Comment cadrer un programme de données RLHF

Cadre pratique pour lancer un programme RLHF : définir les files, dimensionner les évaluateurs, budgétiser la révision et fixer des jalons hebdomadaires.
La plupart des premiers programmes de données RLHF échouent au niveau de la couche humaine, et non de la boucle PPO. Les erreurs coûteuses sont courantes : une grille d’évaluation qui mélange la sécurité, la factualité, le style et la réussite de la tâche en un seul clic ; aucune étape de calibration avant l’étiquetage en production ; et un budget qui suppose que chaque paire de préférences a le même coût. Les exemples publics vont des premiers travaux d’OpenAI sur le backflip, qui ont utilisé environ 900 bits de retour d’information en moins d’une heure de temps d’évaluation, à la version HH-RLHF d’Anthropic avec 169,352 lignes choisies/rejetées (OpenAI, Anthropic HH-RLHF dataset). La portée doit provenir de la géométrie de la tâche, et non de la copie d’un chiffre phare d’un laboratoire de pointe.
Que jugent réellement les humains ?
Commencez par une question plus précise que « quelle réponse est la meilleure ? ». InstructGPT a séparé les démonstrations supervisées, les comparaisons de modèles de récompense et les invites pour l’optimisation de la politique ; ces produits de données enseignent différentes parties du système (InstructGPT). Les démonstrations enseignent le format et l’accomplissement de la tâche. Les paires de préférences enseignent le jugement relatif. Les pools d’invites décident de ce que le modèle ajusté voit pendant l’entraînement.
Pour un premier ou un deuxième programme, divisez le travail en trois files d’attente :
- File d’attente de succès : les invites pour lesquelles le modèle a généralement raison et nécessite des vérifications de préférence occasionnelles.
- File d’attente des limites : les cas limites où le comportement dérive en matière de politique, de sécurité, de factualité ou de style.
- File d’attente de récupération : les cas contradictoires ou à haut risque où une mauvaise réponse coûte cher.
Cette division des files d’attente détermine quel produit d’annotation acheter en premier. Si vous avez besoin de préférences par paires, orientez le programme vers RLHF et données de préférence. Si l’échec se trouve à l’intérieur de la réponse, collectez des étiquettes à l’intérieur de la réponse. Les travaux de supervision de processus d’OpenAI ont publié PRM800K avec environ 800,000 étiquettes au niveau des étapes et ont révélé que la supervision de processus surpassait la supervision de résultats sur le paramètre MATH évalué (Let’s Verify Step by Step). Pour les mathématiques, le raisonnement sur le code et l’utilisation d’outils à plusieurs étapes, la préférence par paires seule est souvent trop grossière.
Quelle quantité de données est suffisante pour le premier cycle sérieux ?
Utilisez les programmes publics comme modèles de fonctionnement, et non comme quotas. Les travaux de résumé d’OpenAI ont utilisé 64,832 comparaisons de résumés ; InstructGPT a signalé environ 13,000 prompts supervisés, environ 33,000 prompts de modèle de récompense et environ 40 sous-traitants sélectionnés ; PRM800K était beaucoup plus vaste car chaque unité de supervision était un jugement par étape plus petit (summarization from human feedback, InstructGPT, PRM800K).
Public RLHF program shapes
| Public program | Human-feedback footprint | What it tells you |
|---|---|---|
| OpenAI backflip | About 900 bits of feedback, under 1 hour of evaluator time, and about 70 hours of simulated experience. | Very narrow objectives can justify tiny pilots if the task is easy to judge. |
| OpenAI summarization | 64,832 summary comparisons. | A single-task text-alignment program reaches tens of thousands quickly once you want stable reward modeling. |
| InstructGPT | About 13k SFT prompts, 33k reward-model prompts, and about 40 contractors. | Assistant alignment usually needs multiple queues, not one annotation type. |
| Anthropic HH-RLHF | 169,352 chosen and rejected rows in the released dataset; the underlying training setup used weekly online refresh with fresh human feedback. | Conversational post-training benefits from refresh loops, not one static batch. |
| OpenAI process supervision | PRM800K with 800,000 step-level labels; the process-supervised model solved 78% of a representative MATH subset. | Step-level labels are only worth the cost when intermediate correctness is the real bottleneck. |
OpenAI backflip
- Human-feedback footprint
- About 900 bits of feedback, under 1 hour of evaluator time, and about 70 hours of simulated experience.
- What it tells you
- Very narrow objectives can justify tiny pilots if the task is easy to judge.
OpenAI summarization
- Human-feedback footprint
- 64,832 summary comparisons.
- What it tells you
- A single-task text-alignment program reaches tens of thousands quickly once you want stable reward modeling.
