Les juges LLM sont des systèmes de mesure, pas des oracles

Référence technique sur la fiabilité des juges LLM pour les évaluations de production et le post-entraînement, avec calibration, audit et contrôle.
Les juges LLM sont utilisables en production, mais uniquement en tant que systèmes de mesure versionnés, calibrés et audités. La tension centrale réside dans le fait que le cas de réussite le plus cité du domaine, GPT-4 atteignant plus de 80% de concordance avec les préférences humaines sur MT-Bench et Chatbot Arena, côtoie désormais de nouvelles preuves montrant des échecs de transfert marqués dès que la combinaison de tâches, la construction du benchmark, la métrique ou la famille de juges change (MT-Bench and Chatbot Arena, Arena-Hard, JUDGE-BENCH, JudgeBench).
Ces résultats ne sont pas contradictoires. Ils décrivent ce qui se produit lorsqu’un juge est traité comme une source de vérité portable au lieu d’un instrument calibré.
Les premiers résultats de concordance étaient locaux au benchmark, et non universels
Les premiers résultats positifs étaient réels. MT-Bench et Chatbot Arena ont établi que des juges par paires performants peuvent approximer les jugements de préférence humaine sur de larges comparaisons de type chat. G-Eval a montré que le jugement structuré de GPT-4 pouvait surpasser les anciennes métriques automatiques sur le résumé, tout en mettant en garde contre le biais de l’évaluateur envers le texte généré par LLM (G-Eval). Prometheus 2 a par la suite montré que les modèles d’évaluateurs ouverts peuvent s’améliorer considérablement en tant que modèles de juges dédiés avec des critères définis par l’utilisateur (Prometheus 2).
Cette combinaison a son importance. Cela signifie que le domaine n’a pas prouvé qu’« un juge LLM fonctionne » dans l’absolu. Il a prouvé des affirmations plus restreintes : un juge peut suivre une distribution particulière de préférences humaines, sur une famille de benchmarks particulière, selon un schéma de prompt et d’agrégation particulier.
AlpacaEval soulève le même point sous un autre angle. Son taux de victoire contrôlé par la longueur a augmenté la corrélation avec Chatbot Arena et réduit la possibilité de manipuler la longueur, mais ses mainteneurs mettent toujours en garde contre l’utilisation d’évaluateurs automatiques seuls pour les décisions de publication. Un juge peut être utile pour le développement itératif tout en restant faible en tant que validation finale.
Les méta-évaluations plus strictes ont brisé le mythe de la portabilité
Arena-Hard a rendu le problème de portabilité concret. Il a été conçu à partir de données réelles issues du crowdsourcing pour améliorer la séparabilité entre les modèles performants ajustés par instructions, et les auteurs ont rapporté une forte concordance avec Chatbot Arena à faible coût. Dans la même étude, MT-Bench pouvait encore préserver un ordre de classement approximatif tout en échouant beaucoup plus lourdement sur la séparabilité. C’est exactement le décalage de métrique qui brise le raisonnement de validation de publication : un benchmark peut classer des candidats et tout de même échouer à séparer des systèmes proches de l’état de l’art de manière suffisamment précise pour prendre des décisions de déploiement.
JUDGE-BENCH a élargi le problème à 20 tâches d’évaluation NLP et 11 modèles juges. Les modèles ayant le plus grand nombre de réponses valides ont obtenu en moyenne une concordance corrigée du hasard modeste, avec une très grande variance selon le jeu de données. GPT-4o pouvait sembler performant sur un segment et proche de zéro ou négatif sur un autre. Le même article a révélé que les juges s’alignaient mieux avec les annotations de non-experts qu’avec celles d’experts, et mieux avec le langage généré par des humains qu’avec le texte généré par des machines.
