
Un modèle d’implémentation pratique
Un modèle de post-entraînement techniquement défendable en 2026 ressemble moins à « choisir DPO ou PPO » et davantage à une conception de mesure par étapes.
Premièrement, les équipes ont besoin d’un jeu de données de préférences calibré pour le cas d’utilisation cible plutôt que simplement volumineux. Si la source de données est hétérogène, segmentez-la par source d’évaluation, famille de prompts, type de tâche et régime de bruit probable avant de formuler des affirmations sur l’entraînement.
Deuxièmement, les équipes ont besoin de diagnostics d’évaluateur avant d’utiliser un modèle de récompense ou un juge LLM en tant qu’entraîneur ou évaluateur. Au minimum, cela implique des vérifications d’échange de position, des vérifications d’invariance de paraphrase et de formatage, des vérifications de biais de verbosité, une stabilité d’échantillonnage répété et un petit ensemble d’ancrage vérifié par des humains.
Troisièmement, les équipes ont besoin d’une véritable évaluation de transfert. L’ensemble de validation ne se limite pas aux paires de préférences mises de côté. Il devrait inclure des prompts inédits, des segments contradictoires, des segments de test de résistance pour les juges et, dans la mesure du possible, un segment on-policy ou quasi on-policy produit par le modèle actuel.
Quatrièmement, les équipes doivent décider si les données en ligne sont nécessaires en diagnostiquant la couverture, et non par idéologie. Si les échecs d’évaluation se concentrent sur les sorties de la politique actuelle, ou si le modèle évolue vers des régimes de raisonnement ou de sécurité non représentés dans le jeu de données, la collecte en ligne, l’échantillonnage de rejet ou le RL peuvent toujours s’avérer être le moyen le moins cher d’obtenir une amélioration fiable.
La conclusion pratique est ciblée mais forte. Le DPO doit être traité comme une substitution d’optimiseur, et non comme une substitution d’évaluation. Il supprime souvent la machinerie coûteuse d’optimisation en ligne. Il ne supprime pas la nécessité de savoir si l’objectif de préférence choisi, le processus d’étiquetage, le modèle de récompense ou le juge se transfèrent réellement.
OpenTrain peut sourcer des évaluateurs spécialistes et des opérateurs de données de préférence dans la stack qu’une équipe utilise déjà. Utilisez la référence de fiabilité des juges LLM pour le contexte de calibration des évaluateurs, le guide de cadrage RLHF pour la planification des données de préférence, et publiez une offre d’emploi lorsque le goulot d’étranglement est le recrutement pour la boucle de révision.
Sources
- Optimisation directe des préférences
- Entraînement de modèles de langage pour suivre des instructions avec des retours humains
- Entraînement d’un assistant utile et inoffensif avec RLHF
- Décryptage du DPO et du PPO
- Réglage fin des préférences avec des données on-policy sous-optimales
- L’importance des données en ligne
- RewardBench 2
- Évaluation du modèle de récompense
- Suroptimisation de la récompense
- JudgeBench
- Harnais de fiabilité du juge
- Les évaluateurs LLM reconnaissent et favorisent leurs propres générations
- Juger les juges
- Optimisation directe des préférences filtrée
- Moins, c’est plus
- HelpSteer3-Preference
- Llama 3.1
- Rapport technique Qwen2.5
- Tulu 3
- DeepSeek-R1
- KTO
- ORPO
- SimPO
- AlpacaEval contrôlé par la longueur