InstructGPT
- Human-feedback footprint
- About 13k SFT prompts, 33k reward-model prompts, and about 40 contractors.
- What it tells you
- Assistant alignment usually needs multiple queues, not one annotation type.
Anthropic HH-RLHF
- Human-feedback footprint
- 169,352 chosen and rejected rows in the released dataset; the underlying training setup used weekly online refresh with fresh human feedback.
- What it tells you
- Conversational post-training benefits from refresh loops, not one static batch.
OpenAI process supervision
- Human-feedback footprint
- PRM800K with 800,000 step-level labels; the process-supervised model solved 78% of a representative MATH subset.
- What it tells you
- Step-level labels are only worth the cost when intermediate correctness is the real bottleneck.
OpenTrain synthesis from cited public sources.
La première règle est de faire un essai pilote avant de passer à l’échelle. RewardBench rapporte que certains ensembles de test de données de préférence ont une précision plafond humaine de l’ordre de 60-70%, ce qui signifie que le désaccord peut être une propriété de la tâche plutôt qu’une défaillance de la capacité de l’évaluateur (RewardBench). Si l’accord de votre pilote est mauvais, ajoutez des spécifications avant d’ajouter des postes.
La deuxième règle est d’augmenter la densité d’information avant le nombre de prompts. InstructGPT a demandé aux annotateurs de classer 4 à 9 sorties pour un prompt, ce qui a créé plus d’informations de comparaison par prompt qu’un simple choix binaire (InstructGPT). C’est souvent une meilleure première étape que de doubler le groupe d’évaluateurs sur une grille d’évaluation instable.
De combien d’évaluateurs avez-vous réellement besoin ?
Le nombre d’évaluateurs est un calcul de capacité de traitement avec une marge de désaccord :
Utilisez les chiffres de votre pilote pour le dénominateur. L’utilisation productive inclut tout ce qui prend du temps sur l’étiquetage pur : mise à jour de la grille d’évaluation, arbitrage, contrôles ponctuels, réentraînement, pauses et friction liée aux outils.
Par exemple, supposons que le pilote montre 180 jugements calibrés par évaluateur et par semaine et que la prochaine mise à jour nécessite 3,000 jugements par semaine. À 70% d’utilisation productive, l’équipe de base est de ceil(3000 / 180 / 0.70) = 24 évaluateurs avant les marges de domaine, de langue, de fuseau horaire et de capacité de secours. Si la file d’attente nécessite quatre cellules domaine-langue, faites le calcul par cellule avant de regrouper le total.
Les points de repère publics ne sont utiles qu’à titre de vérification de cohérence. InstructGPT a fait état d’un accord entre les annotateurs de formation de 72.6 +/- 1.5% et d’un accord entre les annotateurs exclus de 77.3 +/- 1.3% ; les travaux de résumé d’OpenAI ont fait état d’un accord entre chercheurs de 73 +/- 4% (InstructGPT, summarization from human feedback). Ces chiffres ne sont pas des prescriptions quant au nombre d’évaluateurs. Ils rappellent qu’une petite équipe calibrée peut soutenir une exécution sérieuse, et qu’un désaccord dans la fourchette haute des 60 ou basse des 70 peut être normal lorsque la tâche est difficile.
La couverture compte tout autant que le nombre brut. Si la file d’attente couvre la médecine, la sécurité multilingue et la révision de code, vous dimensionnez des cellules domaine-langue, et non un seul bassin de main-d’œuvre commun. L’AI RMF du NIST appelle à des perspectives diverses dans la cartographie et la mesure des risques liés à l’IA ; son profil d’IA générative recommande également des exercices structurés de retour d’information humain avec des rôles et des parcours d’examen documentés (NIST AI RMF 1.0, NIST GenAI Profile).
Comment le budget doit-il être construit ?
Une grille tarifaire de source primaire pour les paires de préférences RLHF à travers les domaines, les langues et les conceptions de tâches n’est pas publiquement vérifiable. Établissez plutôt le budget à partir du travail chronométré :
Le poste budgétaire que les équipes oublient est le temps d’arbitrage et de recherche. L’article d’OpenAI sur le résumé indique que le jeu de données de retours humains a nécessité un nombre important d’heures d’annotateurs et de temps de chercheurs pour garantir la qualité (summarization from human feedback). C’est pourquoi les projets pilotes qui semblent bon marché sur un tableur deviennent coûteux une fois que la grille d’évaluation commence à changer.
Considérez les frais de recherche de talents et de place de marché comme distincts de la main-d’œuvre. OpenTrain publie des frais de 15% pour le libre-service et de 20% pour le service géré ; les équipes peuvent soit embaucher directement, soit utiliser le service géré lorsqu’elles souhaitent que OpenTrain gère les opérations du projet (tarification de OpenTrain). Cela a son importance lorsque le goulot d’étranglement est la recherche et la gestion d’une file d’attente calibrée, et non la conception de la mise à jour du modèle.