JudgeBench est allé encore plus loin en s’éloignant de l’alignement stylistique ou des préférences de la foule pour se tourner vers l’exactitude objective dans les domaines des connaissances, du raisonnement, des mathématiques et du codage. Son résumé indique que de nombreux juges performants, y compris GPT-4o, ne font qu’un peu mieux que des suppositions aléatoires sur les paires de réponses plus difficiles. IF-RewardBench étend la critique à l’évaluation du suivi des instructions en affirmant que la méta-évaluation uniquement par paires est désalignée avec les flux de travail de classement par listes utilisés dans l’optimisation (IF-RewardBench).
Benchmark snapshots show transfer limits
| Benchmark | Evaluation regime | Reliability implication |
|---|---|---|
| MT-Bench / Chatbot Arena | Pairwise chat preference judgments | Strong benchmark-local agreement does not imply universal transfer. |
| Arena-Hard | Harder separability from live arena data | Benchmark construction changes what agreement means. |
| JUDGE-BENCH | 20 NLP tasks and 11 judge models | Chance-corrected and rank metrics vary substantially by task. |
| JudgeBench | Objective correctness across reasoning domains | Correctness-heavy tasks expose weak transfer from preference-style judging. |
MT-Bench / Chatbot Arena
- Evaluation regime
- Pairwise chat preference judgments
- Reliability implication
- Strong benchmark-local agreement does not imply universal transfer.
Arena-Hard
- Evaluation regime
- Harder separability from live arena data
- Reliability implication
- Benchmark construction changes what agreement means.
JUDGE-BENCH
- Evaluation regime
- 20 NLP tasks and 11 judge models
- Reliability implication
- Chance-corrected and rank metrics vary substantially by task.
JudgeBench
- Evaluation regime
- Objective correctness across reasoning domains
- Reliability implication
- Correctness-heavy tasks expose weak transfer from preference-style judging.
OpenTrain synthesis from cited benchmark and meta-evaluation sources.
Métriques de fiabilité corrigées du hasard