Quel calendrier devez-vous prévoir ?
Pensez en termes d’étapes de validation, et non en une seule phase d’annotation monolithique :
- Spécification : définissez la grille d’évaluation, les règles de désaccord et la procédure d’escalade.
- Calibrage : traitez des éléments d’exemple jusqu’à ce que l’arbitrage cesse de découvrir de nouvelles branches de la grille d’évaluation chaque jour.
- Pilote : annotez une file d’attente restreinte avec une révision stricte.
- Évaluation : exigez des négatifs difficiles dans l’ensemble d’évaluation.
- Actualisation : mettez à jour la grille d’évaluation et répétez l’opération à un rythme hebdomadaire ou basé sur les versions.
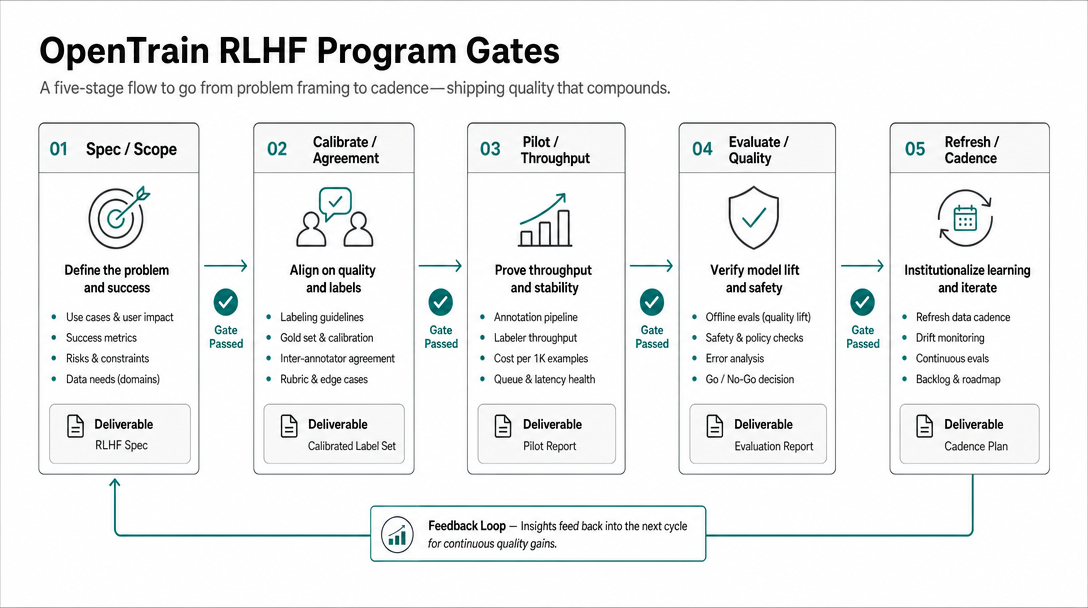
Le modèle de recherche publique soutient les boucles courtes. Les premiers travaux d’OpenAI sur les préférences humaines ont activement échantillonné des comparaisons où le modèle était incertain ; InstructGPT a utilisé des ensembles de données distincts pour les démonstrations, l’entraînement du modèle de récompense et l’optimisation de la politique ; les travaux sur Sparrow de DeepMind ont utilisé des jugements humains ciblés et une évaluation fondée sur des preuves ; l’article d’Anthropic sur l’assistant utile et inoffensif décrit la collecte itérative de données en ligne avec de nouveaux retours humains (OpenAI human preferences, InstructGPT, Sparrow, Anthropic HH-RLHF). Les premier et deuxième programmes devraient copier la boucle de fonctionnement, et non la taille de l’ensemble de données.
Comment la portée évolue-t-elle après la première exécution ?
Le premier programme doit acheter de la vitesse d’apprentissage. Un programme mature doit acheter de la répétabilité. Considérez-les comme des achats différents.
How RLHF scope changes after the first run
| Decision | First RLHF program | Second or mature program |
|---|---|---|
| Data target | Pilot the smallest queue that exposes rubric disagreement, task friction, and obvious reward-model failure modes. | Size weekly refresh batches from observed model drift, new product surfaces, and hard-negative mining. |
| Rater pool | Start with a small calibrated group and over-invest in adjudication notes. | Maintain domain-language cells, backup capacity, reviewer promotion paths, and attrition buffers. |
| QA | Review a high share of labels until the rubric stops changing daily. | Move to sampled review, gold items, disagreement dashboards, and scheduled rubric refresh. |
| Timeline | Gate on specification, calibration, pilot, evaluation, and a first refresh decision. | Gate on weekly or release-based refresh, eval regression checks, and queue-health metrics. |
| Sourcing model | Hire directly if the team can run calibration and adjudication. Use managed service if operating the queue is the bottleneck. | Keep a stable bench, add specialists only where the model or product surface changed, and separate sourcing fees from labor rates. |
| Success artifact | A usable rubric, an eval set with misses, and a rater-capacity model. | A repeatable operating cadence with known throughput, known disagreement bands, and a clear escalation path. |
Data target
- First RLHF program
- Pilot the smallest queue that exposes rubric disagreement, task friction, and obvious reward-model failure modes.