Le pourcentage de concordance est un argument de publication faible en soi. Si l’équilibre des étiquettes est asymétrique, un juge peut souvent être d’accord tout en ajoutant peu d’informations. Pour l’évaluation catégorielle, la concordance corrigée du hasard a sa place à côté de la concordance principale.
Les biais et les effets de famille de juges créent des erreurs structurées
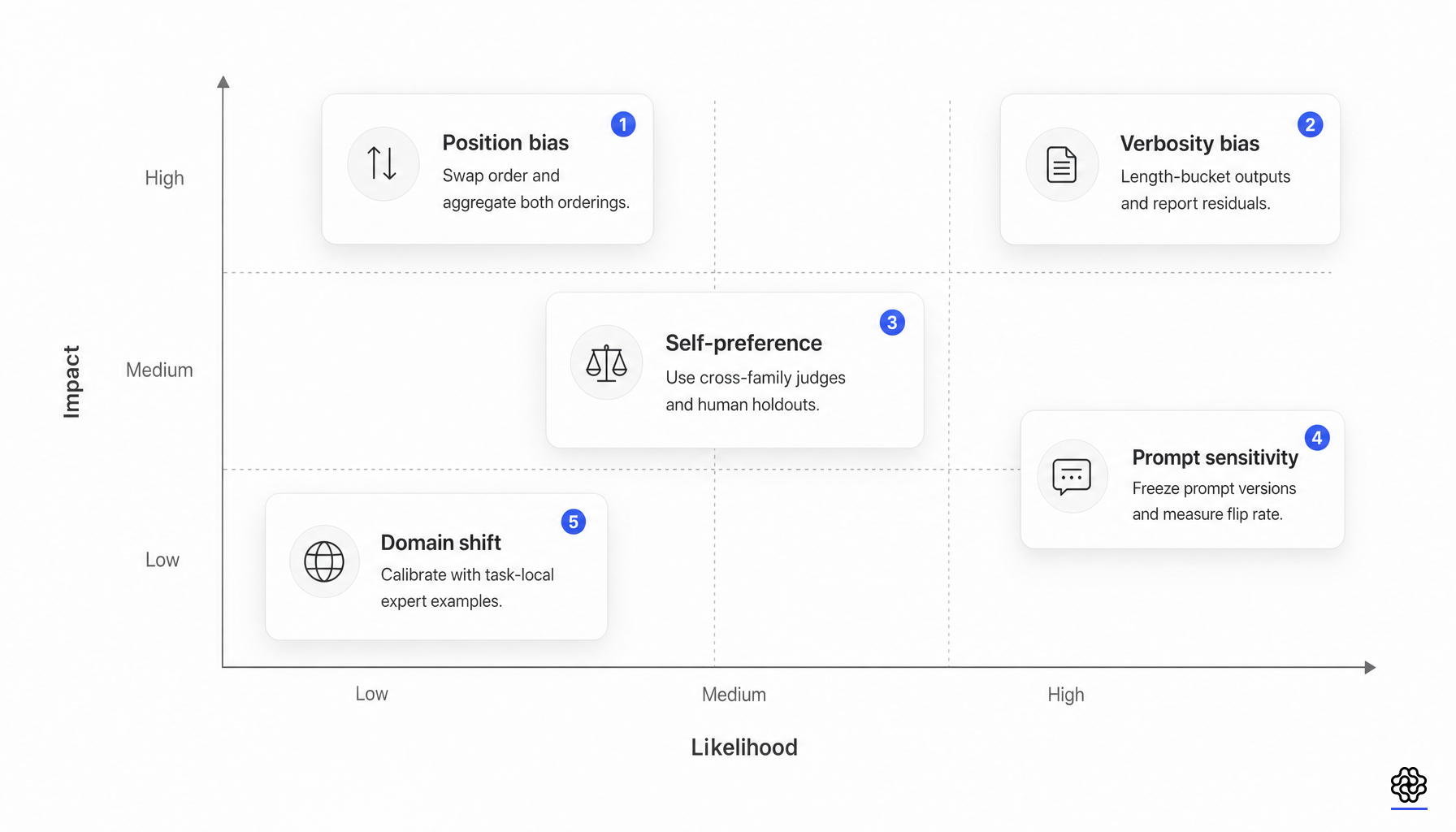
La mise à jour de fiabilité la plus importante du domaine est que le biais n’est plus une note de bas de page. C’est une source mesurable d’erreur structurée.
Les travaux sur le biais de position ont dépassé le stade de l’anecdote. Une étude systématique sur MTBench et DevBench a introduit la stabilité de répétition, la cohérence de position et l’équité des préférences, a analysé plus de 100,000 instances d’évaluation et a révélé que le biais de position n’est pas le fruit du hasard (position bias study). L’identité du juge, la catégorie de tâche et l’écart de qualité des réponses ont tous de l’importance.
L’auto-préférence est tout aussi importante car elle associe l’évaluation à la famille de modèles. Une série de travaux a montré que les évaluateurs LLM peuvent reconnaître et favoriser leurs propres générations ; une étude ultérieure a lié l’auto-préférence de GPT-4 à la familiarité et à une perplexité moindre plutôt qu’à une simple vanité (self-recognition, self-preference). Cela a de l’importance chaque fois que le juge, la politique et le générateur de données proviennent de la même famille ou partagent un style post-entraînement similaire.
La conception des références modifie à nouveau le mode de défaillance. « No Free Labels » a révélé que la capacité d’un juge à répondre à une question est liée à sa capacité à évaluer les réponses à cette question, et qu’un juge plus faible avec des références humaines plus solides peut battre un juge plus fort avec des références synthétiques (No Free Labels). Les conclusions sur les ensembles vont dans le même sens : des panels de juges diversifiés peuvent réduire le biais d’une seule famille et coûter moins cher qu’un seul grand juge dans certains contextes (Replacing Judges with Juries).
En post-entraînement, la qualité de la récompense ne vaut que par la calibration du juge
Une fois que le juge passe de l’évaluation à l’entraînement, l’erreur de mesure devient une erreur d’optimisation. RewardBench a initialement plaidé pour l’évaluation directe du modèle de récompense via des triplets de prompt, choisi et rejeté. RewardBench 2 a mis à jour cette approche avec un benchmark plus difficile construit à partir de prompts humains pour la plupart inédits, six domaines, 1,865 prompts, des complétions provenant de 20 modèles ou humains, une configuration de notation best-of-4, et un sous-ensemble d’égalités destiné à tester la calibration entre des réponses équivalentes et valides (RewardBench 2, dataset card).
RewardBench 2 est utile car il résiste à une vision simpliste du transfert des scores de benchmark vers l’entraînement. L’article montre une forte corrélation avec les performances d’échantillonnage best-of-N, mais il indique également que la corrélation PPO RLHF est affectée par des facteurs spécifiques au contexte. Les scores de benchmark de récompense basés sur la précision sont une condition préalable à un entraînement RLHF solide, mais ils ne sont pas suffisants.
De meilleurs signaux de juge peuvent aider lorsqu’ils sont utilisés avec précaution. Le raisonnement comparatif participatif augmente le jugement par paires avec des réponses supplémentaires de la foule et montre des gains sur les benchmarks de préférence, y compris des améliorations en aval de l’échantillonnage par rejet (Crowd Comparative Reasoning). La leçon n’est pas que le calcul supplémentaire du temps de juge résout la fiabilité. C’est que des protocoles de jugement plus riches peuvent améliorer le signal de mesure utilisé pour la sélection et le filtrage.
La documentation officielle des produits reflète désormais la même réalité. La documentation sur les évaluateurs d’OpenAI traite les évaluateurs comme des objets de première classe pour les évaluations et le fine-tuning par renforcement, recommande de tester les évaluateurs par rapport à des exemples humains et de modèles de haute qualité, et définit le piratage d’évaluateur (grader hacking) comme le cas où un modèle obtient un score élevé aux évaluations de l’évaluateur mais faible aux évaluations d’experts humains (OpenAI graders, reinforcement fine-tuning cookbook). Le mode de défaillance est simple : l’équipe intègre un juge dans la boucle avant de valider si le score reste aligné une fois que la politique commence à s’optimiser par rapport à lui.
Where judge signals enter post-training
| Workflow stage | Judge artifact | Minimum control |
|---|---|---|
| Eval-only regression testing | Versioned judge prompt over a calibration set | Track drift, slice deltas, and chance-corrected agreement. |
| Rejection sampling | Pairwise, listwise, or verifier score | Audit whether selection improves human-preferred outputs on target slices. |
| Reward-model benchmarking | Reward model or judge ensemble | Separate benchmark score from downstream PPO or best-of-N behavior. |
| RFT / RLHF grading | Rubric grader or reward signal | Run small-scale validation before scaling optimization. |
| Release gating | Calibrated judge score plus human audit | Require uncertainty bounds, disagreement limits, and slice checks. |
Eval-only regression testing
- Judge artifact
- Versioned judge prompt over a calibration set
- Minimum control
- Track drift, slice deltas, and chance-corrected agreement.
Rejection sampling
- Judge artifact
- Pairwise, listwise, or verifier score
- Minimum control
- Audit whether selection improves human-preferred outputs on target slices.
Reward-model benchmarking
- Judge artifact
- Reward model or judge ensemble
- Minimum control
- Separate benchmark score from downstream PPO or best-of-N behavior.
RFT / RLHF grading
- Judge artifact
- Rubric grader or reward signal
- Minimum control
- Run small-scale validation before scaling optimization.
Release gating
- Judge artifact
- Calibrated judge score plus human audit
- Minimum control
- Require uncertainty bounds, disagreement limits, and slice checks.
OpenTrain synthesis from RewardBench 2, OpenAI grader guidance, RLAIF literature, and recent rubric-based post-training work.