- Second or mature program
- Size weekly refresh batches from observed model drift, new product surfaces, and hard-negative mining.
Rater pool
- First RLHF program
- Start with a small calibrated group and over-invest in adjudication notes.
- Second or mature program
- Maintain domain-language cells, backup capacity, reviewer promotion paths, and attrition buffers.
QA
- First RLHF program
- Review a high share of labels until the rubric stops changing daily.
- Second or mature program
- Move to sampled review, gold items, disagreement dashboards, and scheduled rubric refresh.
Timeline
- First RLHF program
- Gate on specification, calibration, pilot, evaluation, and a first refresh decision.
- Second or mature program
- Gate on weekly or release-based refresh, eval regression checks, and queue-health metrics.
Sourcing model
- First RLHF program
- Hire directly if the team can run calibration and adjudication. Use managed service if operating the queue is the bottleneck.
- Second or mature program
- Keep a stable bench, add specialists only where the model or product surface changed, and separate sourcing fees from labor rates.
Success artifact
- First RLHF program
- A usable rubric, an eval set with misses, and a rater-capacity model.
- Second or mature program
- A repeatable operating cadence with known throughput, known disagreement bands, and a clear escalation path.
OpenTrain scoping model.
Où les programmes échouent-ils généralement ?
La plupart des échecs de qualité sont des échecs de mesure. RewardBench signale que certains sous-ensembles complexes restent difficiles pour les modèles de récompense, et que les désaccords humains peuvent limiter la fiabilité des benchmarks (RewardBench). Si une évaluation interne sature immédiatement, elle est probablement trop facile pour régir la prochaine mise à jour du modèle.
Pour les tâches liées à la factualité et sensibles aux politiques, facilitez le jugement pour l’évaluateur. Sparrow a joint des preuves aux affirmations factuelles et a évalué les violations de règles sous des tests contradictoires (DeepMind Sparrow blog, Sparrow paper). Pour les programmes en production, connectez cela tôt à l’évaluation LLM : l’ensemble d’évaluation doit contenir des exemples que le modèle manque encore, et pas seulement des exemples qui prouvent que le pilote a fonctionné.
La gouvernance fait partie du périmètre lorsque le système est à haut risque ou destiné à la production. L’AI RMF et le GenAI Profile du NIST sont des références opérationnelles utiles pour documenter les risques, les méthodes de mesure et l’utilisation des retours ; la loi sur l’IA de l’UE exige des pratiques de gouvernance telles que la documentation technique, la journalisation, la supervision humaine et la robustesse pour les systèmes d’IA à haut risque (NIST AI RMF 1.0, NIST GenAI Profile, EU AI Act overview). Ceci ne constitue pas un avis juridique. Il s’agit d’un rappel de cadrage : si le pipeline RLHF alimente un flux de travail à haut risque, la documentation commence dès la première semaine.
Que doit laisser le premier programme ?
Un bon premier programme RLHF laisse trois actifs réutilisables :
- Une grille d’évaluation qui a intégré des arbitrages répétés.
- Un ensemble d’évaluation avec des exemples que le modèle manque encore.
- Un modèle de capacité des évaluateurs que l’équipe peut exécuter chaque semaine sans avoir à réapprendre les opérations.
Si ces artefacts existent, la définition du périmètre du prochain programme devient moins chère. S’ils n’existent pas, l’équipe a acheté des annotations mais n’a pas acheté de système d’exploitation.
Prochaines étapes
Références
- OpenAI — Apprentissage à partir des préférences humaines
- Entraînement de modèles de langage pour suivre des instructions avec des retours humains
- Apprendre à résumer à partir de retours humains
- Fiche du jeu de données Anthropic HH-RLHF
- Entraîner un assistant utile et inoffensif avec RLHF
- Sparrow : Améliorer l’alignement des agents de dialogue via des jugements humains ciblés
- DeepMind — Créer des agents de dialogue plus sûrs
- Vérifions étape par étape
- RewardBench
- NIST AI RMF 1.0
- Profil d’IA générative du NIST
- Aperçu du règlement sur l’IA de l’UE
- Tarification de OpenTrain