Une stack de juge en production nécessite une calibration, un versionnage et une escalade humaine
Les documents publics d’OpenAI et d’Anthropic suggèrent que les équipes de pointe traitent les juges comme des composants dans des stacks de mesure en couches, et non comme des autorités de publication autonomes. OpenAI expose les évaluateurs dans le cadre des flux de travail d’évaluation et de fine-tuning par renforcement. Anthropic rapporte qu’un seul juge LLM peut être cohérent pour les composants à réponse claire d’un système de recherche, tout en affirmant que les tests humains restent essentiels car les personnes détectent les hallucinations, les défaillances du système et les erreurs de qualité des sources que l’automatisation manque (Anthropic engineering).
La littérature plus récente sur la calibration converge vers le même cadre. SLMEval avance que plusieurs évaluateurs calibrés échouent sur des tâches ouvertes du monde réel et rapporte une amélioration pour des cas d’usage en production en utilisant de petites quantités de données de préférence humaine associées à une calibration basée sur l’entropie (SLMEval). Un article sur la fiabilité basée sur l’IRT sépare la cohérence intrinsèque, qui évalue si le juge se comporte de manière stable face aux variations de prompt, de l’alignement humain, qui évalue si ce comportement stable est réellement aligné avec les évaluations de qualité humaines (IRT reliability).
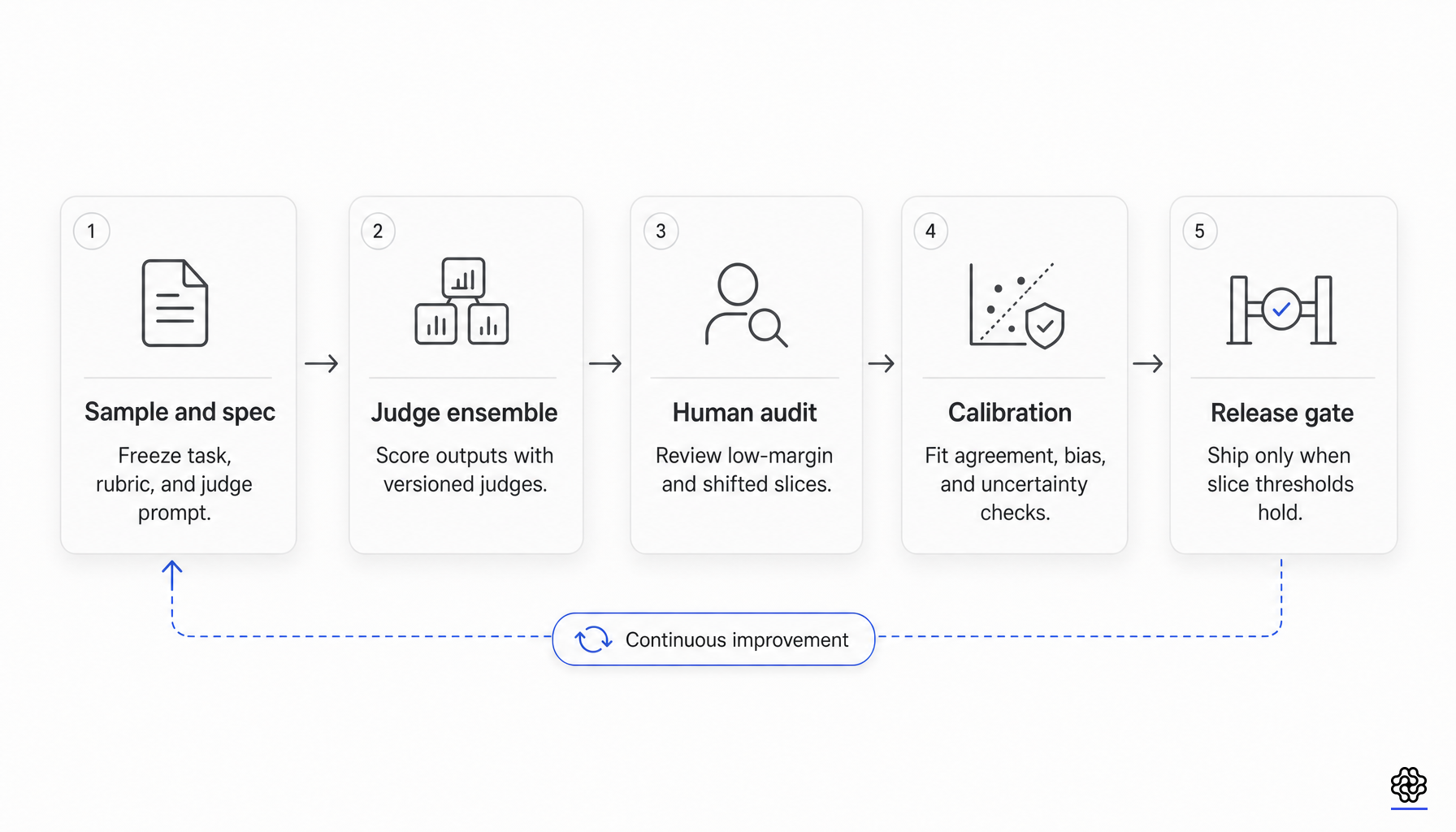
Un anti-modèle concret de validation de déploiement découle de ces éléments : utiliser un score moyen unique de juge ou un taux de victoire par paires comme seuil d’acceptation universel. Cela suppose une invariance de mesure que les données actuelles ne confirment pas. Un meilleur contrat minimal est plus ciblé et explicitement audité :
- Figer la version du modèle juge, le prompt du juge, le texte de la grille d’évaluation, la politique de référence, la règle de gestion des ex æquo et la logique d’agrégation.
- Maintenir un ensemble de calibration étiqueté par des humains pour la distribution exacte du déploiement, y compris les segments à haut risque.
- Fournir au moins une métrique d’accord corrigée du hasard, ainsi qu’une métrique de rang ou de séparabilité.
- Auditer les effets d’ordre, les effets de style et de longueur, la préférence pour sa propre famille de modèles et la sensibilité à la référence.
- Séparer la sélection de la récompense lors de l’entraînement de l’acceptation lors du déploiement.
- Transmettre les segments à faible marge, à fort désaccord ou ayant récemment dévié à un arbitrage humain.
La limite pratique
L’implication pratique pour les équipes de production est étroite, mais reste forte. Les juges LLM sont utiles là où l’évaluation humaine est trop lente ou trop coûteuse pour être exécutée en continu, où la cible d’évaluation est ouverte, et où l’équipe est prête à consacrer de réels efforts à la calibration, aux audits de biais et aux files d’attente d’arbitrage humain.
Ce ne sont pas des compteurs de vérité portables. C’est une infrastructure de mesure. Les équipes qui les traitent de cette façon peuvent les utiliser pour la détection quotidienne de régressions, le filtrage de candidats, la sélection de modèles de récompense et l’escalade humaine sélective. Les équipes qui ne le font pas finiront par optimiser dans leurs angles morts.
OpenTrain peut trouver des arbitres humains spécialistes pour les ensembles de calibration, les tranches d’audit et les vérifications de dérive au sein de la pile d’évaluation qu’une équipe utilise déjà. Commencez par le service géré lorsque le goulot d’étranglement est l’exploitation de la boucle de révision, ou publiez une offre d’emploi lorsque l’équipe souhaite embaucher directement.
Sources
- MT-Bench and Chatbot Arena
- G-Eval
- AlpacaEval
- Arena-Hard
- JUDGE-BENCH
- JudgeBench
- IF-RewardBench
- Biais de position dans LLM en tant que juge
- Auto-reconnaissance et auto-préférence
- Pas d’étiquettes gratuites
- RewardBench 2
- Évaluateurs OpenAI
- Guide pratique d’OpenAI sur le fine-tuning par renforcement
- Système de recherche multi-agents d’Anthropic
- SLMEval
- Diagnostiquer la fiabilité via la théorie de la réponse à l’item